Flamingo - Deepmind - 202204
-
Existing Gap
- CLIP模型无法做文字生成,只能做分类,从已有数据中做选择;
- 能够用image作为language generation的condition来构造这个任务从而完成image caption,image QA这样的任务呢?
-
Contribution
- 提出了一个可以做few-shots来帮助LM做image caption和image QA任务的方法;具有生成能力。
- 提出了一个量化VLM能力的benchmark。
-
Method
-
方法的核心是如何把图片映射到LM的Space下面,使之成为Text Generation的condition,能够生成与之对应的文本。因此有两个问题,第一是如何建模,第二是如何训练
-
如何建模?visual feature如何映射到visual tokens?以一个Nomalize-free ResNet为例,Output feature是一个4D space,visual token一般是1D space。如何映射能够在减少信息丢失的前提下,尽可能表征一张图片。且visual token应该是Vocab size大小的整形。作者在这里用了perceiver resampler. Input在这里是
-
整体架构如下所示
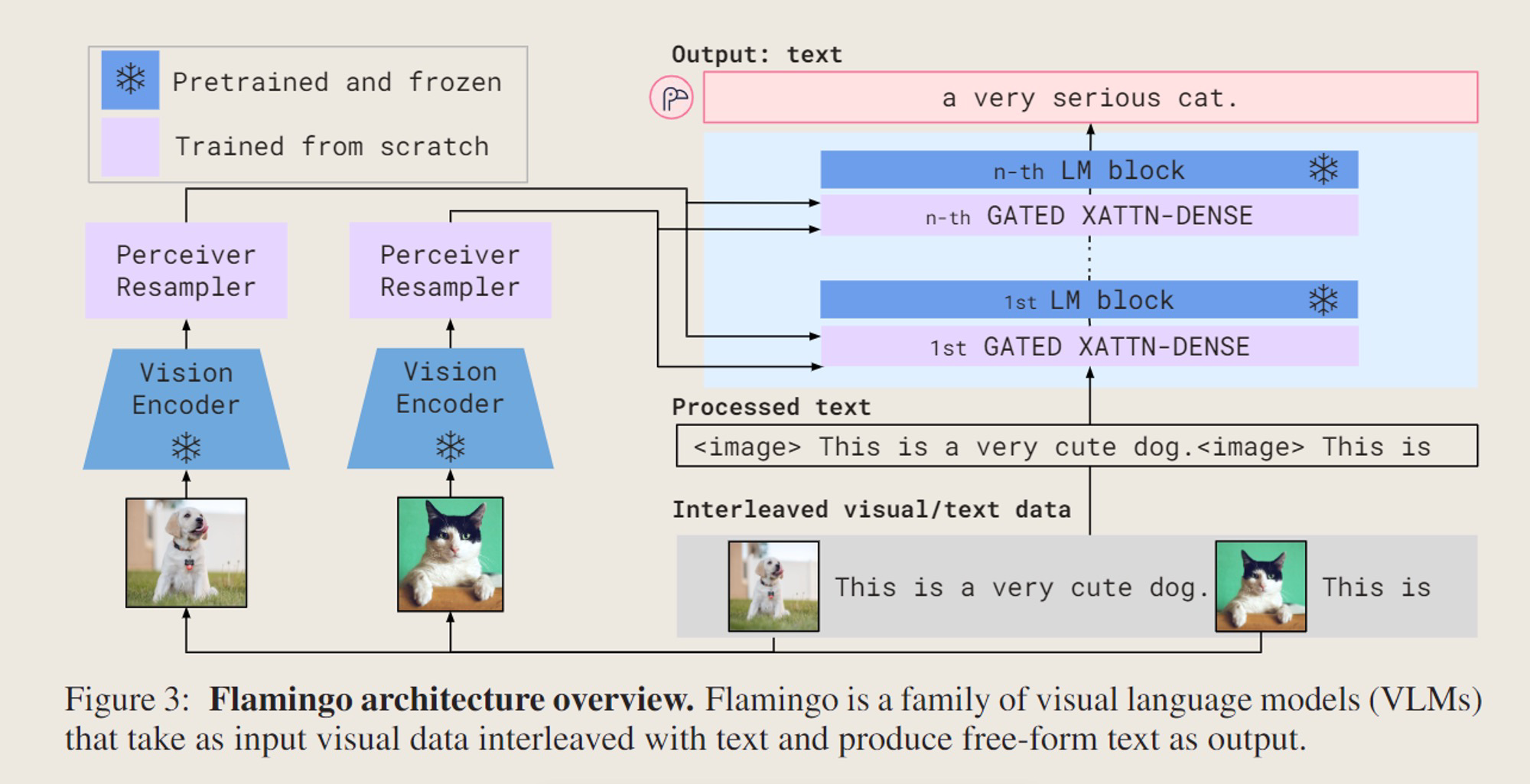
-
其中,Gated x-attn如下所示
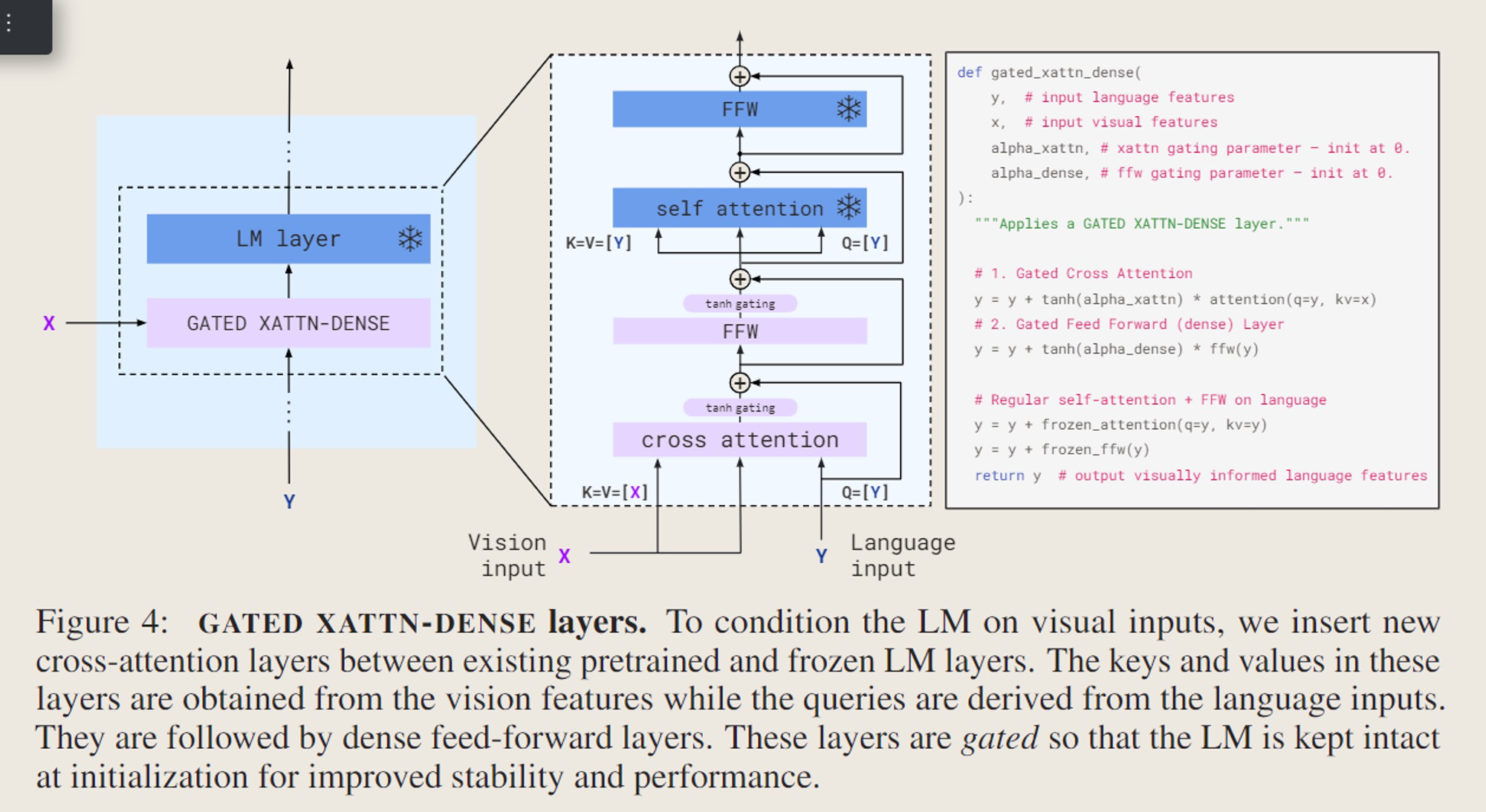
-
-
如何训练
-
图文混合+图文pair数据集训练
-
关键一句话,不同数据集被assign了不同的权重作为训练的超参,这是performance的关键……大模型预训练全靠炼丹。

-
-
效果如何
