CLIP - OpenAI - 2021
-
Initiative 在Text领域,pre-train模型可以在不改变任何模型结构,通过prompting的方式泛化到下游任务,Image领域是否能有这样的模型?
-
当前进展
- NLP领域,只用webtext做训练,不用labelled数据集就能实现上面的目标,Image领域呢?
- 原来有类似的工作,但是他们学习到的Image representation是在一些有label的数据集上,而这些label是非常少的;
- 所以一个新的想法是,能否找到更大量的数据集上预训练一个能学习到representation的?
- 这样的数据集,网络上有很多图,这些图是有文字描述的,是否能用这样的文字作为Image representation的监督信号呢?
- 所以,CLIP的核心假设就是,文字能够作为Image perception的一个监督信号,指导模型学习到图片的perception
-
如何做
-
整体架构,两个实验,使用加了attention pooling的ResNet和Vision Transformer作为Vision Encoder。Text的使用63M的Transformer,只用了长度76的Sequence length。
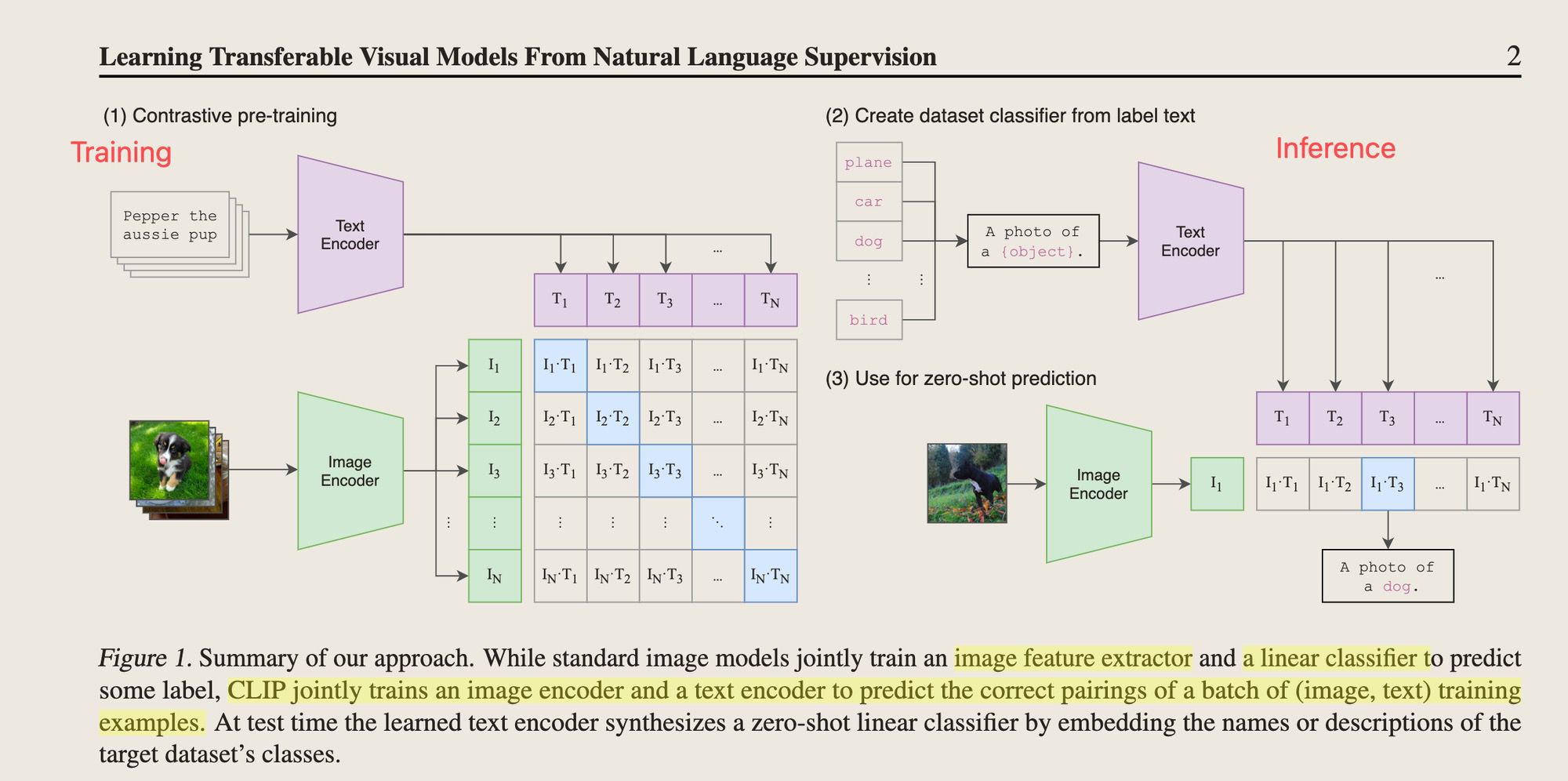
-
用文字作为supervision的方法有很多,比如n-gram和topic models,但是用transfomers这种架构的深度网络作为image 网络的监督信号网络的方法还是未经尝试。
-
-
数据如何组织
- 之前的一些数据集太脏了,过滤后仅剩下15m。所以我们组织了400m的数据集叫做webImageText
-
如何训练
-
训练的主要难点在于数据量太大,如果直接把CNN和一个Text Transformer在一起从头训练,在63m大小的transformer上都比ResNet-50的image encoder慢太多了
-
之前用的方法,预测bag-of-words的和transformer-based,都是为了预测正确每一个和Text最相近的单词,说白了都是分类问题,这个最大的问题是丢失了context,且vocab(在这个任务中就是caption)非常的sparse(自然语言而非golden label作为训练标签),非常难训练
-
所以他们用了contrastive的objective,这样可以解决不好训练和训练慢的问题。
-
以batch size=10为例,训练时将<image, caption>这样的10对数据做分别对每张Image做交叉熵Loss和每个caption做交叉熵Loss。对每张图片,最大化和一张图相近的Caption,对每个caption,最大化和一个caption相近的图片。前者可以找到和图片最近的Caption,后者可以把每个图片之间的距离拉远。

