BLIP-2- Salesforce - 202302
- Existing Gap
- 之前的训练方法会导致LM的Catastrophic Forgetting(如果训练时候更新LM的Params);
- 作者假设,在Pretrain阶段下,多模态大模型最重要的问题是解决模态对齐(Modality Alignment)。(为什么?因为文本生成能力依赖语言模型,所以让语言模型理解Image Token是很重要的。这里的模态对齐与CLIP的区别是什么?CLIP里面只有Encoder,没有Text Generation,可以把BLIP看做CLIP的带Text Generation的改良版。为什么可以做出这个假设?比较符合直觉,因为图片问答和文本问答最大的区别就在于是否有图片输入;因此可以假设LM本身具备问答能力,只是其无法理解Image Tokens)
- Contribution
- 设计了一个Generic compute-efficient的Vision Language Pretrain架构
- 设计了一个两阶段的训练过程,第一个阶段做vision-languange representation learning,第二阶段Boost LLM的对Image的生成能力。这两个阶段都是只训练Q-former,但是两阶段的目标不同。
- Method
-
设计了一个Q-former进行模态对齐,一阶段训练把Visual Token经过Q-former映射成一个Embedding,二阶段训练再把该Embedding到LLM的FC层进行训练,这样Visual info就成了LLM的一个Soft Prompt。①核心思想是什么?Prompt-tuning,只是Prompt变成了Visual Embedding。因为仔细观察发现,LLM的参数是没有动的,问答能力依赖于其自身的问答能力;②为什么设计了三个Loss,分别是做什么的?Contrastive Learning的Loss可参考CLIP,主要是兼顾大规模预训练的性能和训练效果;Generation Loss主要是用了Q-former右半部分生成caption,把Image Token作为生成的condition,但是这里由于Q-former结构设计上的限制,不能直接把Image Tokens作为condition,因此作者用Learned Queries作为Image Token的代理来实验Image conditioned Generation。Image Text Matching Loss就是预测一个image Text pair对是否是一对,为什么要设置这个Loss,作用有多大?