LLaVA Mistral Multiple Images SFT
LLaVA是2023年4月提出的针对多模态场景的,可多轮图文问答ChatBot模型。LLaVA通过简单地把1024维输出的CLIP特征用projector和语言模型的embedding拼接起来,就能实现该效果。
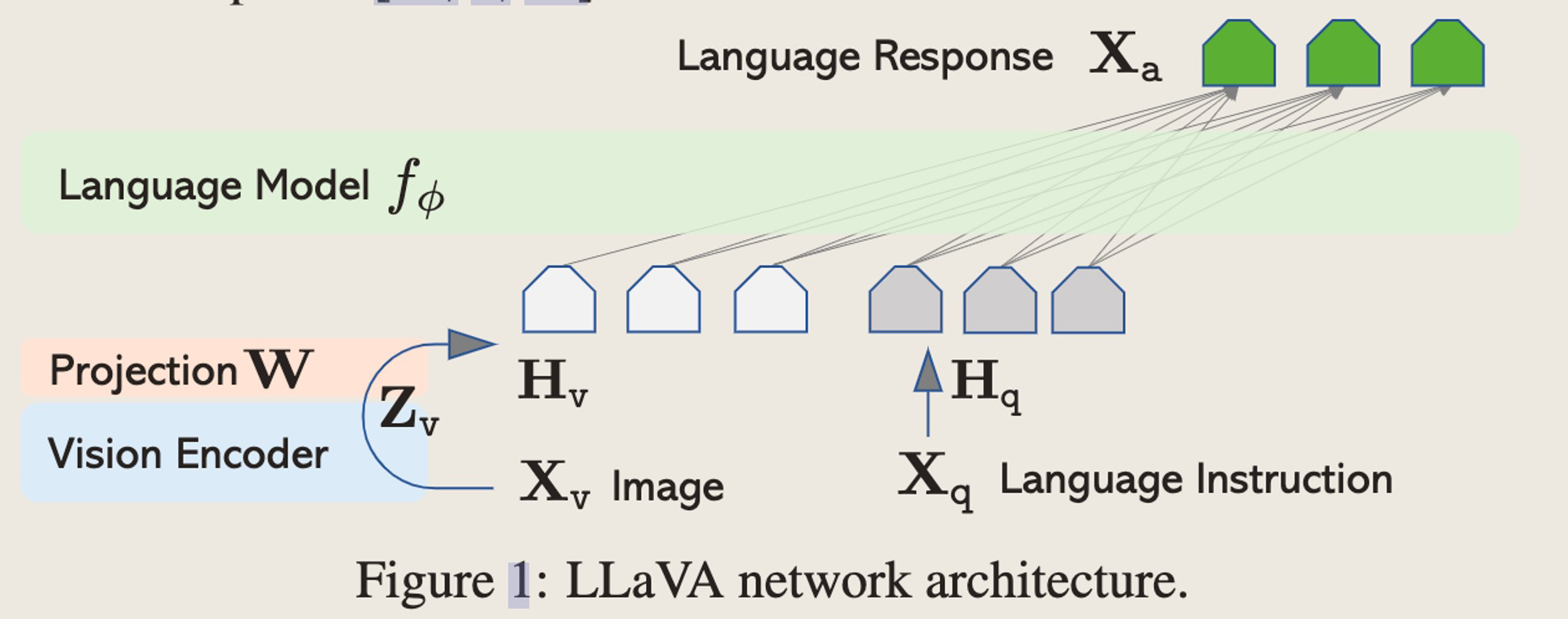
但是,在原文章中,作者是针对单图问答场景进行的训练,如果想实现一个多图输入场景的任务,应该如何改造结构以及构造训练数据呢?下面我们一起来看一下。
代码结构
启动命令
bash llava/scripts/v1_5/finetune.sh
训练入口
llava/train/train.py
训练框架
- 训练框架使用了Huggingface下的Trainer,Trainer是专门为了Transformer架构优化的训练器。进去之后可以看到作者了使用
deepspeed训练框架,这里不再赘述。
Fine-tune的整体流程

关键代码
多轮对话预处理
图像标记将在分词后的提示文本块之间插入。以下是该功能工作原理的分解:
- 提示通过
<image>标记分割,创建一个块的列表。 - 使用提供的分词器对每个块进行分词,得到一个令牌 ID 的列表。
- 使用
insert_separator函数将分词后的块列表与image_token_index(代表图像的令牌)交错插入。 input_ids列表如下构建:- 如果第一个分词后的块以序列开始(BOS)令牌开头,则
input_ids的第一个元素设置为该 BOS 令牌。 - 通过迭代交错的分词块列表和
image_token_index填充input_ids的剩余元素。
- 如果第一个分词后的块以序列开始(BOS)令牌开头,则
因此,结果的 input_ids 列表将具有以下结构:
[BOS_token(如果存在),tokens_from_chunk1, image_token, tokens_from_chunk2, image_token, ..., tokens_from_last_chunk]
image_token_index 将插入原始提示中每对连续块之间。
例如,如果提示是 "This is <image> a sample <image> prompt",且 image_token_index 是 1234,结果的 input_ids 列表可能看起来像:
[101, 1010, 2003, 1015, 1234, 2034, 3076, 1234, 2001, 1028, 102]
这里,令牌 ID 代表分词的单词,而值 1234 是插入块之间的 image_token_index。
大致改动
要适应多图训练,首先要判断自己的任务是要图片和文字interleaved的形式还是separate的形式。
- 数据预处理:确保Input conversation中的image_token被正确替换了;
- Model Forward:确保训练input_embedding是否按照期望顺序被cat在一起了。
注意,因为LLaVA本身SFT时候,是把所有image的embedding都放到了最前面(通过对话预处理实现的),因此如果你训练改成interleaved的形式,可能导致其本身SFT Align的分布变化。
预训练数据组织
原SFT训练数据格式,为了展示用,复制了两条数据
[
{
"conversations": [
{"from": "human", "value": "Please tell me what's unusual about this image: <image>"},
{"from": "gpt", "value": "A man is ironing his clothes on a vehicle. "},
{"from": "human", "value": "What's funny about this?"},
{"from": "gpt", "value": "Because people don't usually do this at home."}
],
"image": "llava/image_folder(local image path)"
},
{
"conversations": [
{"from": "human", "value": "Please tell me what's unusual about this image: <image>"},
{"from": "gpt", "value": "A man is ironing his clothes on a vehicle. "},
{"from": "human", "value": "What's funny about this?"},
{"from": "gpt", "value": "Because people don't usually do this at home."}
],
"image": "llava/image_folder(local image path)"
}
]
改动后SFT训练数据格式:
[
{
"conversations": [
{"from": "human", "value": "Please tell me what's unusual about this image: <image>"},
{"from": "gpt", "value": "A man is ironing his clothes on a vehicle. "},
