Decoder-only Transformer
Decoder-only的Transformer网络结构式2017年GPT系列的第一篇文章带火的。Decoder-only最大的特点是,我称之为打直球,即直接针对Input预测下一个Token的概率分布,从概率分布中sample一个Token,就直接给结果了,然后再进行下一次生成,也即Auto regressive。例如Input是,A quick brown fox,那么模型会给出下一个Token是j,在下次给出Token是u,循环N次知道生成结束Token [EOS],本次生成结束,你会得到A quick brown fox jumps over the lazy dog.[EOS]这样的输出。
下图的左边就是GPT系列的基础架构。
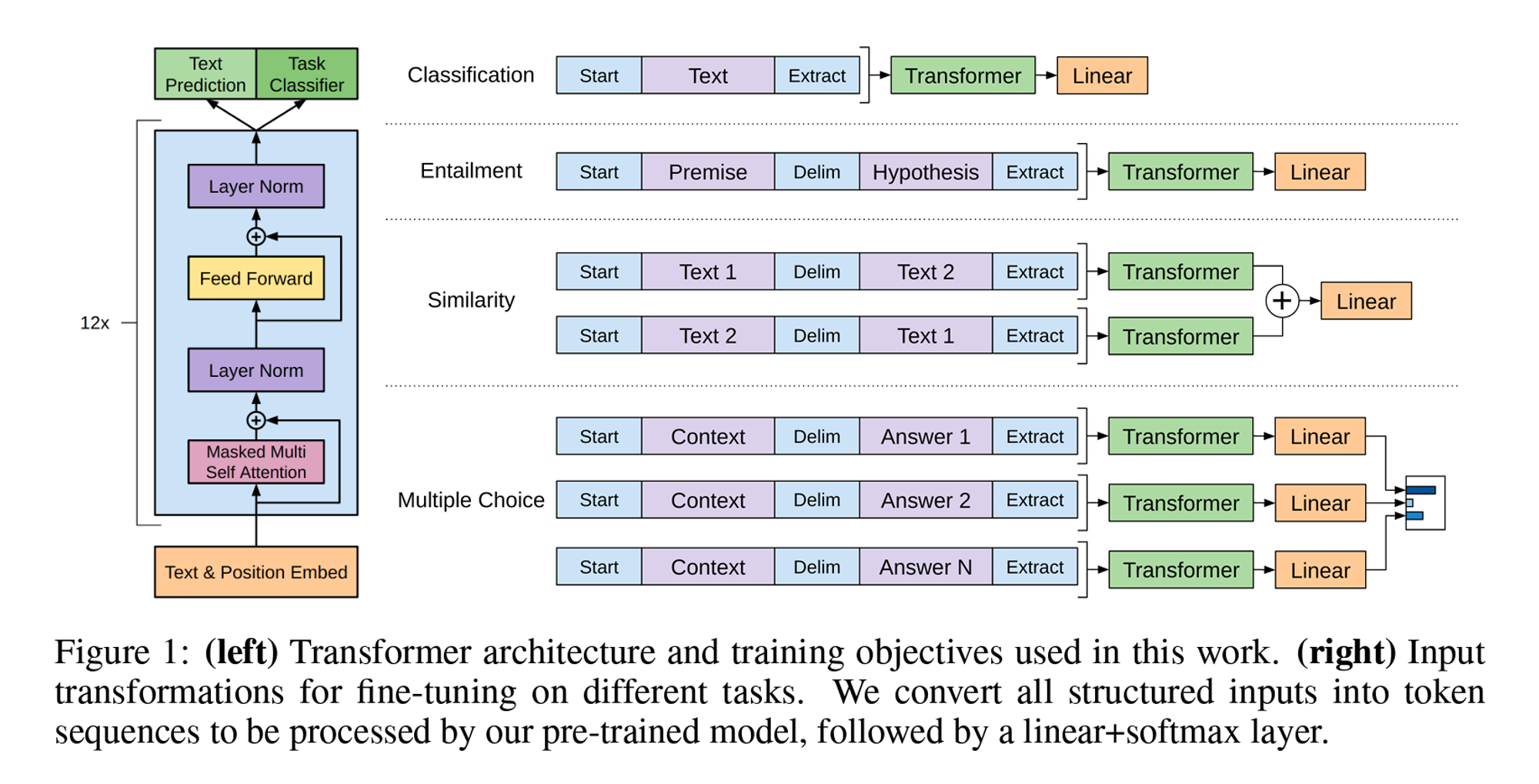
下面我们结合代码来看一下,代码仓库:karpathy/nanoGPT
def forward(self, idx, targets=None):
device = idx.device
b, t = idx.size()
assert t <= self.config.block_size, f"Cannot forward sequence of length {t}, block size is only {self.config.block_size}"
pos = torch.arange(0, t, dtype=torch.long, device=device) # shape (t)
# forward the GPT model itself
# 第一层,Text Embedding + Positional Embedding,用于Tokenize和感知不同Token之间的位置关系。
tok_emb = self.transformer.wte(idx) # token embeddings of shape (b, t, n_embd)
pos_emb = self.transformer.wpe(pos) # position embeddings of shape (t, n_embd)
# 对Positional Embedding用了一层Dropout,原因主要有两个,
# 第一防止过拟合,随机Drop掉一些Input中的units有助于学习到句式中更鲁棒的特征。
# 第二防止模型对位置信息的依赖过重,对自回归模型来说这点尤其重要,因为自回归未来的生成依赖于之前的生成
# 如果不加Dropout,当前面的Input一样时,后面可能永远不会有任何变化。
x = self.transformer.drop(tok_emb + pos_emb)
for block in self.transformer.h:
x = block(x)
x = self.transformer.ln_f(x)
# target非空时,表示这是训练状态
if targets is not None:
# if we are given some desired targets also calculate the loss
# 用于产出整个语料库Token的概率分布
# self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False)
logits = self.lm_head(x)
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1), ignore_index=-1)
else:
# inference-time mini-optimization: only forward the lm_head on the very last position
logits = self.lm_head(x[:, [-1], :]) # note: using list [-1] to preserve the time dim
