大模型21:多模态大模型
分类图
https://whimsical.com/mlm-8adiZwwDifpxwNxz4qFPKZ
Timeline
| 分类 | 模型 | 时间 | 团队 | Summary |
|---|---|---|---|---|
| language<>image pretrain | CLIP | 202103 | OpenAI | |
| VLP pretrain | Flamingo | 202204 | DeepMind | |
| vision-lang pretrain | BLIP-2 | 202302 | Salesforce | |
| vision-lang instruction tuning | InstructBLIP | 202305 | Salesforce | |
| VLP + SFT + 长图文写作 | Internlm-xcomposer | 202309 | PJLab 上海人工智能实验室 | |
| Pretrain + SFT | InternLM-xcomposer2 | 202401 | PJLab上海人工智能实验室 | |
| Instruction tuning | LLaVA | 202304 | Microsoft Research |
Models
CLIP - OpenAI - 2021
-
Initiative 在Text领域,pre-train模型可以在不改变任何模型结构,通过prompting的方式泛化到下游任务,Image领域是否能有这样的模型?
-
当前进展
- NLP领域,只用webtext做训练,不用labelled数据集就能实现上面的目标,Image领域呢?
- 原来有类似的工作,但是他们学习到的Image representation是在一些有label的数据集上,而这些label是非常少的;
- 所以一个新的想法是,能否找到更大量的数据集上预训练一个能学习到representation的?
- 这样的数据集,网络上有很多图,这些图是有文字描述的,是否能用这样的文字作为Image representation的监督信号呢?
- 所以,CLIP的核心假设就是,文字能够作为Image perception的一个监督信号,指导模型学习到图片的perception
-
如何做
- 用文字作为supervision的方法有很多,比如n-gram和topic models,但是用transfomers这种架构的深度网络作为image 网络的监督信号网络的方法还是未经尝试。
-
数据如何组织
- 之前的一些数据集太脏了,过滤后仅剩下15m。所以我们组织了400m的数据集叫做webImageText
-
如何训练
- 训练的主要难点在于数据量太大,如果直接把CNN和一个Text Transformer在一起从头训练,在63m大小的transformer上都比ResNet-50的image encoder慢太多了
- 之前用的方法,预测bag-of-words的和transformer-based,都是为了预测正确每一个和Text最相近的单词,说白了都是分类问题,这个最大的问题是丢失了context,且vocab非常的sparse,非常难训练
- 所以他们用了contrastive的objective,这样可以解决不好训练和训练慢的问题
-
如何建模
- 两个实验,使用加了attention pooling的ResNet和Vision Transformer作为Vision Encoder
- Text的使用63M的Transformer,只用了76的Sequence length
-
实验
- Image classification领域的zero-shot transfer learning指代的是能够正确把图片归类到之前没有训练过的类别
- 这篇文章主要学习zero-shot的transfer learning
- 实验结果表明,这个Pretrain的方法,在没有用过任何classification的labelling的情况下,比Visual n-grams好了太多
- Prompt engineering: 这里指的主要是文本的prompt,比如a photo a cat要比直接用cat作为caption好很多;另外,词语的多义性也直接导致了语言模型confuse的程度增加;另外,用加上任务相关的信息能大大提升性能,例如把{label}改成a photo of {}, a type of pet能提升宠物类的benchmark
