Wide&Deep
Advantage: 记忆和泛化能力的高度结合。 Key word: DNN, Generalization, Regressor Usage: 用于推荐,结合线性模型的记忆能力,和不需要做出很好的特征工程就能拥有强大泛化能力的DNN模型,来达到更加精准的预测效果
Motivation
Categorial data using one-hot encoding representation could memorize a feature pair that correlates with the target label. But this requires feature engineering.
DNNs could learn low-dimensional data without feature engineering. It is embedding-based model.
System Overview
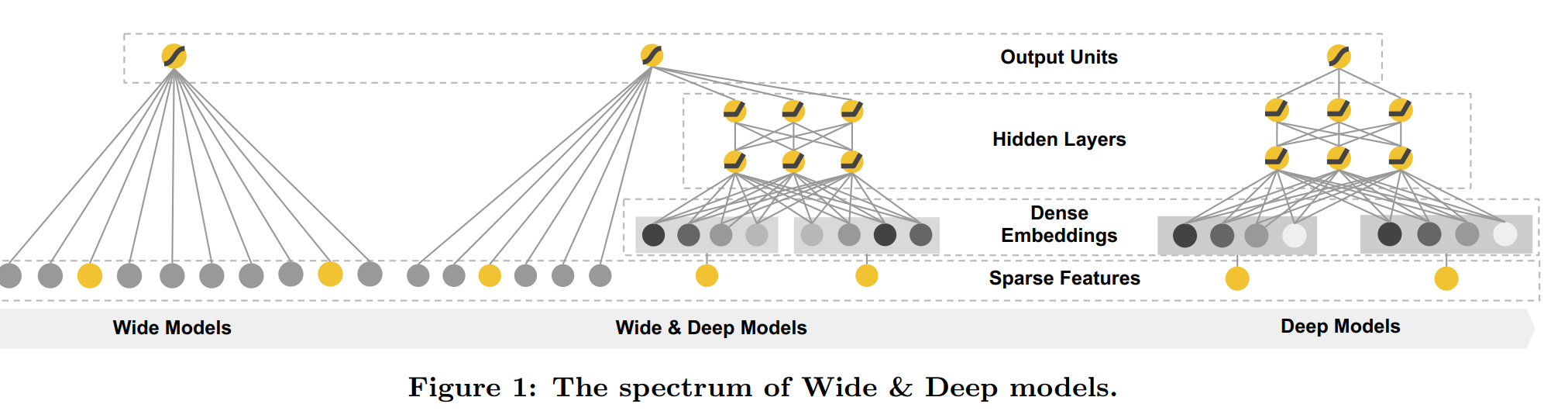
Wide component
Wide component is a linear regression model of engineered features. The input feature set includes raw features and transformed features.
Deep component
It is a feed forward deep neural network. For categorial features, they are feature strings. These are converted into an embedding vector first. The embedding vectors are initialized randomly and are trained to minimize the loss function.
Joint optimization
It uses weighted sum to connect the two components together.
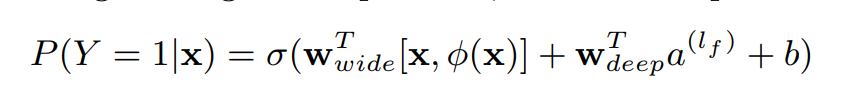
It uses BP and SGD to update weights in both function.