LLaVA Microsoft Research
LLaVA - 202304 - MS Research
-
Existing Gap:
- 之前的大部分工作都在做模态对齐,做图片的representation learning,而没有针对ChatBot(多轮对话,指令理解)这种场景优化。
-
Contribution:这篇工作已经在BLIP-2之后了,所以Image的理解能力不是LLaVA希望提升的重点,LLaVA是想提升多模态模型的Instruction-Following ability,也就是特定的多轮QA场景。
- 构造了三种Instruction的数据,包括多轮对话,图片描述和复杂推理。其中,图片描述是从多轮对话中选取出来的。分别构造了58k,23k和77k数据
-
网络结构
-
用了一个projection matrix直接把CLIP的最后一层Output feature映射到Language的Token space上面,和Instruction拼在一起给到LLM做推理。
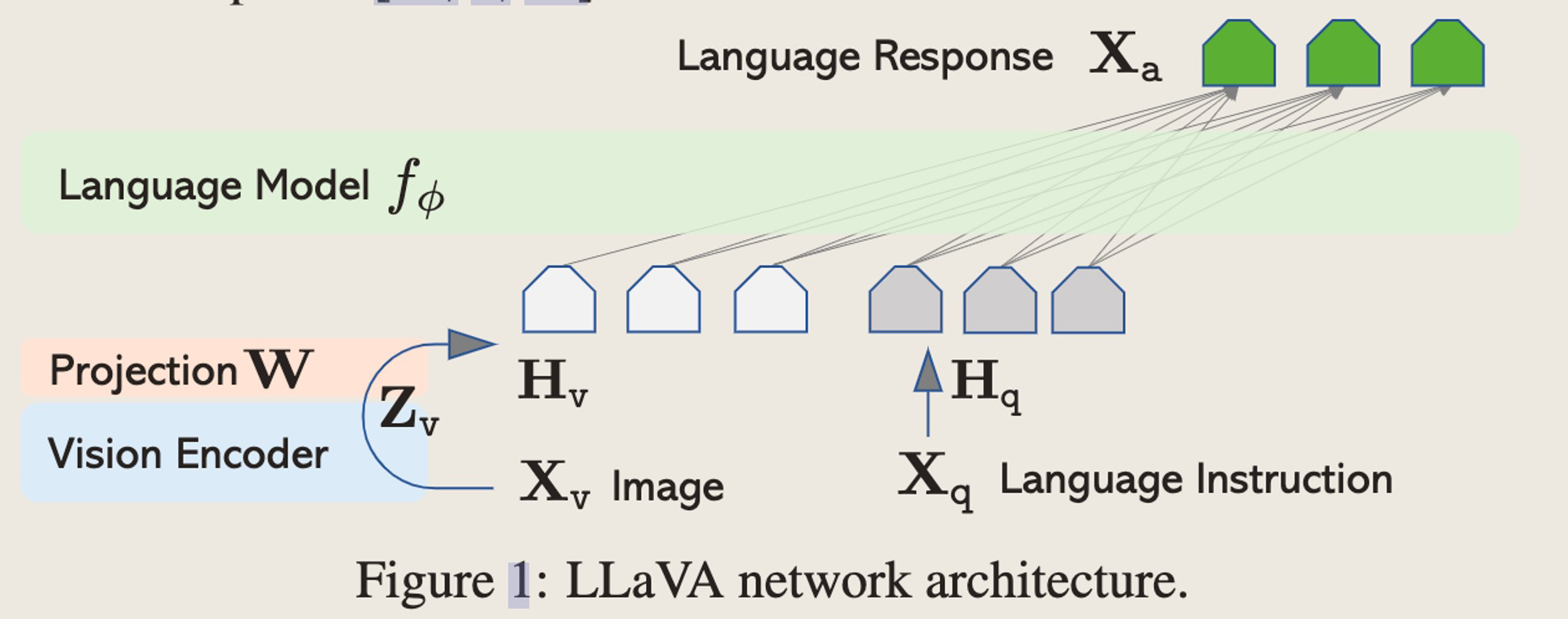
-
-
Training - 分成两步,模态对齐和Instruction tuning
- 模态对齐:这步使用CC3M的Image caption数据进行模态对齐,只训练这个projection matrix,这里统一了两步训练数据的格式,都是Instruction + answer的形式,只是模态对齐时候的Input是固定Instruction(describe this image briefly) + Image,Output是Image的caption,构造了训练对。