- 尝试用不同的prompt来提升任务的整体质量
-
实验结果
-
在大部分benchmark上都显著好于ImageNet50的方案,但是在专业数据集上表现较差。作者说了有很大提升空间,但是同时质疑评估的数据集,因为即使tumor Classiication对于没学习过类似知识的人类来说都是不能完成的。
-
zero-shot的性能有好有坏,下游任务如果要用这个更好的任务做fine-tune,能否好过现在SOTA模型呢?更进一步说,representation learning到底到位了没有?Fine-tune完之后在21/27个任务上都取得了sota的结果
-
fine-tune之后到底对其他任务的影响有多大?这个叫做Natural distribution shift robustness。作者提出了疑问,到底是不是在ImageNet的数据集上做训练,导致了robustness gap。因此作者做了一个实验,就是在ImageNet上做fine-tune,然后再Evaluate其他的结果。最后发现tune完之后在其他任务上基本没什么shift。这有可能是预训练数据集很大导致的,也可能是用语言作为监督信号导致的,不过这个训练的方法是通过一个
L2 regularized logistic regression classifier来做的,并没有整体更新CLIP的权重,所以这个结果有点tricky,没在一个层面上比较。
-
-
limitations
- 在很多任务上zero-shot和SOTA相差很远
- 在手写字体识别上,CLIP很容易就输给了简单的deep分类模型,这也有可能说明CLIP并没有解决深度网络的泛化问题,只是通过海量的训练数据保证了大部分任务是in-distribution的
BLIP-2
-
Contribution
-
Generic compute-efficient的Vision Language Pretrain模型
-
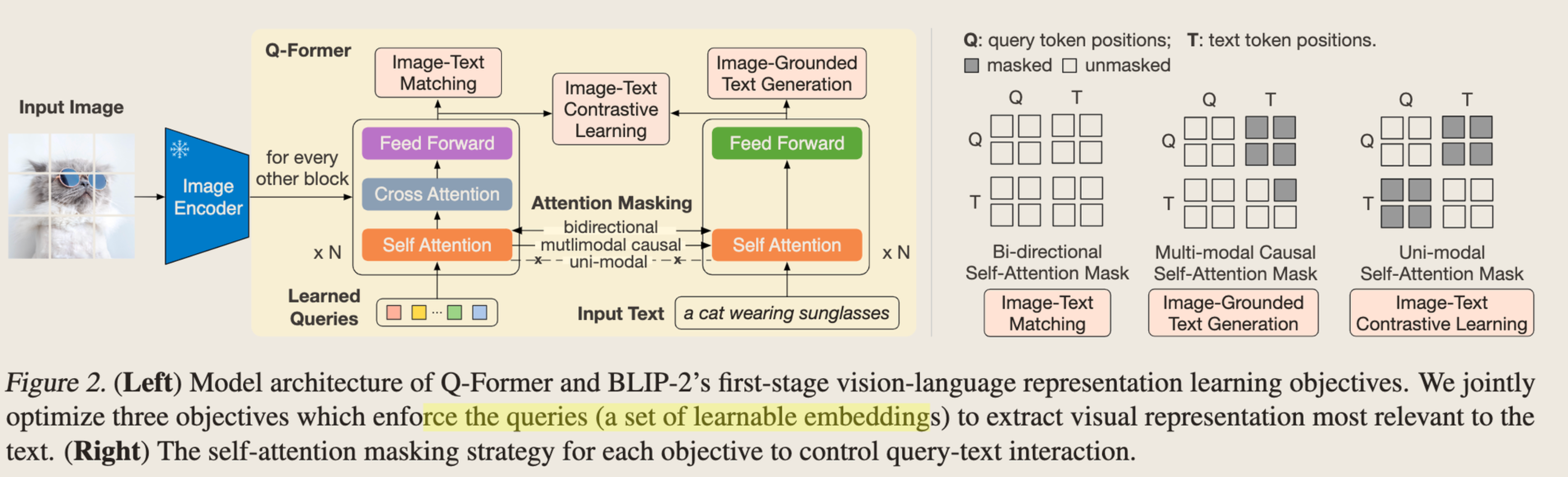
Design一个Q-Former(一个轻量级的Transformer对齐Vision和Text)
-
设计了一个两阶段的训练过程,第一个阶段做vision-languange representation learning,第二阶段Boost LLM的对Image的生成能力。这两个阶段都是只训练Q-former,但是两阶段的目标不同。
-
-
具体方法
- Image representation也是学习了CLIP,用in-batch negtives做Contrastive learning
- 用Image作为Text Generation的condition,用了一些trick,这里用了MultiModal causal self-attention mask,保证每次都能attend到前面所有的Token。
- Image Text Matching,通过一个二分类器来预测一个Image和Text pair是否是正例的方式,再次align Image和Text的representation
-
训练 - 两阶段训练都更新相同的parameters,但是通过不同的Attention mask实现不同目标的学习。
-
一阶段:目标是把Vision Encoder的representation align到Language的space中,Query相当于是Vision的embedding,Output是Text的embedding,这个阶段要分别学习三个loss。为什么要这样做?
-
一阶段的loss https://github.com/salesforce/LAVIS/blob/main/lavis/models/blip2_models/blip2_qformer.py 参考这个里面的三个loss,
-
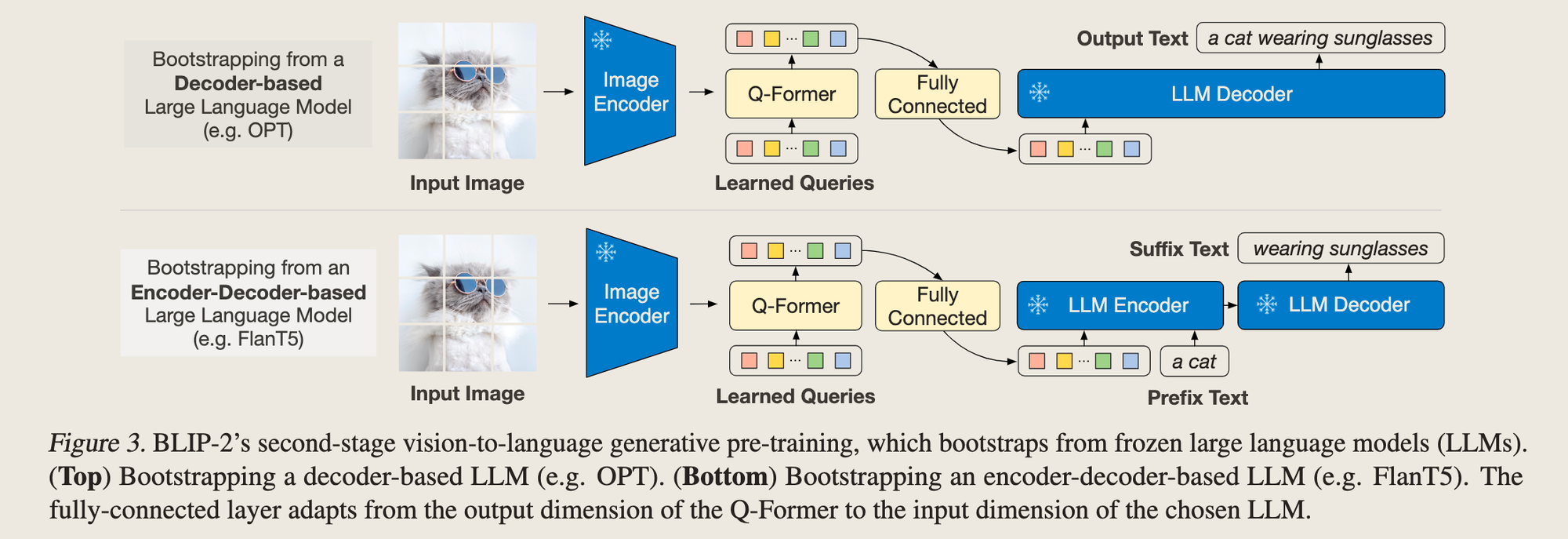
二阶段:Generative pretraining,用一层LC把Q-Former的embedding接到LLM上,这一步的learnable params是什么?Q-former + LC层,用Language modelling loss……有点疑问,什么叫Language modelling loss和prefix Language modelling loss?
