基于Transformer的大语言模型共有三种架构,分别是Encoder-only Model,Encoder-Decoder Model和Decoder-only Model。
三者的本质区别:大模型的输出是文本还是Embedding。后者需要改模型结构才能适配其他下游任务。
- Encoder-only: Input是Encoder Transformer,Output是Transformer结构的最后一层Hidden states,需要再加一层MLP才能适应到不同的下游任务。主要应用是训练高效的Embedding和各种文本分类问题。代表作:BERT。
- Encoder-Decoder:Input是语言,经过Transformer Encoder变成Embedding,再由Transformer Decoder解码Embedding转换回语言。代表作:FLAN-T5
- Decoder-only:用一个position Embedding layer替代Encoder,直接转化语言为Embedding,再用Transformer Decoder解码Embedding,输出语言,代表作:GPT。
今天我们先看Encoder-only的代表作BERT的架构。
-
模型架构
- multi-layer bidirectional Transformer encoder。
-
数据形式
- Input:用CLS开头,SEP分割前后的文本
- Output:用C开头的Hidden states
-
训练
-
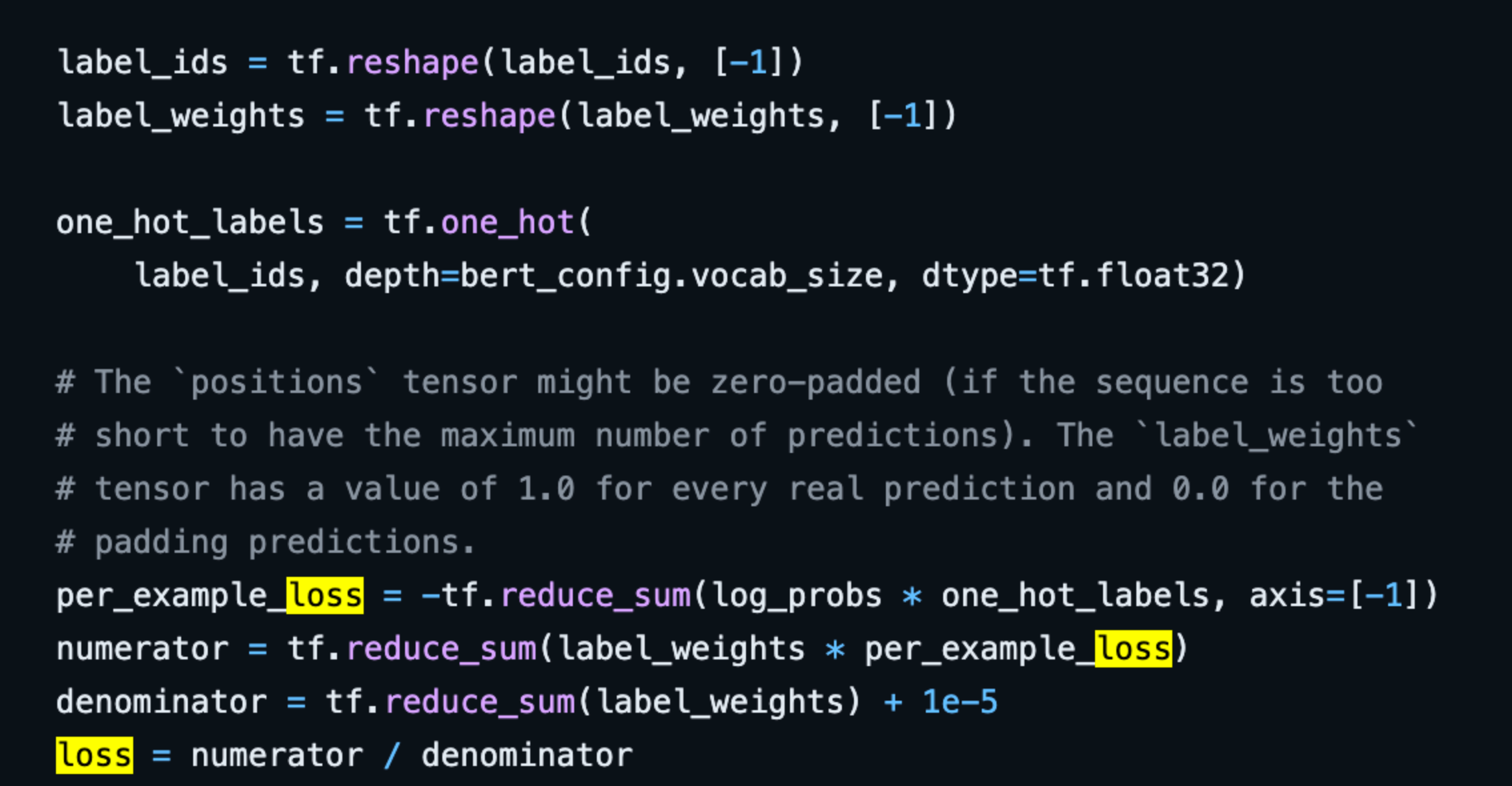
Pretrain,80%情况下随机mask第i个token,然后用cross entropy loss来预测这个token
-
train的时候用了one-hot来标记哪个log_prob是需要用来计算为cross entropy loss的
-
还有一个任务是Next sentence prediction,计算下一个句子的log_prob
-
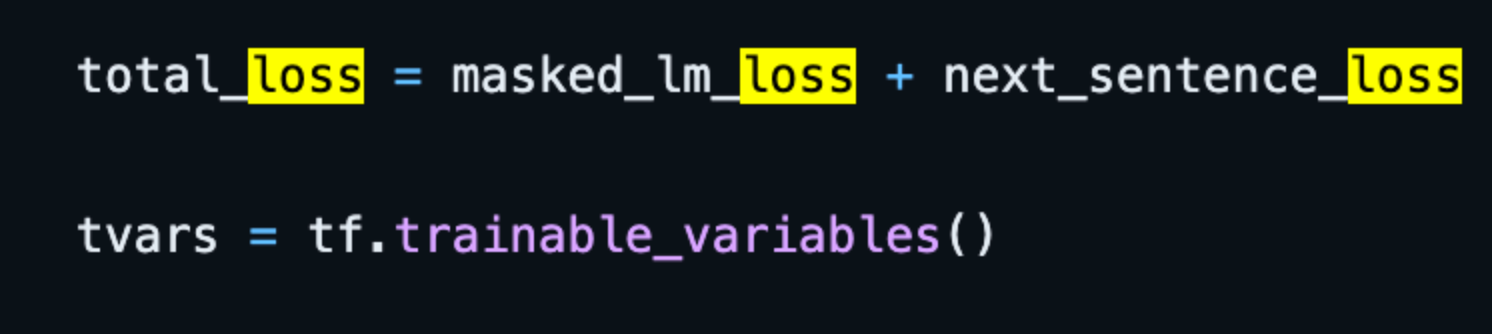
最后两个loss加起来了
-
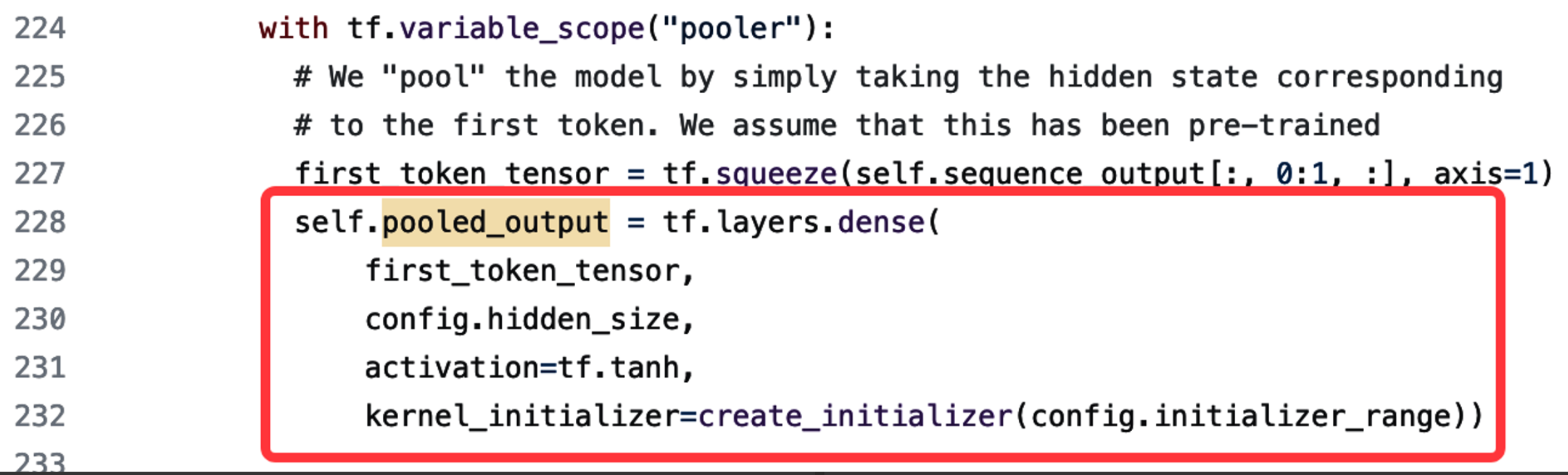
Fine-tune: 把transformer的最后一层layer转化成一个适配下游任务的layer,不转不行,所以这个叫Encoder-only的Network。这里是一个classifier的实例,这里把最后一层Hidden states转化成了一个dense layer。
-
总结一下,Encoder-only的结构必须改模型结构才能使用到下游任务上,必须fine-tune,成本较高。下期讲Encoder-Decoder结构的代表作。
PREVIOUSAI算法