-
-
实验
- Image classification领域的zero-shot transfer learning指代的是能够正确把图片归类到之前没有训练过的类别
- 这篇文章主要学习zero-shot的transfer learning
- 实验结果表明,这个Pretrain的方法,在没有用过任何classification的labelling的情况下,比Visual n-grams好了太多
- Prompt engineering: 这里指的主要是文本的prompt,比如a photo a cat要比直接用cat作为caption好很多;另外,词语的多义性也直接导致了语言模型confuse的程度增加;另外,用加上任务相关的信息能大大提升性能,例如把{label}改成a photo of {}, a type of pet能提升宠物类的benchmark
- 尝试用不同的prompt来提升任务的整体质量
-
实验结果
-
在大部分benchmark上都显著好于ImageNet50的方案,但是在专业数据集上表现较差。作者说了有很大提升空间,但是同时质疑评估的数据集,因为即使tumor Classiication对于没学习过类似知识的人类来说都是不能完成的。
-
zero-shot的性能有好有坏,下游任务如果要用这个更好的任务做fine-tune,能否好过现在SOTA模型呢?更进一步说,representation learning到底到位了没有?Fine-tune完之后在21/27个任务上都取得了sota的结果
-
fine-tune之后到底对其他任务的影响有多大?这个叫做Natural distribution shift robustness。作者提出了疑问,到底是不是在ImageNet的数据集上做训练,导致了robustness gap。因此作者做了一个实验,就是在ImageNet上做fine-tune,然后再Evaluate其他的结果。最后发现tune完之后在其他任务上基本没什么shift。这有可能是预训练数据集很大导致的,也可能是用语言作为监督信号导致的,不过这个训练的方法是通过一个
L2 regularized logistic regression classifier来做的,并没有整体更新CLIP的权重,所以这个结果有点tricky,没在一个层面上比较。
-
-
limitations
- 在很多任务上zero-shot和SOTA相差很远
- 在手写字体识别上,CLIP很容易就输给了简单的deep分类模型,这也有可能说明CLIP并没有解决深度网络的泛化问题,只是通过海量的训练数据保证了大部分任务是in-distribution的