-
第二阶段,以t5举例,直接复用了t5 forward时的loss作为第二阶段的loss
outputs = self.t5_model( inputs_embeds=inputs_embeds, attention_mask=encoder_atts, decoder_attention_mask=output_tokens.attention_mask, return_dict=True, labels=targets, ) loss = outputs.loss
-
BLIP-2 InstructBLIP
-
总结:一个基于BLIP-2的instruction tuning的版本,能够针对用户的多轮交互做问答,原来BLIP-2的训练数据,基本上只有一个问题和回答,说自己的novelty是instruction-aware的BLIP,实际上就是把原来放Image caption的地方改成了instruction,并基于原来BLIP-2的ckpt继续训练的版本。最主要的贡献还是构造了26个数据集 + Data mix时的数据balance手法。
-
code:https://github.com/salesforce/LAVIS/tree/main/lavis/models/blip2_models
-
Contribution
- 构造了26个Visual instruction tuning的数据集,13个训练,13个held-out
- 提出了Q-former,能够更高效的根据instruction的上下文提取图片特征
- LLM用了FLAN T5,Vicuna和LLaMA
-
数据构造
- trick 1:对于回答特别简短的,instruction里面加了briefly这个
-
visual feature extraction
-
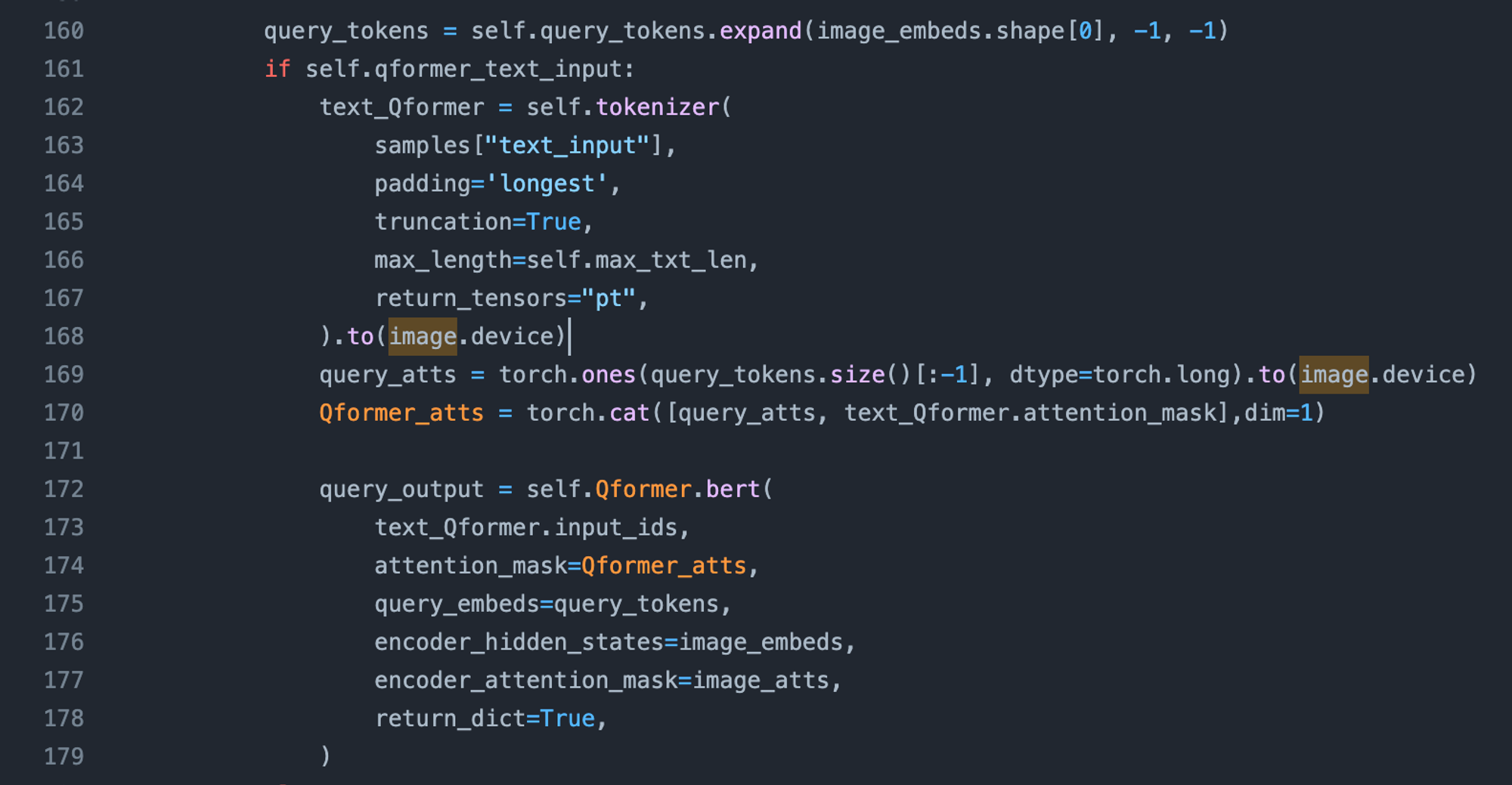
之前的方案,Image feature不会根据instruction的变化而改变,作者认为这是个改进点,需要Visual Embedding根据不同任务的instruction而产生改变
-
改进的方案,把instruction和queries一起放到Q-Former的Input里面,主要code在这里
-
-
Training
-
用预训练好的BLIP-2作为基座,只训练Q-Former,对于其不包含的Vicuna基座的LLM,又做了BLIP-2和Vicuna的pretrain
-
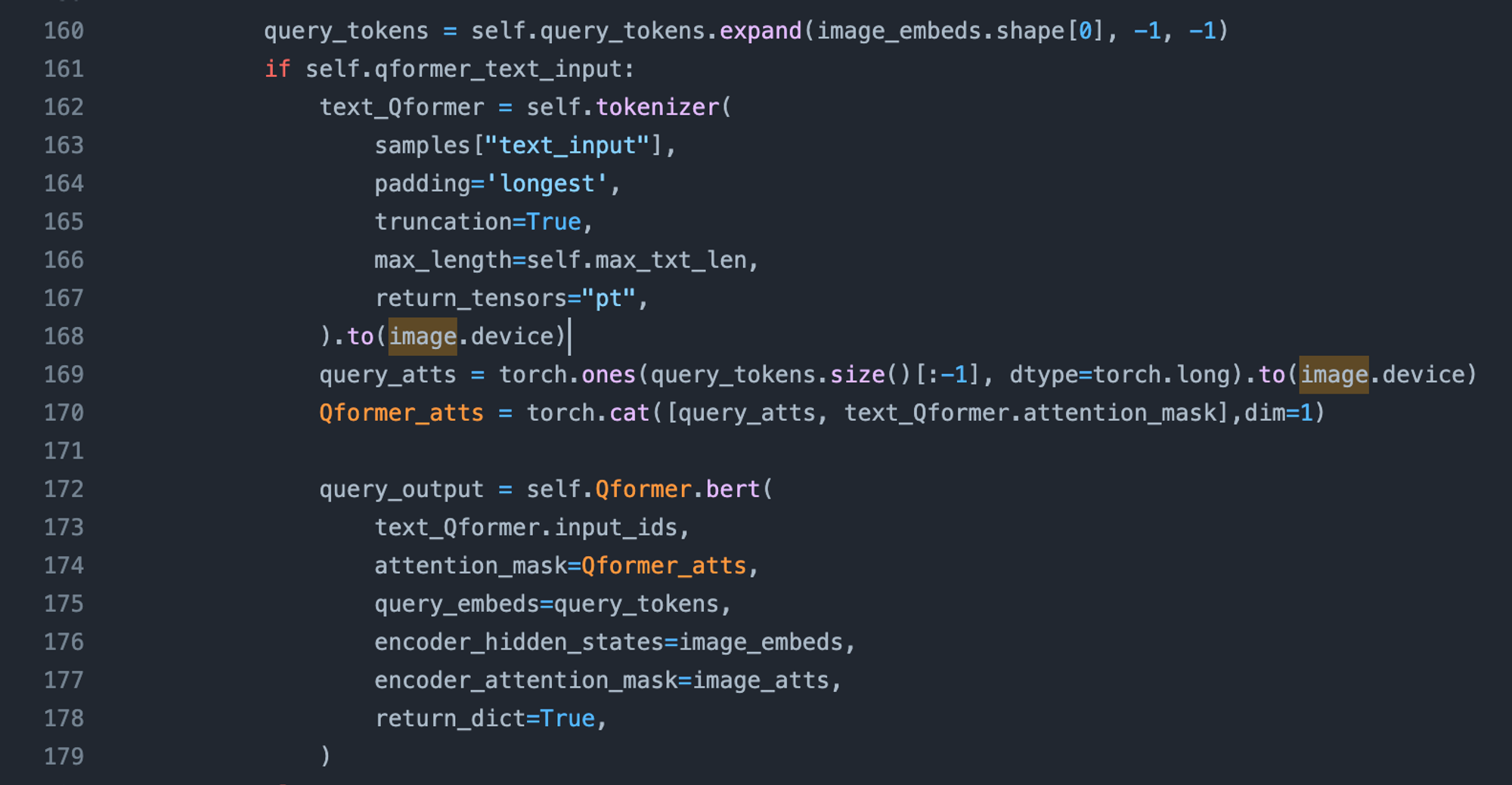
超参:
-
Internlm-xcomposer
-
整体架构

-
当前存在的问题及解决手法
- 当前其他模型在长篇文章生成、图文生成中存在缺陷 - 我们用CLIP取出最相关的图片,并放到生成的结果中;