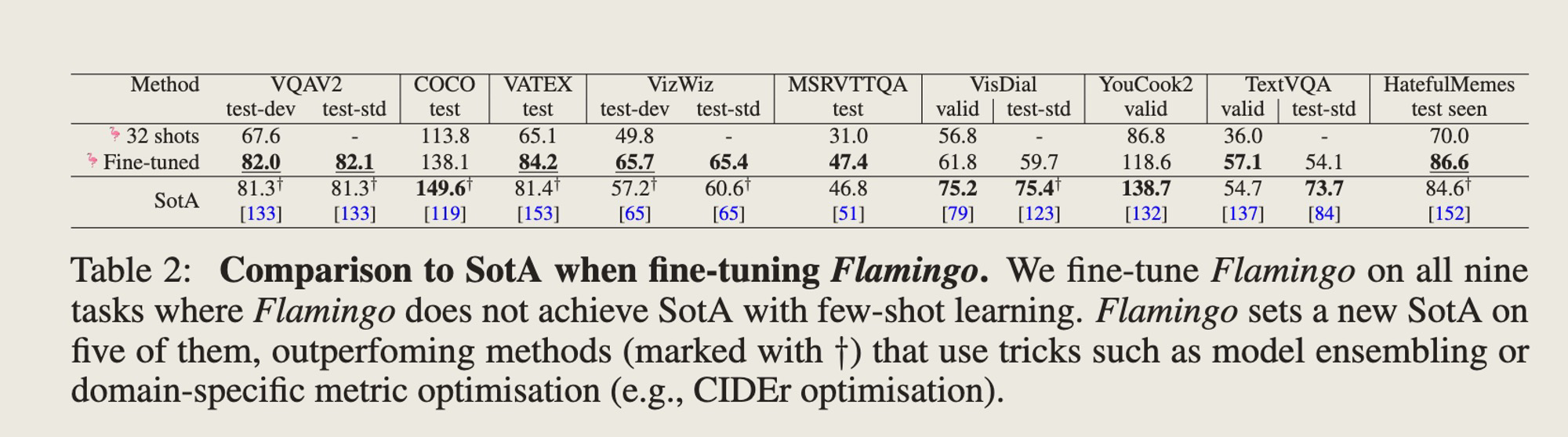
-
思考
- Ablation Study应该熟读并背诵
- 数据混合非常重要,少了Video text会掉点,少了自己构造的数据也会掉点,少了最原始的Image text pair直接掉点9.8%。
- Arch是试了好几遍才得到的,不是一上来就建模了这个Gated Xatten
- Freezing LM对于任务很关键,否则最多会掉12%。即使用Pretrain的ckpt,只是用来Fine-tune,也会掉点非常严重。
- 这里Flamingo的方法明显有些不太赶趟了,现在很多都用的是更加复杂的visual encoder了。但这也侧面说明数据的重要性,vision encoder只要能大概表征图片的内容,加上一个projector到language就搞定了。
- Vision的现在流行用ViT来代替传统的了
PREVIOUSAI算法