LLaVA多图训练
启动脚本
bash scripts/v1_5/finetune.sh > test.log 2>&1
主要改动
-
conversation预处理支持多图
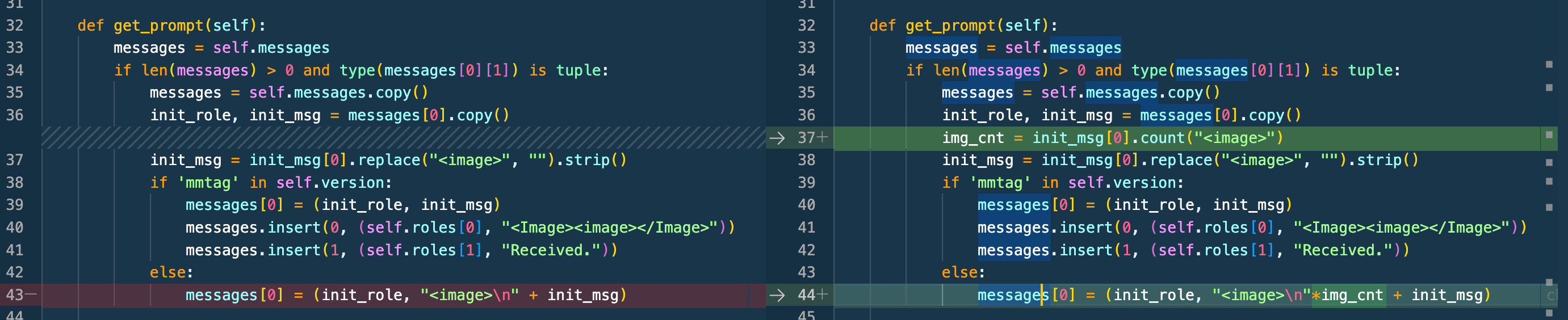
def get_prompt(self): messages = self.messages if len(messages) > 0 and type(messages[0][1]) is tuple: messages = self.messages.copy() init_role, init_msg = messages[0].copy() img_cnt = init_msg[0].count("<image>") init_msg = init_msg[0].replace("<image>", "").strip() if 'mmtag' in self.version: messages[0] = (init_role, init_msg) messages.insert(0, (self.roles[0], "<Image><image></Image>")) messages.insert(1, (self.roles[1], "Received.")) else: messages[0] = (init_role, "<image>\n"*img_cnt + init_msg)
-
修改DataLoader适配多图输入
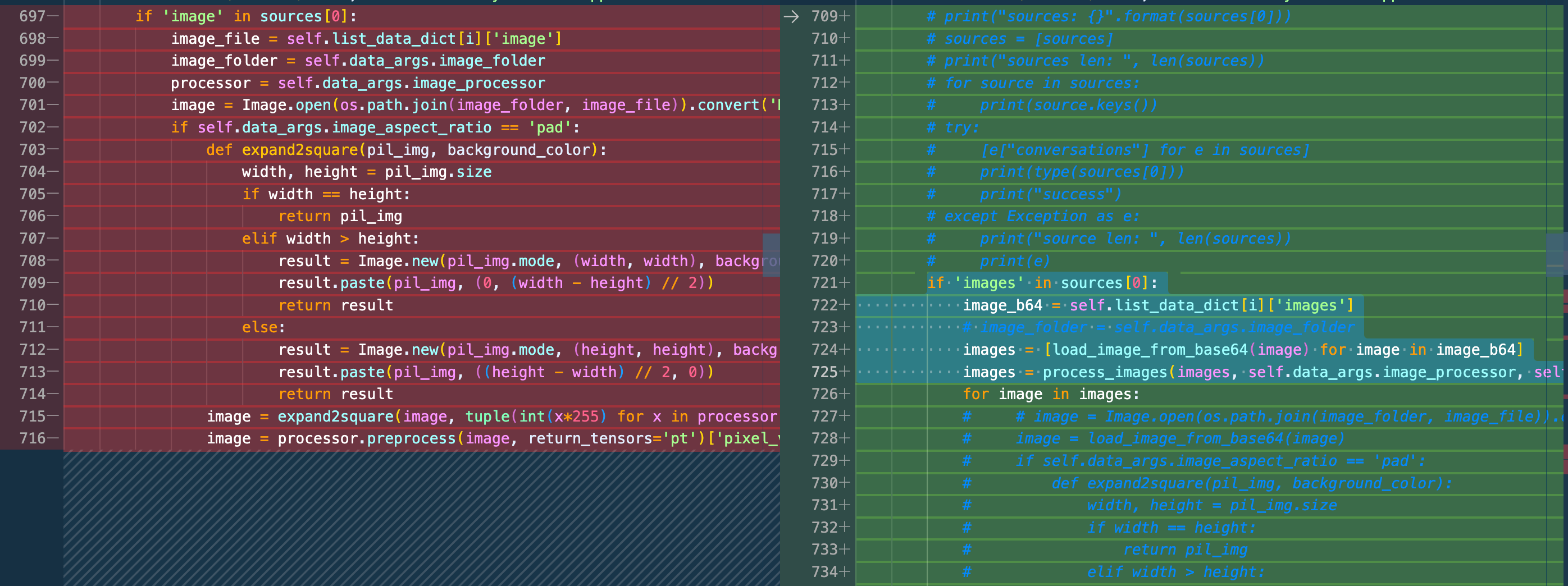
# llava/train/train.py#L721 if 'images' in sources[0]: image_b64 = self.list_data_dict[i]['images'] # image_folder = self.data_args.image_folder images = [load_image_from_base64(image) for image in image_b64] images = process_images(images, self.data_args.image_processor, self.data_args.model_cfg)
-
修改batch DataLoader支持batch图片输入