- 图像理解能力有待提升 - 我们使用了海量训练数据来弥补实际问题上out-distribution的情况。
-
模型架构
- Vision-encoder: EVA-CLIP
- Perceived Sampler:
完全复用了BLIP-2的Q-Former,虽然叫做Q-former,但是没有复用BLIP的Q-former。 - LLM - Internlm-chat-7B
-
训练方法 - Pretrain + SFT
-
Pretrain - public + in-house数据,会同时训练LM + Q-former
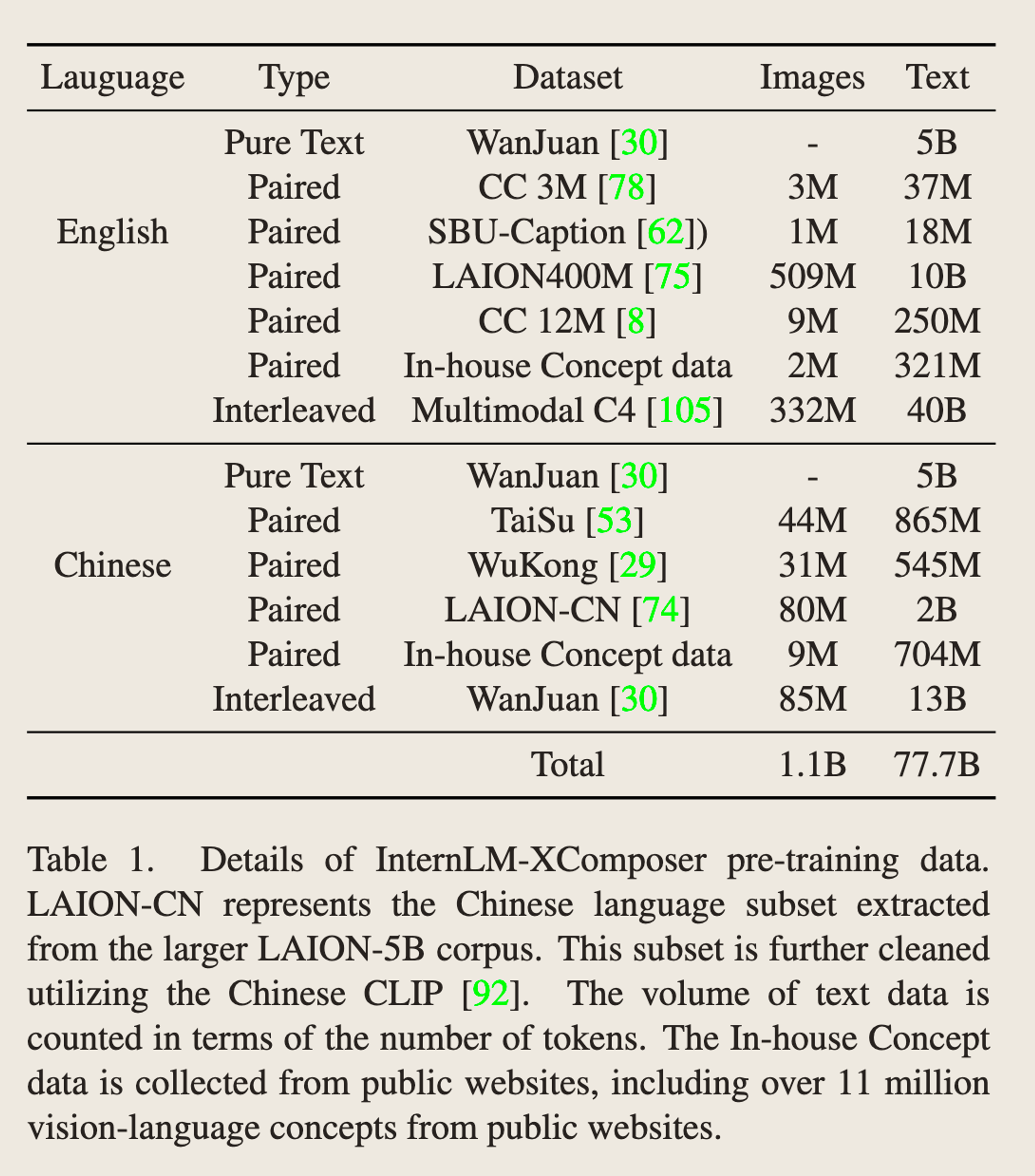
-
SFT - 其实就是instruction tuning。同时训练Q-former和LLM的LoRA
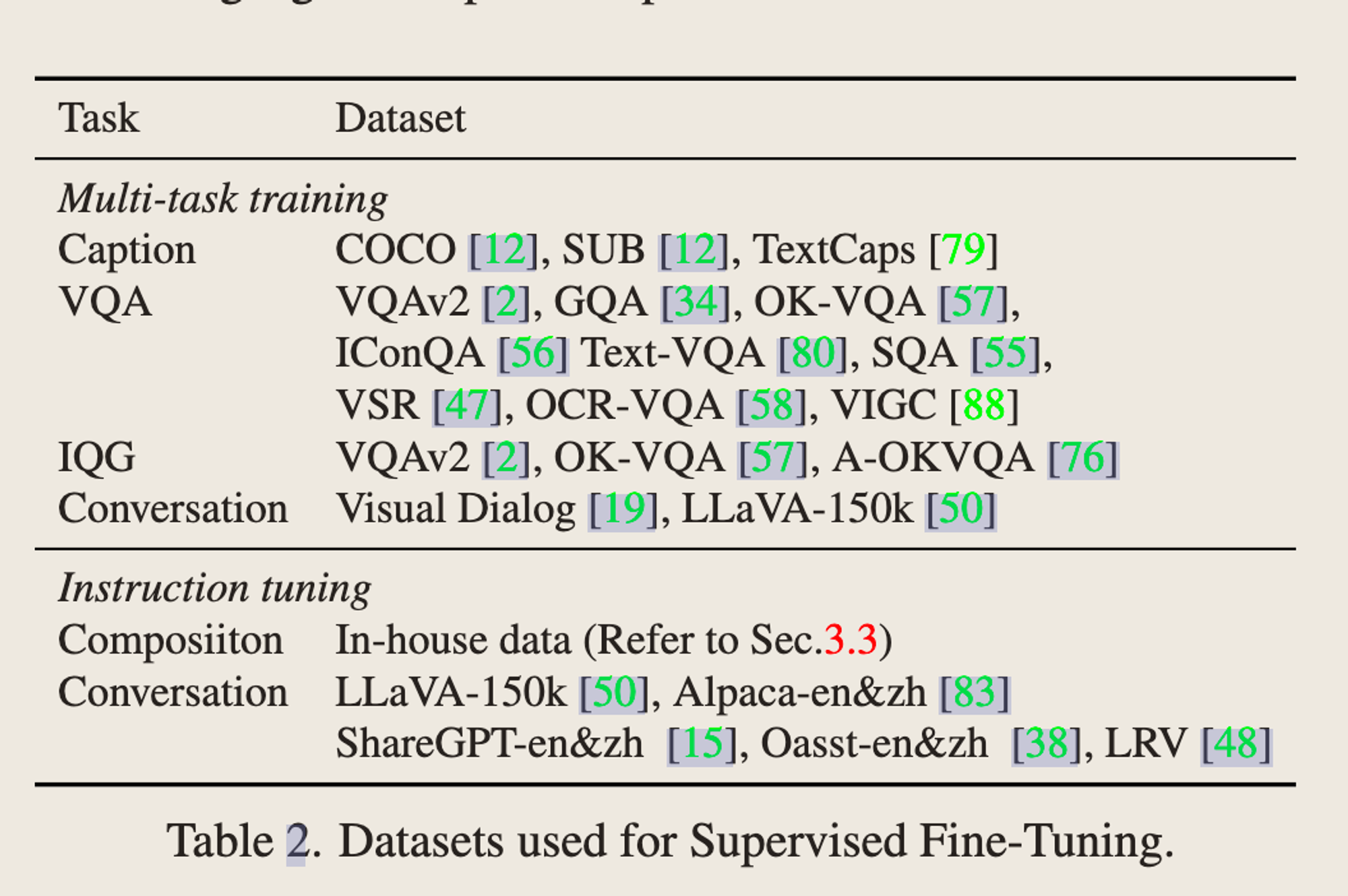
-
Question:为什么第一步不用LoRA,第二步做的时候用LoRA?为了训练stability和efficiency?感觉有点说不通,不用又会怎样?
-
-
评估
Internlm-xcomposer2
-
目标:提升VLM的理解能力;提升图文混合类的创作能力。
-
Gap:现有模态对齐方法的问题,他们认为,以前的模态对齐任务,
- 要不然认为Image Token和Language Token是等价的,