{"from": "human", "value": "What's funny about this?"},
{"from": "gpt", "value": "Because people don't usually do this at home."}
],
"images": ["llava/image_folder(local image path)", "llava/image_folder(local image path)"]
},
{
"conversations": [
{"from": "human", "value": "Please tell me what's unusual about this image: <image>"},
{"from": "gpt", "value": "A man is ironing his clothes on a vehicle. "},
{"from": "human", "value": "What's funny about this?"},
{"from": "gpt", "value": "Because people don't usually do this at home."}
],
"images": ["llava/image_folder(local image path)", "llava/image_folder(local image path)"]
}
]
代码改动
- (optional)修改image token的位置,我们把stack在前面的1个换成多个
# llava/train/train.py
def preprocess_multimodal(
sources: Sequence[str],
data_args: DataArguments
) -> Dict:
is_multimodal = data_args.is_multimodal
if not is_multimodal:
return sources
for source in sources:
for sentence in source:
if DEFAULT_IMAGE_TOKEN in sentence['value']:
replace_token = DEFAULT_IMAGE_TOKEN + '\n'
sentence['value'] = sentence['value'].replace(DEFAULT_IMAGE_TOKEN, replace_token).strip()
# sentence['value'] = DEFAULT_IMAGE_TOKEN + '\n' + sentence['value']
sentence['value'] = sentence['value'].strip()
if "mmtag" in conversation_lib.default_conversation.version:
sentence['value'] = sentence['value'].replace(DEFAULT_IMAGE_TOKEN, '<Image>' + DEFAULT_IMAGE_TOKEN + '</Image>')
replace_token = DEFAULT_IMAGE_TOKEN
if data_args.mm_use_im_start_end:
replace_token = DEFAULT_IM_START_TOKEN + replace_token + DEFAULT_IM_END_TOKEN
sentence["value"] = sentence["value"].replace(DEFAULT_IMAGE_TOKEN, replace_token)
return sources
- 修改多图Input
# llava/train/train.py LazySupervisedDataset
def __getitem__(self, i) -> Dict[str, torch.Tensor]:
sources = self.list_data_dict[i]
if isinstance(i, int):
sources = [sources]
assert len(sources) == 1, "Don't know why it is wrapped to a list" # FIXME
if 'image' in sources[0]:
image_files = self.list_data_dict[i]['images']
image_folder = self.data_args.image_folder
processor = self.data_args.image_processor
images = []
for image in image_files:
image = Image.open(os.path.join(image_folder, image_file)).convert('RGB')
if self.data_args.image_aspect_ratio == 'pad':
def expand2square(pil_img, background_color):
width, height = pil_img.size
if width == height:
return pil_img
elif width > height:
