还在纠结这些名词之间的区别吗?给你讲清楚
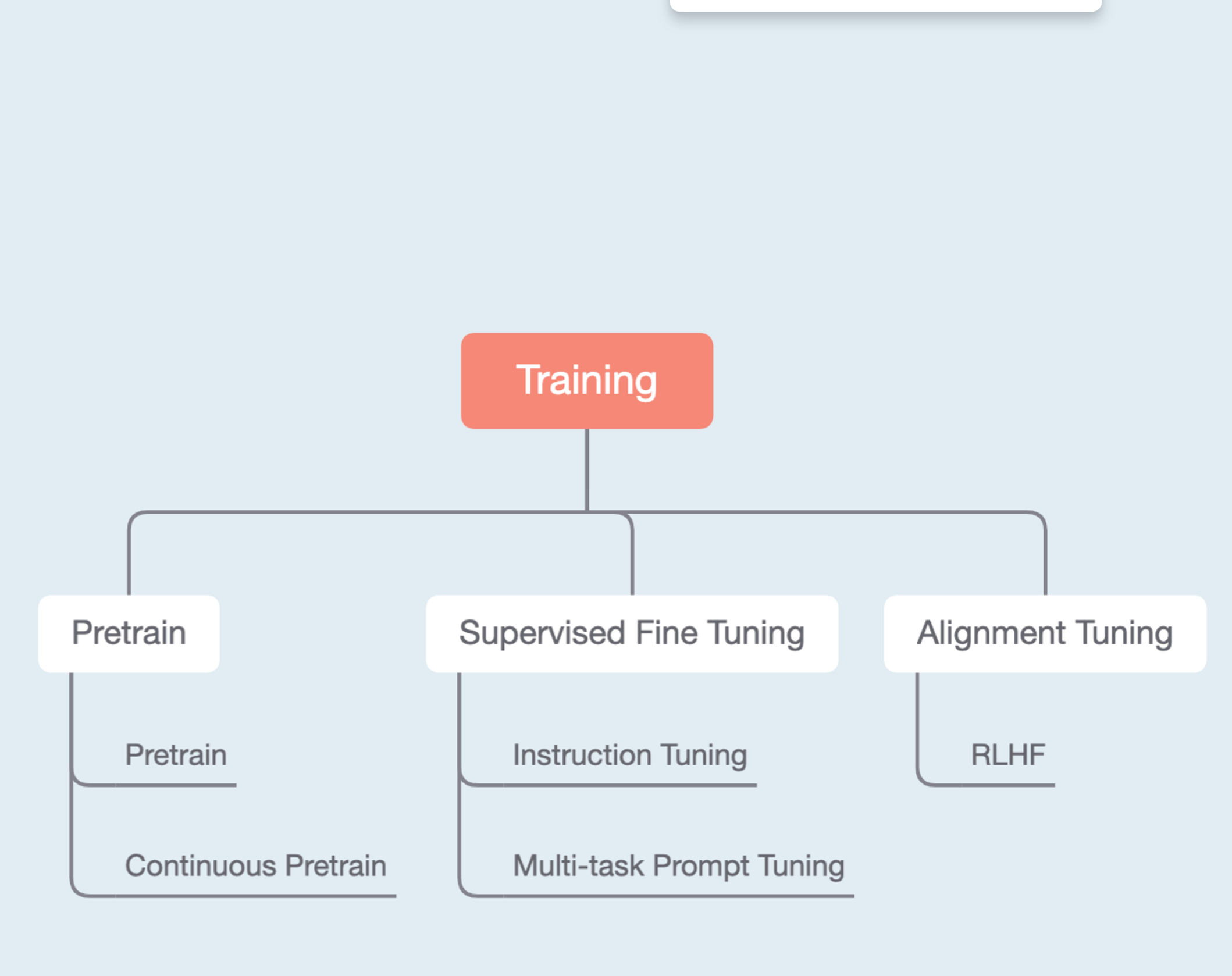
TLDR:主要差别在于训练数据的构造。
- Pretrain
- 无监督的,就纯用语料库来训练,比如webtext,Wikipedia等,预测下一个token的概率分布,并用cross-entropy loss作为loss Function来更新模型的参数;
- Continuous Pretrain:在一个已经训练好的预训练模型上,用一些数据来进一步加强模型的某些方面的能力,这也是无监督的,数据也没有经过特殊构造,就是原始文本输入进去。