- 要不然认为两个模态是独立的个体。
- 这两个方法,前者作者认为有忽略了两者对结果的实际影响,后者作者认为有很大的对齐成本。
-
方法:提出了PLoRA的方法,用PLoRA替代了以前的Q-former。这个PLoRA只attend Visual tokens。把LLM的每一层的LoRA拿出来,组成一个Partial LoRA,并将其作为Visual Token的processor,Output feature就直接把这两个拼接起来。
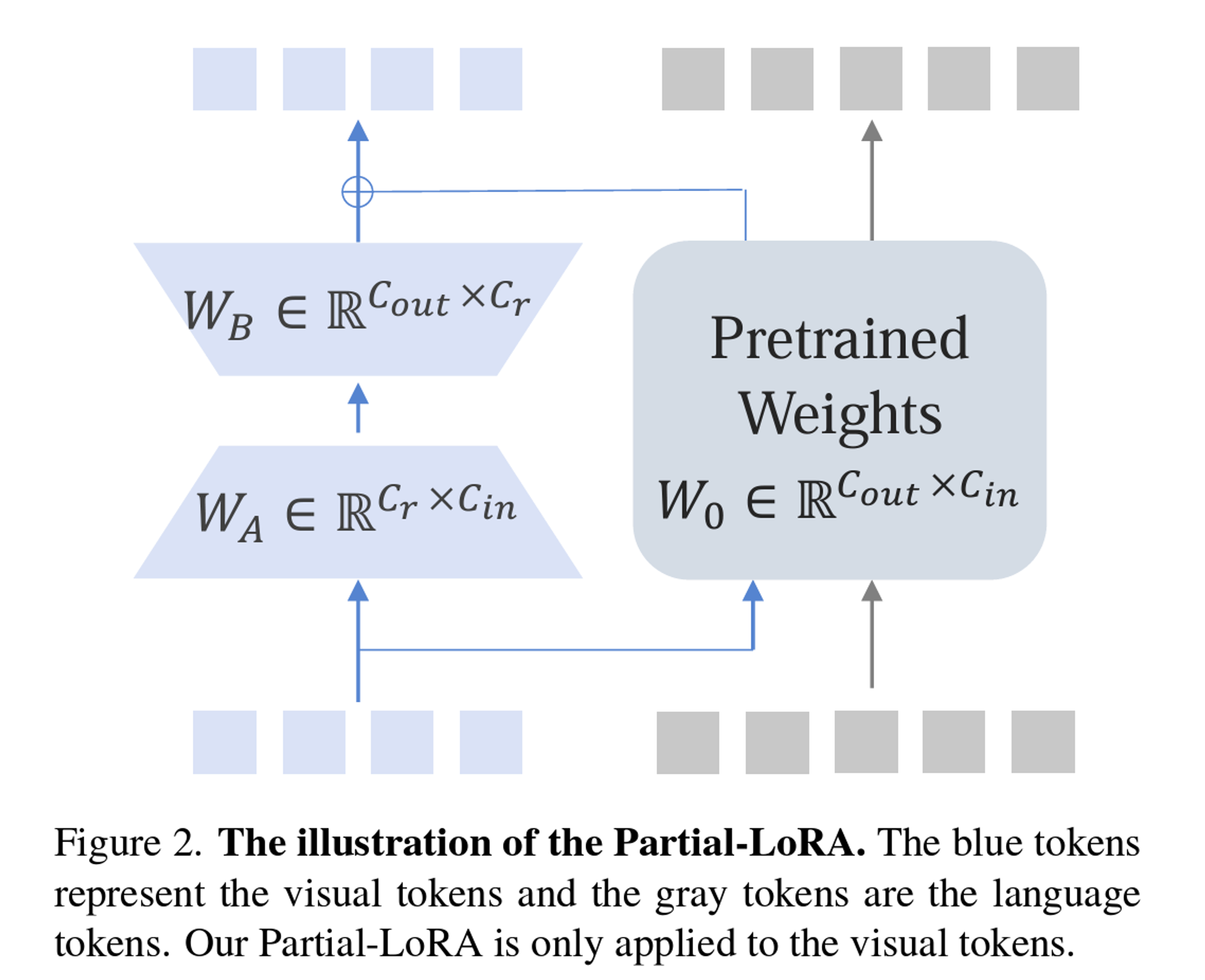
- 训练:两阶段,
- 阶段一:这次freeze住了LM,训练Vision Encoder和PLoRA。和第一代训练LM + Q-former的思路不同,猜测是出现了语言能力下降的问题,因此LM需要freeze住。Training的三个目标:第一是理解,知道图像中出现的是什么,第二是丰富回答,这里应该是类似于之前的image-grounded caption Generation,第三个是增加Vision能力,侧重数据集的构建。但这里应该没有用三个Loss做训练!*因为Pretrain的时候LM被Freeze住了,所以产生caption的这个Loss(即Image grounded Text Generation)这部分的Loss不应该在这步存在;并且,这三个目标使用的数据集格式,基本上是Image-caption和Image-sentence。