Encoder-Decoder Transformer
关于Transformer的三种架构的区别,可移步什么是Encoder-only Transformer这篇文章。
本文主要讲Encoder-Decoder Transformer结构,其原始论文是最经典的Attention is all you need.
-
模型介绍
-
Encoding:文本输入会把文本Encode成一种数字形式,也就是Tokenization,比如asynchronous会被encode成数字28,GPT使用的是BPE encoding方法,这个不赘述,感兴趣的话我可以后面再出一篇文章。
-
b. Encoder-decoder:Input就是src Sequence,中间经过Embedding,Positional Encoding后,形成一个固定长度的表征,再用Decoder对这个表征进行解码
-
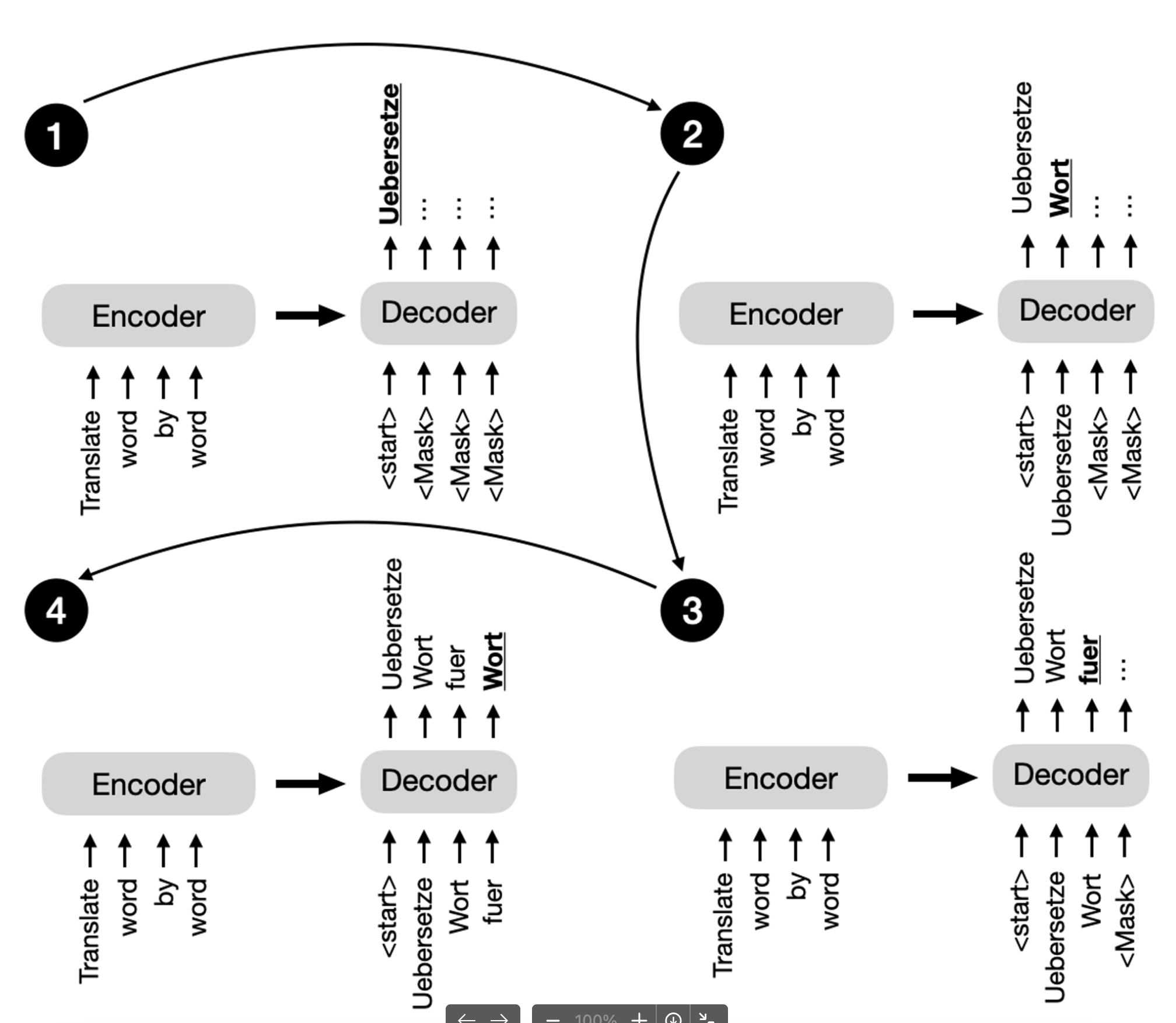
mask是什么,为什么要用mask?mask实际上是自回归模型的精髓,参考下图,在生成过程中,需要把Decoder全部掩盖起来,每次生成了一个Token后,把当前Token的mask拿掉,这样在下一次生成的时候,Encoder会使用未mask的所有作为Input。
-
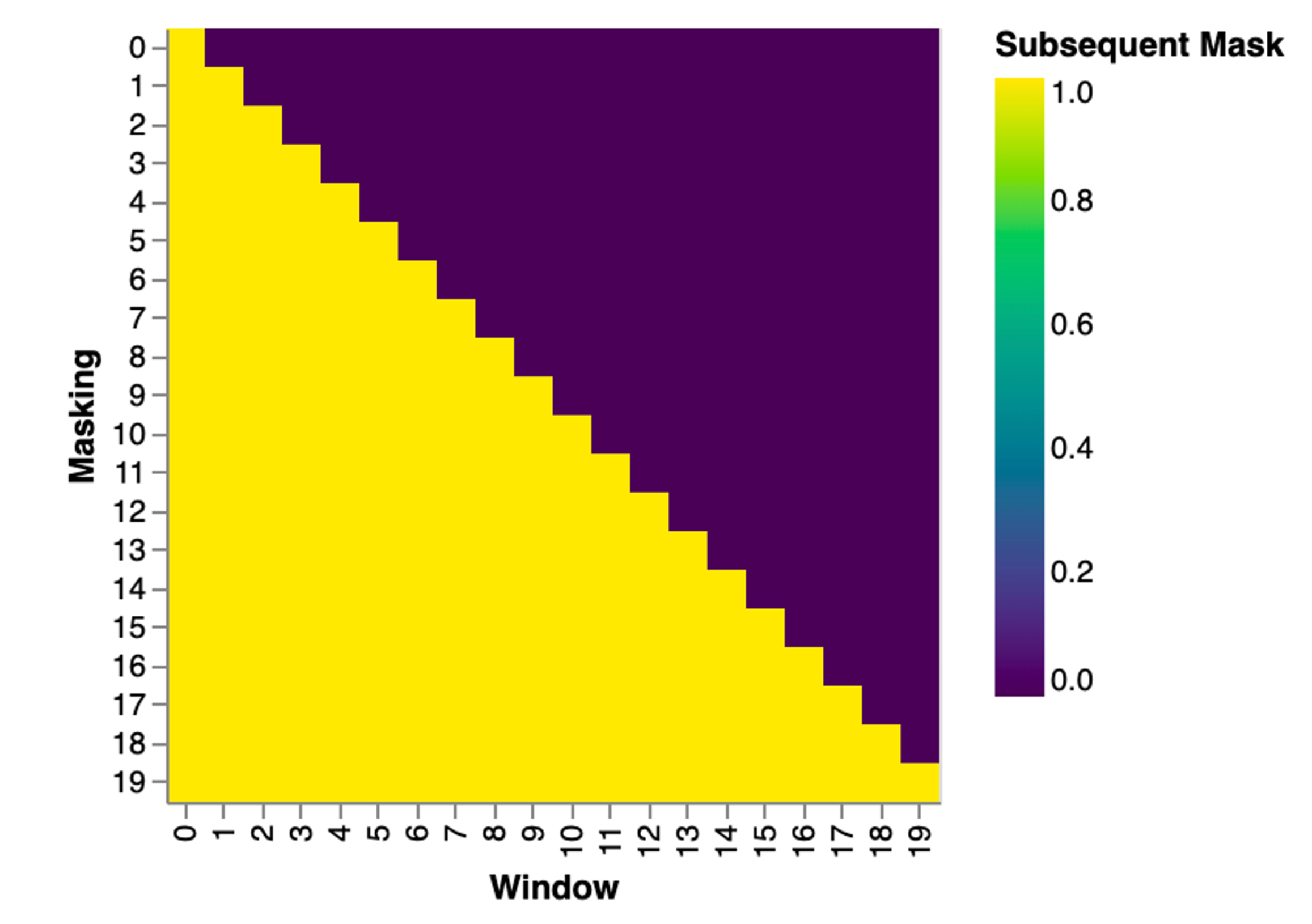
Mask的大小参考下图,当window的长度为1的时候,模型只能“看见”第一个位置的Input,其他位置的都被mask起来了。
-
生成结果:一次生成其实得到的是整个语料库中,当前句子下一个单词的概率分布,我们可以从这个概率分布中sample一个Token出来;
class Generator(nn.Module): "Define standard linear + softmax generation step." def __init__(self, d_model, vocab): super(Generator, self).__init__() self.proj = nn.Linear(d_model, vocab) def forward(self, x): return log_softmax(self.proj(x), dim=-1) -
Attention模块,如何理解Attention?其本质是,我想找到理解一个问题的关键词。比如“如何理解Encoder-Decoder Transformer?”关键词是Encoder-Decoder Transformer,后面的生成文本就应该主要参考这个关键词给出回答。 图里面的QKV指代的是Query,key,Value,我们把这个想象成一个信息提取系统,先用Q和K的矩阵相乘找到最相关的关键词,再把关键词对应的信息提取出来。