- Fine-tune:这是比较大的名词,基本上所有在预训练模型上更新参数的方法都可以叫做Fine-tune。与此相关的名词基本上只有数据构造上的区别。
- Supervised Fine-tune:构造了专门的输入输出pair的,基于预训练模型的,都可以叫做SFT。一般来说,如果直接把现有NLP任务的数据不经过改造就直接用于大模型训练,叫做SFT。需要大量数据
- Instruction Tuning:构造了专门的自然语言指令跟随的输入和输出对。例如,原本的情感分析是给定一句话,直接输出高兴,难过,中性等;instruction Tuning是“请告诉这段话蕴含的情感”+输入的那句话:高兴,这样来构造数据。一般需要大量数据。

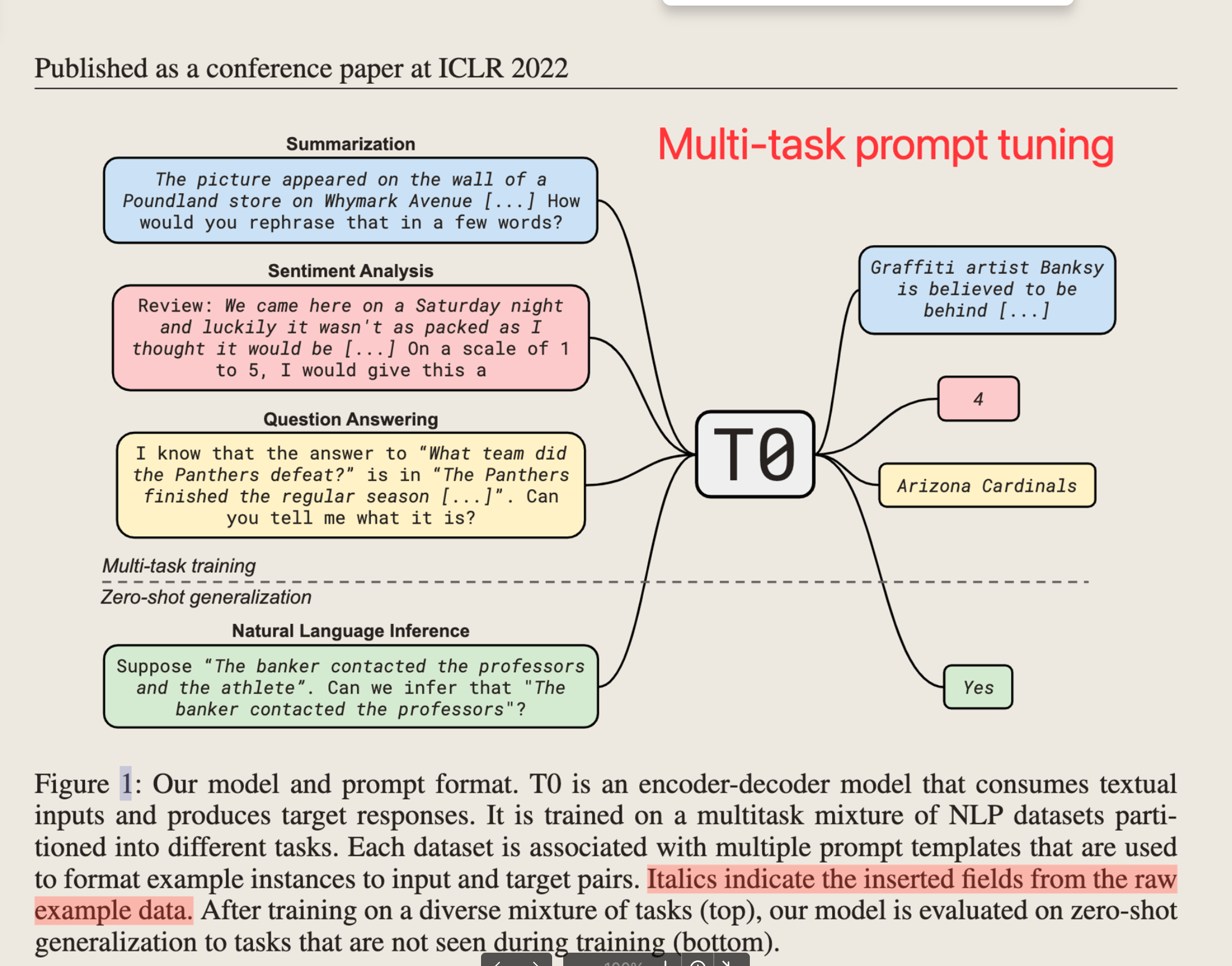
- Multi-task Prompt Tuning:把各种任务都构造成自然语言Prompt,只需要很少量数据训练,推理的时候如果和这个Prompt长得像,就可以激发这部分训练数据的能力。
- Alignment Tuning
- RLHF:一般来说需要人工标注Preference,使模型生成的结果对齐人类选择的过程,叫做RLHF。
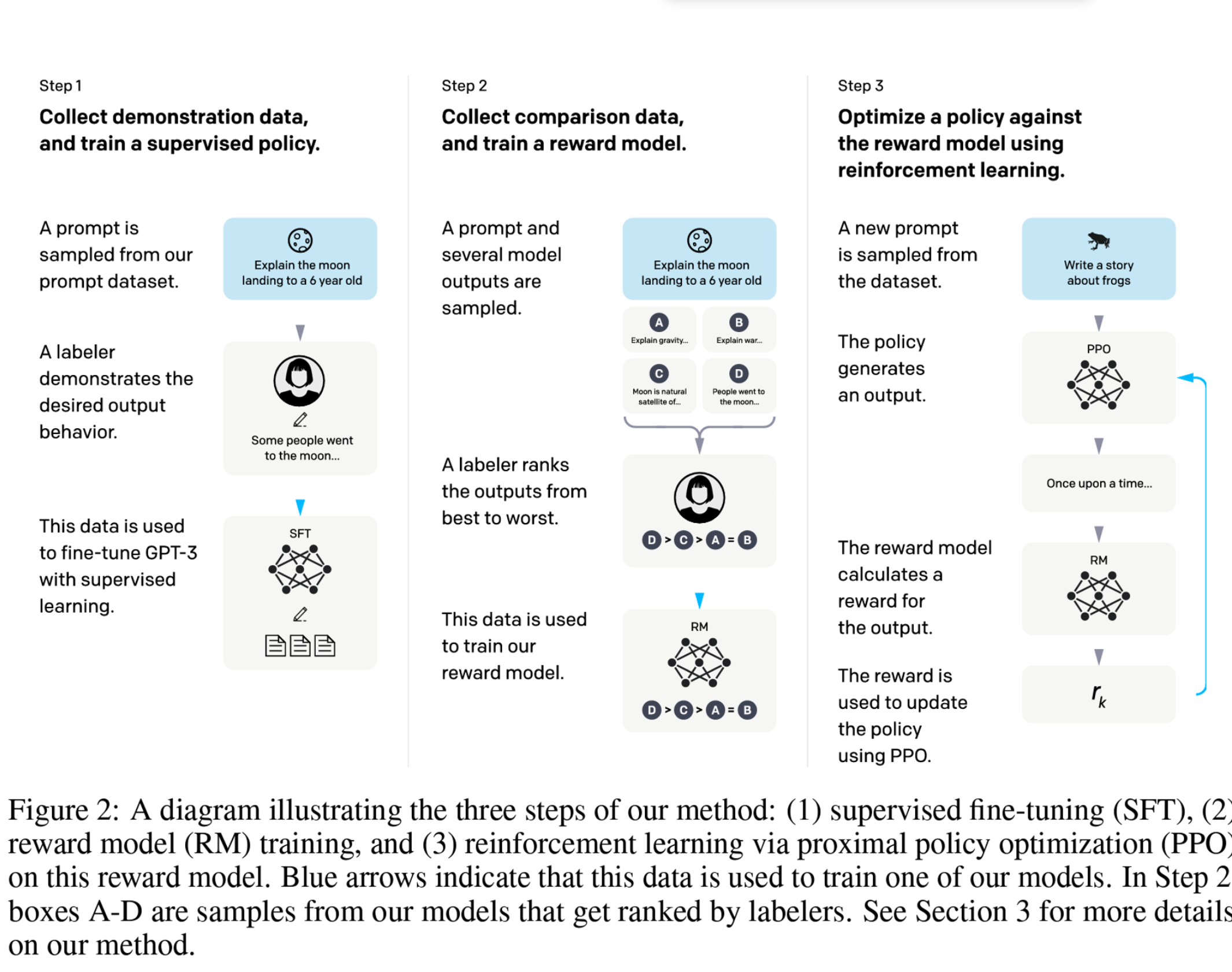
- RLHF:一般来说需要人工标注Preference,使模型生成的结果对齐人类选择的过程,叫做RLHF。
PREVIOUSAI算法