因此猜测这步的训练就*只使用了Constrastive learning的Loss,同时back prop Vision Encoder和PLoRA。
- 阶段二:fine-tune的过程是Vision Encoder + PLoRA + LLM同时训练,这里需要注意的是,Multi-task tuning的这步是加了10%的InternLM的数据一起训练的,猜测不然的话LM的能力会下降。这步的Loss就纯是LLM的Loss了,直接看这个code,应该就是直接把Image embedding当做一部分Text embedding,用LLM的cross entropy Loss来同时更新这几个组成部分的参数。
- 训练:两阶段,
| InternLM-XComposer 1 | InternLM-XComposer 2 | |
|---|---|---|
| 阶段 1 | 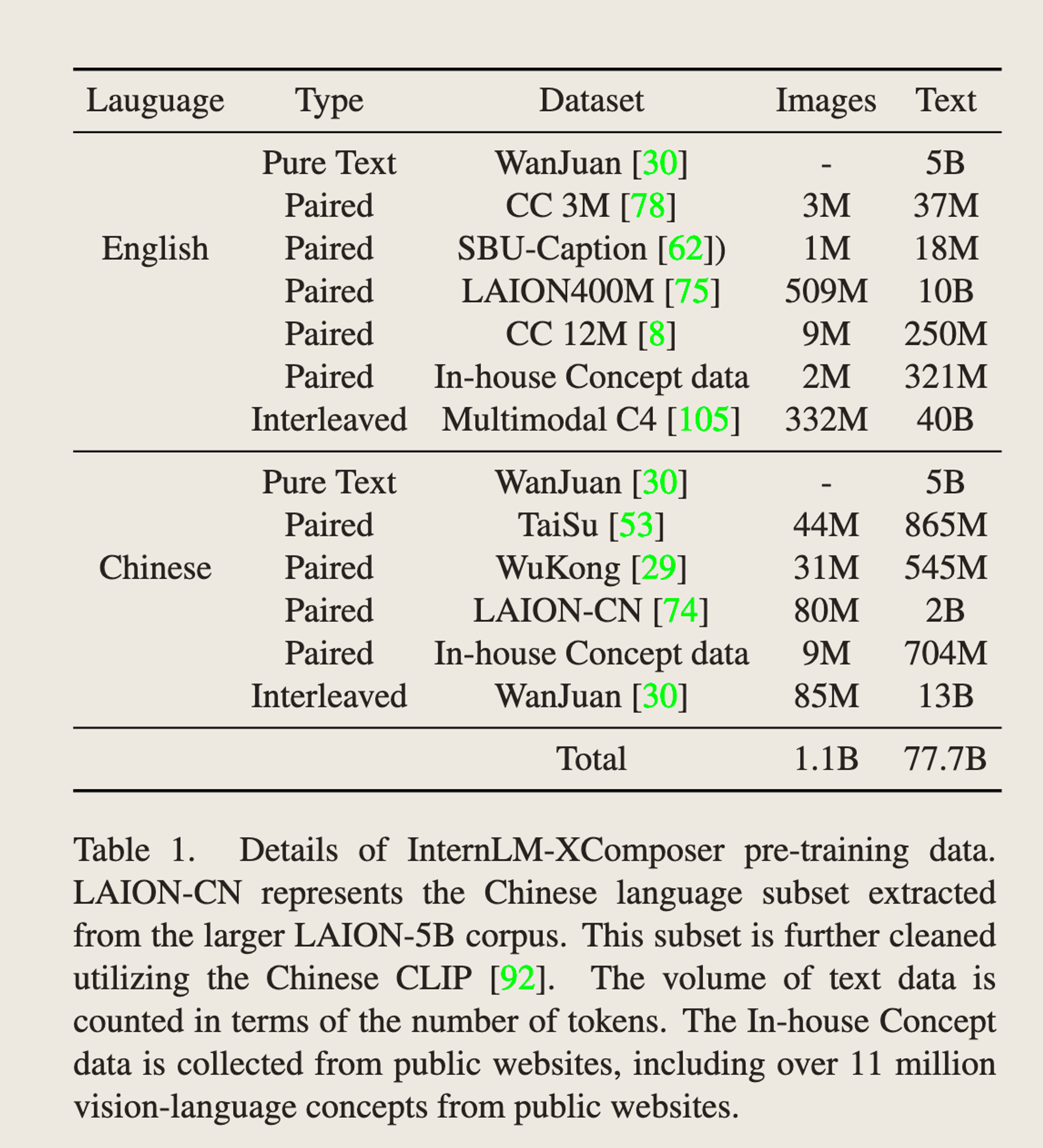 |
 |
| 阶段 2 |  |
 |
- 思考:如果这个训练方法有用,说明可以Follow隐式学习Visual和Text的权重的方法来做Pretrain是更好的。
LLaVA
-
Intuitive:这篇工作已经在BLIP-2之后了,所以Image的理解能力不是LLaVA希望提升的重点,LLaVA是想提升多模态模型的Instruction-Following ability,也就是特定的多轮QA场景。