# llava/train/train.py#L800 if 'images' in instances[0]: images = [instance['images'] for instance in instances] if all(x is not None and x.shape == images[0].shape for x in images): batch['images'] = torch.stack(images) else: batch['images'] = images batch["images"] = torch.stack([image_tensor.type(torch.bfloat16) for image_tensor in images], dim=0)
-
支持batch Encode image
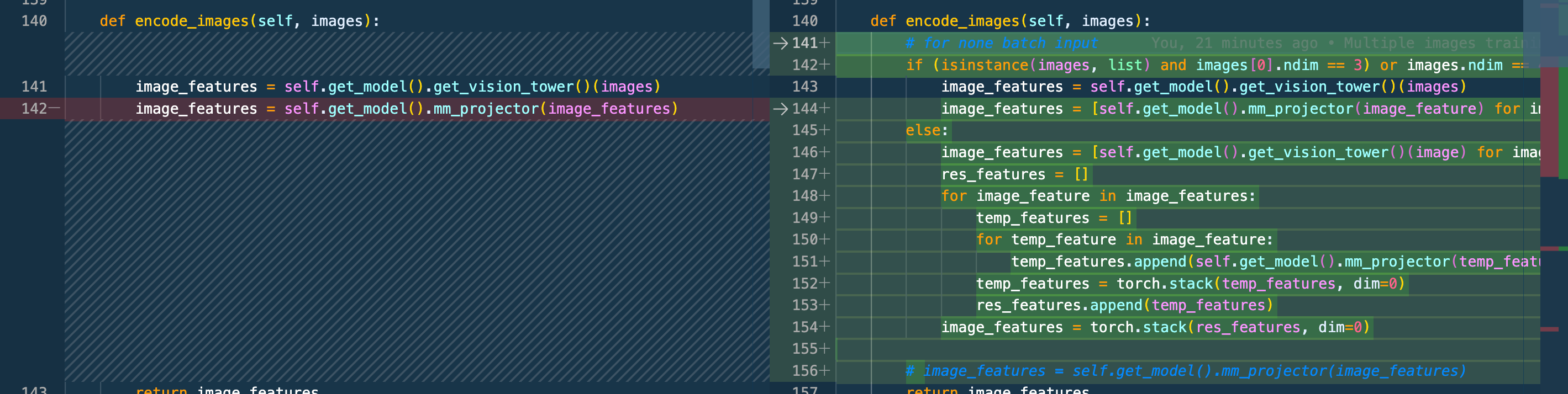
# llava/model/llava_arch.py if (isinstance(images, list) and images[0].ndim == 3) or images.ndim == 4: image_features = self.get_model().get_vision_tower()(images) image_features = [self.get_model().mm_projector(image_feature) for image_feature in image_features] else: image_features = [self.get_model().get_vision_tower()(image) for image in images] res_features = [] for image_feature in image_features: temp_features = [] for temp_feature in image_feature: temp_features.append(self.get_model().mm_projector(temp_feature)) temp_features = torch.stack(temp_features, dim=0) res_features.append(temp_features) image_features = torch.stack(res_features, dim=0)
-
开始训练
-
-
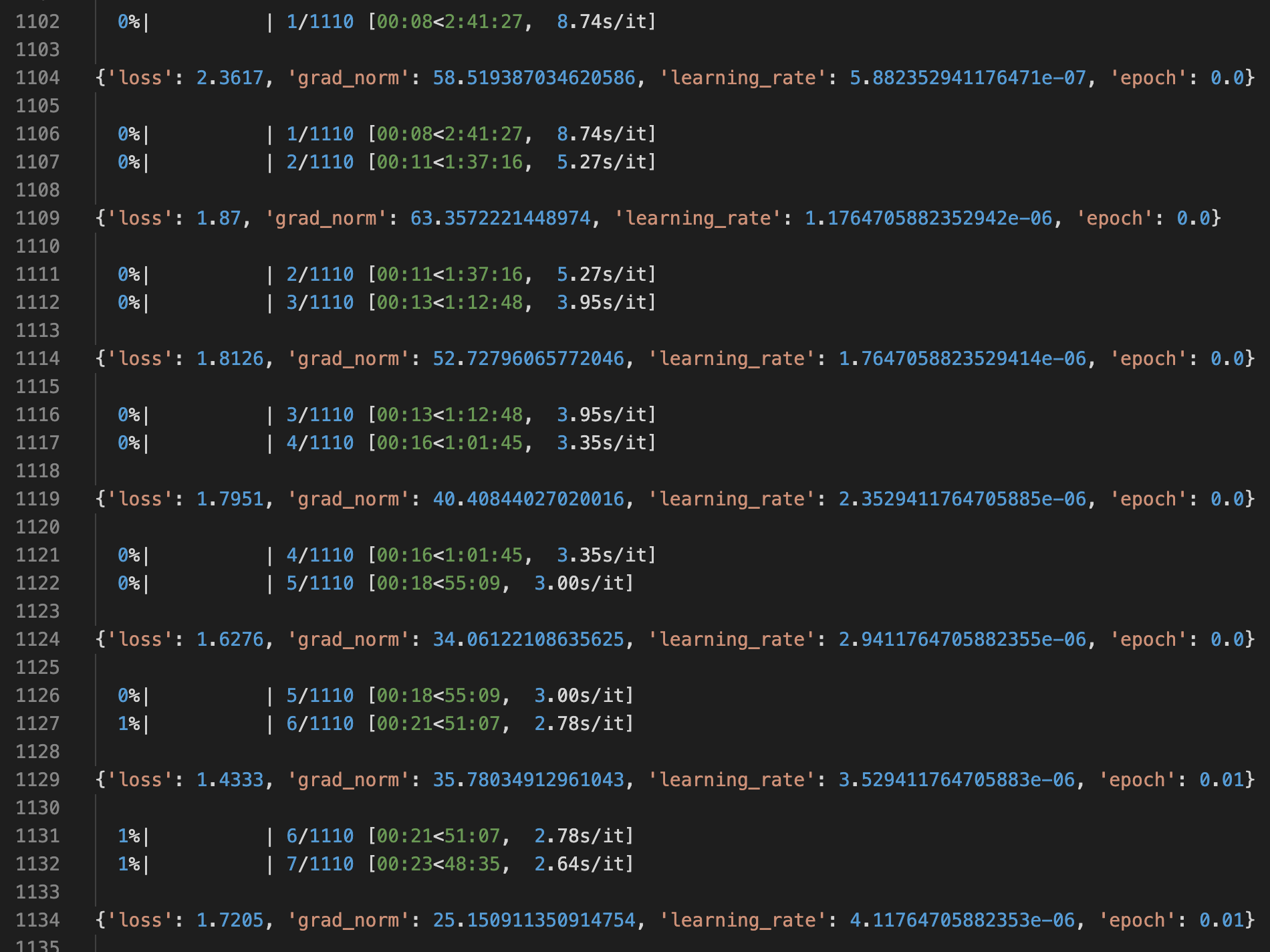