loss = None
return logits, loss
结合一下Generate函数,我们来看一下temperature在部署模型推理时候的作用。假如我们把语料库的Token概率分布想象成一个正态分布曲线,由于temperature在分母位置,那么Temperature越大,则正态分布曲线越平滑,越小则越尖锐。所以在经过最后的Softmax层之后,概率越大的会被放大,被sample到的概率就会变大,因此越小的temperature,会让产出结果的确定性更强,更容易产出相同的结果。
@torch.no_grad()
def generate(self, idx, max_new_tokens, temperature=1.0, top_k=None):
"""
Take a conditioning sequence of indices idx (LongTensor of shape (b,t)) and complete
the sequence max_new_tokens times, feeding the predictions back into the model each time.
Most likely you'll want to make sure to be in model.eval() mode of operation for this.
"""
for _ in range(max_new_tokens):
# if the sequence context is growing too long we must crop it at block_size
idx_cond = idx if idx.size(1) <= self.config.block_size else idx[:, -self.config.block_size:]
# forward the model to get the logits for the index in the sequence
logits, _ = self(idx_cond)
# pluck the logits at the final step and scale by desired temperature
# 假如我们把语料库的Token概率分布想象成一个正态分布曲线,
# 由于temperature在分母位置,那么Temperature越大,则正态分布曲线越平滑,越小则越尖锐。
logits = logits[:, -1, :] / temperature
# optionally crop the logits to only the top k options
if top_k is not None:
v, _ = torch.topk(logits, min(top_k, logits.size(-1)))
logits[logits < v[:, [-1]]] = -float('Inf')
# apply softmax to convert logits to (normalized) probabilities
# 所以在经过最后的Softmax层之后,概率越大的会被放大,被sample到的概率就会变大,
# 因此越小的temperature,会让产出结果的确定性更强,更容易产出相同的结果。
probs = F.softmax(logits, dim=-1)
# sample from the distribution
idx_next = torch.multinomial(probs, num_samples=1)
# append sampled index to the running sequence and continue
idx = torch.cat((idx, idx_next), dim=1)
return idx
Decoder-only的知识点你掌握了吗?欢迎在评论区留言告诉我你还有哪里没懂,想了解哪些知识。下一期我们挖个新坑,讲一讲多模态大模型的相关知识。
PREVIOUSAI算法