- 端到端训练:这一部分训练LLM和Projection matrix,用了Science QA和多轮Chatbot对话的数据。
-
结果
-
评估:把Image+Instruction给到LLaVA,把GT的Image description和Instruction给到Text-only的GPT-4。在得到两个模型的response结果以后,再把Instruction和Visual information给到GPT-4,让GPT-4根据helpfulness, relevance, accuracy和response detailness按照1-10打分,同时输出给出打分的解释。
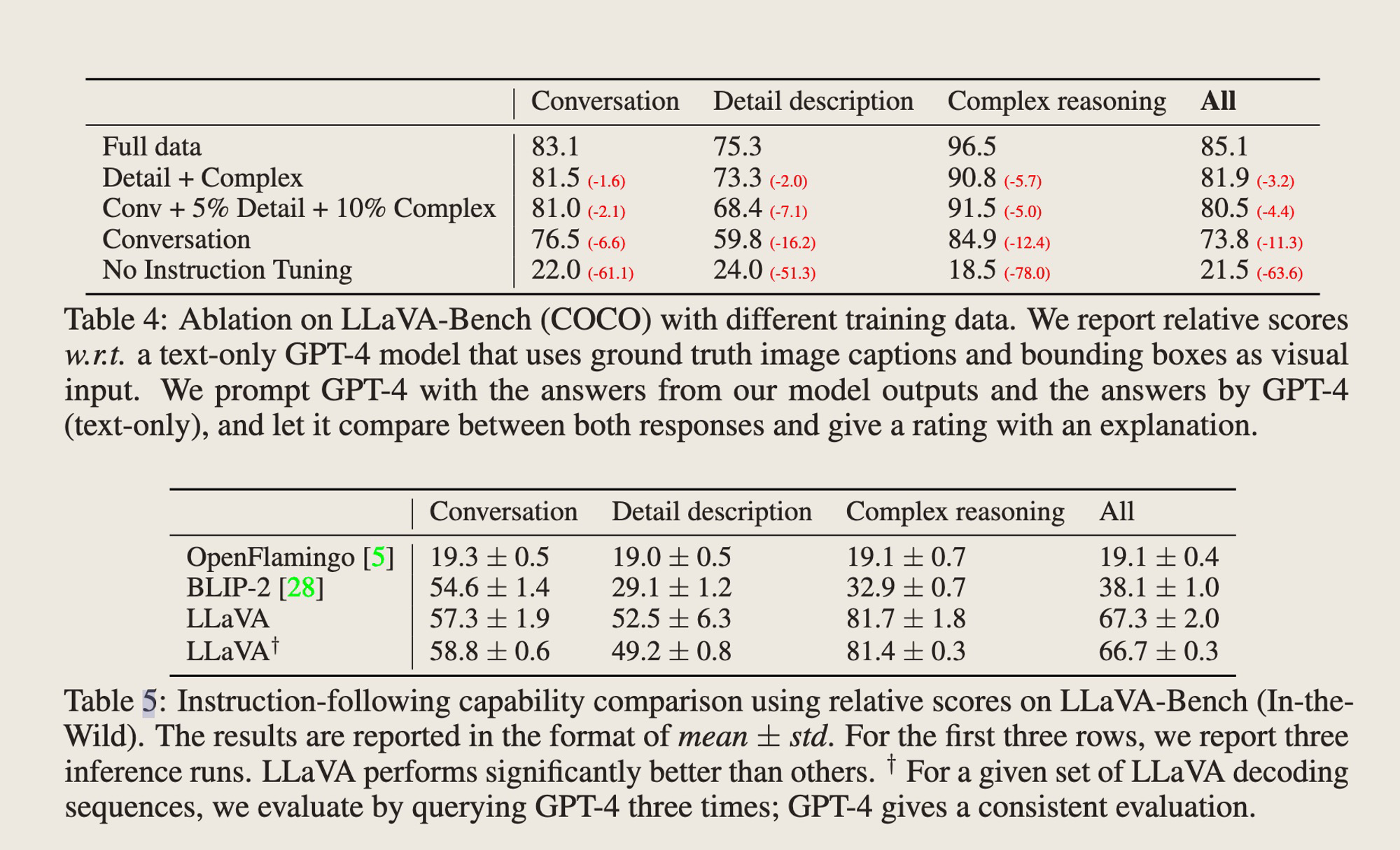
-
-
Takeaway
- 其实模态对齐可能不需要很复杂的结构?data才是王道?
- LLaVA的图片理解能力到底是什么水平,和其他模型比起来?还不太清楚
- 一直以为LLaVA这种较为简单的alignment架构是最先提出来的,但实际上不是,大道至简,先用最简单的结构快速验证想法的话,LLaVA就是最好的选择。
st=>start: Start
op=>operation: Your Operation
cond=>condition: Yes or No?
e=>end
st->op->cond
cond(yes)->e
cond(no)->op
PREVIOUSAI算法