0%| | 1/1110 [00:08<2:41:27, 8.74s/it] {'loss': 2.3617, 'grad_norm': 58.519387034620586, 'learning_rate': 5.882352941176471e-07, 'epoch': 0.0} 0%| | 1/1110 [00:08<2:41:27, 8.74s/it] 0%| | 2/1110 [00:11<1:37:16, 5.27s/it] {'loss': 1.87, 'grad_norm': 63.3572221448974, 'learning_rate': 1.1764705882352942e-06, 'epoch': 0.0} 0%| | 2/1110 [00:11<1:37:16, 5.27s/it] 0%| | 3/1110 [00:13<1:12:48, 3.95s/it] {'loss': 1.8126, 'grad_norm': 52.72796065772046, 'learning_rate': 1.7647058823529414e-06, 'epoch': 0.0} 0%| | 3/1110 [00:13<1:12:48, 3.95s/it] 0%| | 4/1110 [00:16<1:01:45, 3.35s/it] {'loss': 1.7951, 'grad_norm': 40.40844027020016, 'learning_rate': 2.3529411764705885e-06, 'epoch': 0.0} 0%| | 4/1110 [00:16<1:01:45, 3.35s/it] 0%| | 5/1110 [00:18<55:09, 3.00s/it] {'loss': 1.6276, 'grad_norm': 34.06122108635625, 'learning_rate': 2.9411764705882355e-06, 'epoch': 0.0} 0%| | 5/1110 [00:18<55:09, 3.00s/it] 1%| | 6/1110 [00:21<51:07, 2.78s/it] {'loss': 1.4333, 'grad_norm': 35.78034912961043, 'learning_rate': 3.529411764705883e-06, 'epoch': 0.01} 1%| | 6/1110 [00:21<51:07, 2.78s/it] 1%| | 7/1110 [00:23<48:35, 2.64s/it]
-
关注我,看后续训练的结果以及评估。
PREVIOUSAI算法