result = Image.new(pil_img.mode, (width, width), background_color)
result.paste(pil_img, (0, (width - height) // 2))
return result
else:
result = Image.new(pil_img.mode, (height, height), background_color)
result.paste(pil_img, ((height - width) // 2, 0))
return result
image = expand2square(image, tuple(int(x*255) for x in processor.image_mean))
image = processor.preprocess(image, return_tensors='pt')['pixel_values']
else:
image = processor.preprocess(image, return_tensors='pt')['pixel_values']
images.append(image)
sources = preprocess_multimodal(
copy.deepcopy([e["conversations"] for e in sources]),
self.data_args)
else:
sources = copy.deepcopy([e["conversations"] for e in sources])
data_dict = preprocess(
sources,
self.tokenizer,
has_image=('image' in self.list_data_dict[i]))
if isinstance(i, int):
data_dict = dict(input_ids=data_dict["input_ids"][0],
labels=data_dict["labels"][0])
# image exist in the data
if 'images' in self.list_data_dict[i]:
data_dict['images'] = images
elif self.data_args.is_multimodal:
# image does not exist in the data, but the model is multimodal
crop_size = self.data_args.image_processor.crop_size
data_dict['images'] = [torch.zeros(3, crop_size['height'], crop_size['width'])]
return data_dict
- 修改batch Input
# llava/train/train.py
@dataclass
class DataCollatorForSupervisedDataset(object):
"""Collate examples for supervised fine-tuning."""
tokenizer: transformers.PreTrainedTokenizer
def __call__(self, instances: Sequence[Dict]) -> Dict[str, torch.Tensor]:
input_ids, labels = tuple([instance[key] for instance in instances]
for key in ("input_ids", "labels"))
input_ids = torch.nn.utils.rnn.pad_sequence(
input_ids,
batch_first=True,
padding_value=self.tokenizer.pad_token_id)
labels = torch.nn.utils.rnn.pad_sequence(labels,
batch_first=True,
padding_value=IGNORE_INDEX)
input_ids = input_ids[:, :self.tokenizer.model_max_length]
labels = labels[:, :self.tokenizer.model_max_length]
batch = dict(
input_ids=input_ids,
labels=labels,
attention_mask=input_ids.ne(self.tokenizer.pad_token_id),
)
if 'image' in instances[0]:
images = [instance['images'] for instance in instances]
if all(x is not None and x.shape == images[0].shape for x in images):
batch['images'] = torch.stack(images)
else:
batch['images'] = images
return batch
Happy coding! 感兴趣的朋友可以在Github关注
Chengru-Song/awesome-MultiModel-LLM-SFT
后续会增加更多多模态Fine-tune相关代码。Stay tuned!
PREVIOUSAI算法