个人感觉是为了刷benchmark设计的一个Loss,毕竟语言模型没有参数更新,作为Soft Prompt,改动一下Q-former对文本生成类下游任务估计影响不大,但是可以直接boost一波图文匹配类型的任务。https://github.com/salesforce/LAVIS/blob/main/lavis/models/blip2_models/blip2_qformer.py 参考这个里面的三个loss的写法。
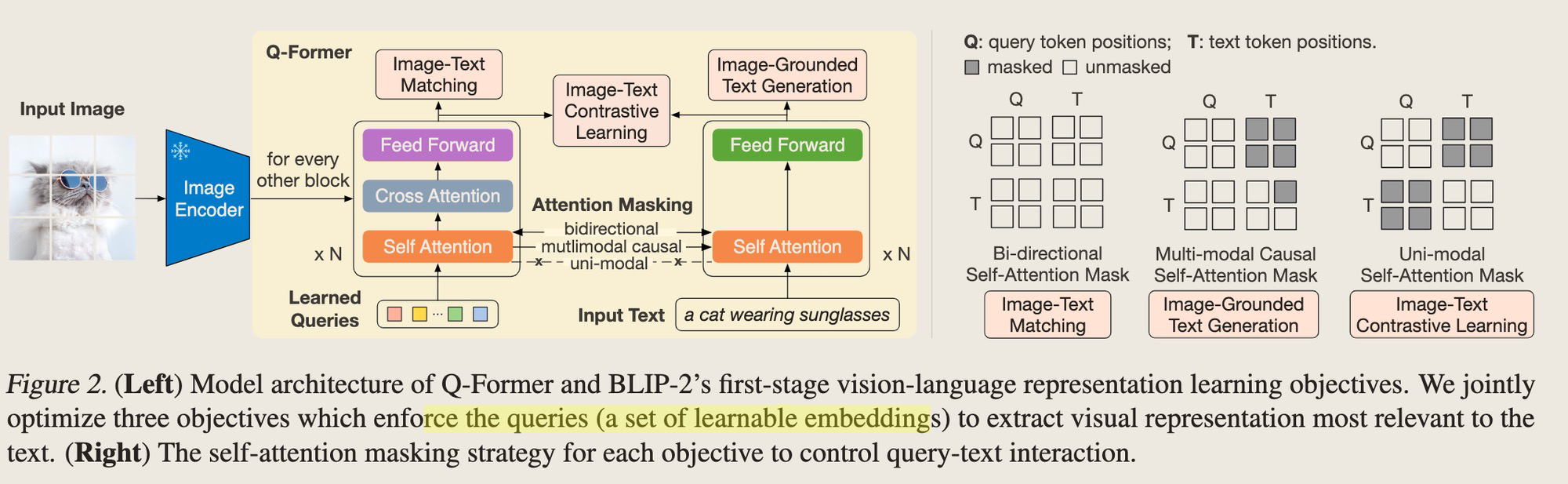
-
第二阶段的训练过程,主要是为了找到Soft Visual Prompt。这里主要是用LLM的Generation Loss来训练Q-former+FC层。
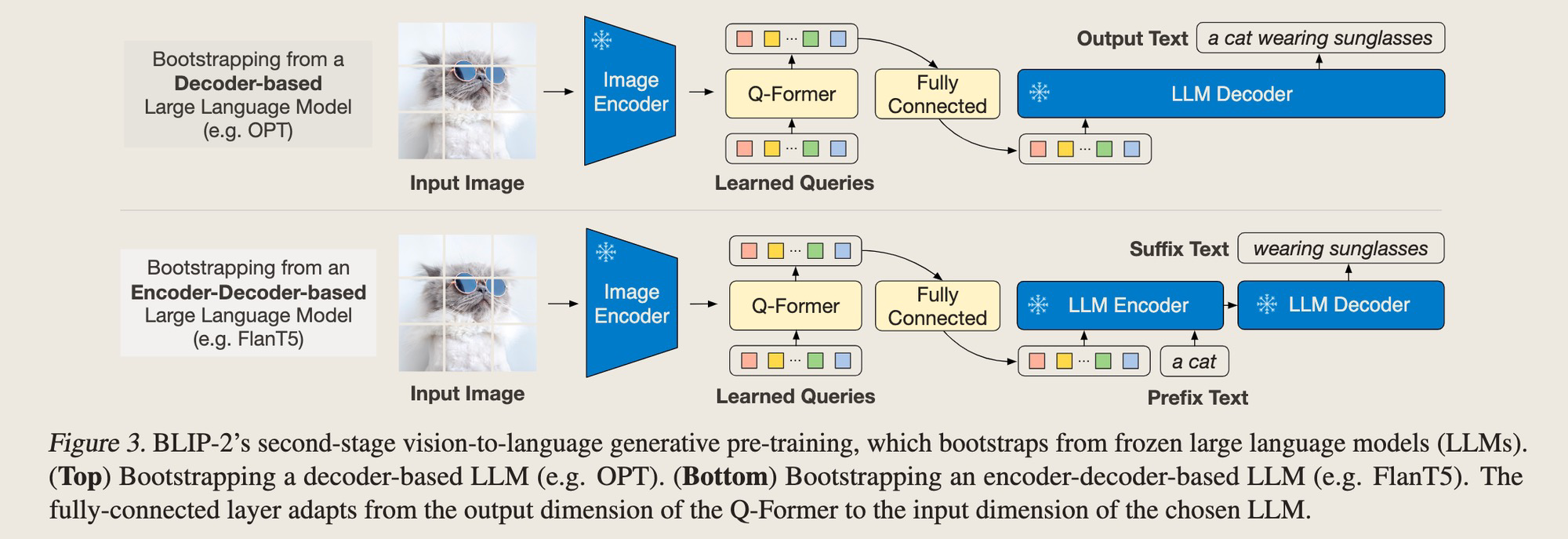
-
- 训练 - 两阶段训练都更新相同的parameters,但是通过不同的Attention mask实现不同目标的学习。
- 一阶段:这里就是一个image representation Learning,单纯学习了Embedding而已,这个Embedding并没有在pretraining的时候align到任何LLM上面,只是用Q-former给出了Embedding。只是学习这个Embedding的方法是融合了3个Loss学到的。
- 二阶段:Generative pretraining,用一层LC把Q-Former的embedding接到LLM上,这一步的learnable params是什么?Q-former + LC层,用Language modelling loss、把第一阶段pretraining的结果align到不同的下游语言模型,这里实际上是一个Soft Prompt tuning,并没有update LM的参数。这样能避免LM的catastrophic forgetting问题
-
二阶段训练的Loss
outputs = self.t5_model( inputs_embeds=inputs_embeds, attention_mask=encoder_atts, decoder_attention_mask=output_tokens.attention_mask, return_dict=True, labels=targets, ) loss = outputs.loss
- 结果如何
-
以上思考可以看到,BLIP-2的最大优点就是训练参数非常小,而且能够adapt到不同的语言模型上。

-
- 思考
- 这个模型非常适用在想保持LM的能力,同时GPU也不是很多,希望能包含一些Visual Info的业务场景。