-
主要贡献:构造了三种Instruction的数据,包括多轮对话,图片描述和复杂推理。其中,图片描述是从多轮对话中选取出来的。分别构造了58k,23k和77k数据
-
网络结构
-
用了一个projection matrix直接把CLIP的最后一层Output feature映射到Language的Token space上面,和Instruction拼在一起给到LLM做推理。
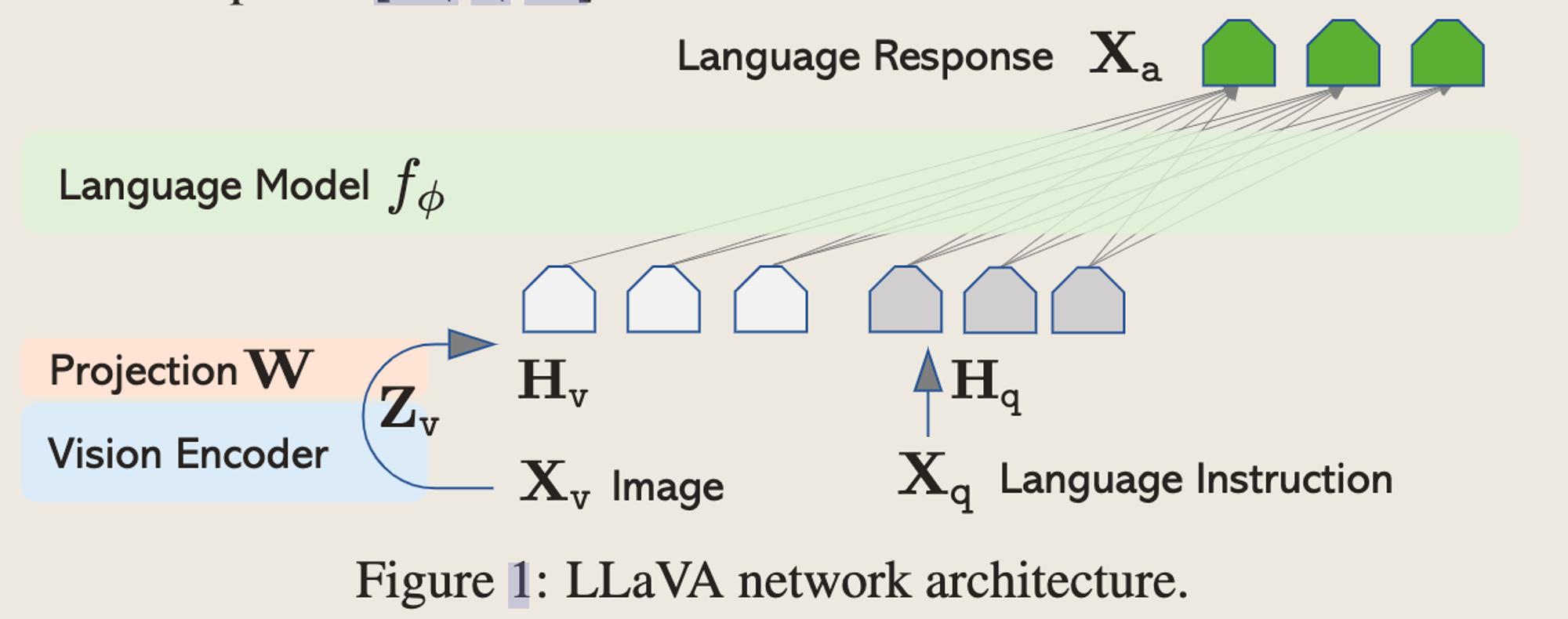
-
-
Training - 分成两步,模态对齐和Instruction tuning
- 模态对齐:这步使用CC3M的Image caption数据进行模态对齐,只训练这个projection matrix,Input是Instruction(describe this image briefly) + Image,Output是Image的caption,构造了训练对。
- 端到端训练:这一部分训练LLM和Projection matrix,用了Science QA和多轮Chatbot对话的数据。
-
Takeaway
- 其实模态对齐可能不需要很复杂的结构?data才是王道?
- LLaVA的图片理解能力到底是什么水平,和其他模型比起来?还不太清楚