def attention(query, key, value, mask=None, dropout=None): "Compute 'Scaled Dot Product Attention'" d_k = query.size(-1) scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k) if mask is not None: scores = scores.masked_fill(mask == 0, -1e9) p_attn = scores.softmax(dim=-1) if dropout is not None: p_attn = dropout(p_attn) return torch.matmul(p_attn, value), p_attn -
Embedding,把Input映射到一个Embedding
class Embeddings(nn.Module): def __init__(self, d_model, vocab): super(Embeddings, self).__init__() self.lut = nn.Embedding(vocab, d_model) self.d_model = d_model def forward(self, x): return self.lut(x) * math.sqrt(self.d_model) -
Positional encoding: 为什么需要加这个,因为纯Embedding是无法感知句子中的单词顺序的,需要在Embedding的基础上,加上一个对Token位置编码后的Vector,具体原理不赘述了。
-

总结:我们把所有的模块合并起来,就是一个完整的Model
def make_model(
src_vocab, tgt_vocab, N=6, d_model=512, d_ff=2048, h=8, dropout=0.1
):
"Helper: Construct a model from hyperparameters."
c = copy.deepcopy
attn = MultiHeadedAttention(h, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
position = PositionalEncoding(d_model, dropout)
model = EncoderDecoder(
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N),
Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout), N),
nn.Sequential(Embeddings(d_model, src_vocab), c(position)),
nn.Sequential(Embeddings(d_model, tgt_vocab), c(position)),
Generator(d_model, tgt_vocab),
)
# This was important from their code.
# Initialize parameters with Glorot / fan_avg.
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
return model
下期跟大家讲一下如何对Encoder-Decoder框架的模型训练和评估。感兴趣的小伙伴可以关注一下,我们下期再见。