🚀【揭秘】Llama-3:开源界的新星,性能如何?
🎉近年来,AI领域的发展可谓日新月异,而Llama-3的开源无疑给这个领域带来了新的惊喜。SuperBench团队对其进行了全面评测,结果如何呢?让我们一探究竟!
🔍Llama-3在语义理解、代码能力、对齐、智能体以及安全等方面展现了出色的性能。SuperBench的评测结果,不仅展示了Llama-3的实力,也凸显了SuperBench的权威性和速度。
史蒂夫乔布斯曾经说过,“任何对软件有极致追求的公司,都应该制造自己的硬件”。用户体验的提升,从来都不会只依赖一部分的提升,而是这个流程中的所有环节的提升。同样,在大模型时代,对用户体验追求极致的公司或产品,都应该考虑制定自己的评价标准,最大程度对齐到用户的真实体验。
Meta的开源大模型LLaMA3 8B和70B一经发布,便在各个benchmark上取得了不俗的成绩,可以看这个对比图。
那这些Benchmark能否对齐到用户的体验呢?首先我们来看下这几个Benchmark分别是什么。
| Benchmark | 评估内容 | 具体方法 |
|---|---|---|
| MMLU | 语言理解评估 | 涵盖了非常多领域的选择题,比方说抽象数学,航空航天等,让大模型做单选。 |
| GPQA | 语言理解评估 | 448道多领域多选题,主要是生物,物理和化学领域。 |
| HumanEval | 编程能力 | 164个编程问题。 |
| GSM-8K | 数学能力,推理能力 | 8.5k小学生数学问题,需要2-8步的推理才能解决 |
| MATH | 数学能力,推理能力 | 数学问题,包括线性方程求解,质数分解等。 |
在这些数据集上,LLaMA-3确实有很好的成绩,但这里面其实有几个点需要注意
- Meta在他的原文中说到了,由于现在数据集过多,有些评估数据也可能被混在了训练集中,所以这个Benchmark比较好,可能只是模型拟合了这些数据;
- 很多Benchmark是建立在5-shots上的表现,这和实际场景非常不符,因为实际用户使用大部分都是zero-shot,最多有1-2个shots,所以这个Benchmark是跟实际体验有出入的;
-
Meta自己也意识到了这个问题,因此他们自己组织了一个1800条数据的Benchmark,这个数据集是全程保密的,连做这个模型的人也访问不到。

因此我们看到,对自己产品特别严肃,要求很高的公司,都在构建自己的Benchmark。这些Benchmark最好是闭源的,在某种程度上才能保证没有人在这些评估数据上做了训练,得到公平的评估结果。
最近看到了智谱AI的Superbench团队也在做类似的事情,我总结了下,主要有以下几个评估大类。
| Benchmark | 描述 | 亮点 |
|---|---|---|
| 语义评测 | 名称:ExtremeGLUE。内容:是一个包含72个中英双语传统数据集的高难度集合,旨在为语言模型提供更严格的评测标准,采用零样本 CoT 评测方式,并根据特定要求对模型输出进行评分。我们首先使用了超过 20 种语言模型进行初步测试,包括了 GPT-4、Claude、Vicuna、WizardLM 和 ChatGLM等。基于所有模型的综合表现,决定了每个分类中挑选出难度最大的10%~20%数据,将它们组合为”高难度传统数据集”。 | 1. 中英都有 2. zero-shot评估 |
| 代码评测 | NaturalCodeBench(NCB)是一个评估模型代码能力的基准测试,传统的代码能力评测数据集主要考察模型在数据结构与算法方面的解题能力,而NCB数据集侧重考察模型在真实编程应用场景中写出正确可用代码的能力。所有问题都从用户在线上服务中的提问筛选得来,问题的风格和格式更加多样,涵盖数据库、前端开发、算法、数据科学、操作系统、人工智能、软件工程等七个领域的问题,可以简单分为算法类和功能需求类两类。题目包含java和python两类编程语言,以及中文、英文两种问题语言。每个问题都对应10个人类撰写矫正的测试样例,9个用于测试生成代码的功能正确性,剩下1个用于代码对齐。 | 1. 真实编程问题,比GPQA的要更加全面 |
| 对齐评测 | AlignBench旨在全面评测大模型在中文领域与人类意图的对齐度,通过模型打分评测回答质量,衡量模型的指令遵循和有用性。它包括8个维度,如基本任务和专业能力,使用真实高难度问题,并有高质量参考答案。优秀表现要求模型具有全面能力、指令理解和生成有帮助的答案。“中文推理”维度重点考察了大模型在中文为基础的数学计算、逻辑推理方面的表现。这一部分主要由从真实用户提问中获取并撰写标准答案,涉及多个细粒度领域的评估: ● 数学计算上,囊括了初等数学、高等数学和日常计算等方面的计算和证明。 ● 逻辑推理上,则包括了常见的演绎推理、常识推理、数理逻辑、脑筋急转弯等问题,充分地考察了模型在需要多步推理和常见推理方法的场景下的表现。 |
|
| 智能体评测 | AgentBench是一个评估语言模型在操作系统、游戏和网页等多种实际环境中作为智能体性能的综合基准测试工具包。 代码环境:该部分关注LLMs在协助人类与计计算机代码接口互动方面的潜在应用。LLMs以其出色的编码能力和推理能力,有望成为强大的智能代理,协助人们更有效地与计算机界面进行互动。为了评估LLMs在这方面的表现,我们引入了三个代表性的环境,这些环境侧重于编码和推理能力。这些环境提供了实际的任务和挑战,测试LLMs在处理各种计算机界面和代码相关任务时的能力。 游戏环境:游戏环境是AgentBench的一部分,旨在评估LLMs在游戏场景中的表现。在游戏中,通常需要智能体具备强大的策略设计、遵循指令和推理能力。与编码环境不同,游戏环境中的任务不要求对编码具备专业知识,但更需要对常识和世界知识的综合把握。这些任务挑战LLMs在常识推理和策略制定方面的能力。 网络环境:网络环境是人们与现实世界互动的主要界面,因此在复杂的网络环境中评估智能体的行为对其发展至关重要。在这里,我们使用两个现有的网络浏览数据集,对LLMs进行实际评估。这些环境旨在挑战LLMs在网络界面操作和信息检索方面的能力。 |
|
| 安全评测 | SafetyBench是首个全面的通过单选题的方式评估大型语言模型安全性的测试基准。包含攻击冒犯、偏见歧视、身体健康、心理健康、违法活动、伦理道德、隐私财产等。 |
在所有给定的Benchmark里,我认为最有亮点的是
- 智能体评测。最近很多大佬,尤其是吴恩达,疯狂给Agent站台,一个大语言模型能否真的在实际应用中取得效果,很大程度上来自于和Agent相关的能力,比如意图识别,工具选择是否准确等。SuperBench在这个潜力最大的应用上Benchmark,可见他们的野心不小。
- 中文语料库评测。太多的大语言模型都跑的是英文的评估集,在中文上的能力到底如何,才是对国内开发者更重要的,SuperBench在这里的评估确实是非常有先见之明的。
在这里我贴一些SuperBench的评估结果,大家可以参考下。
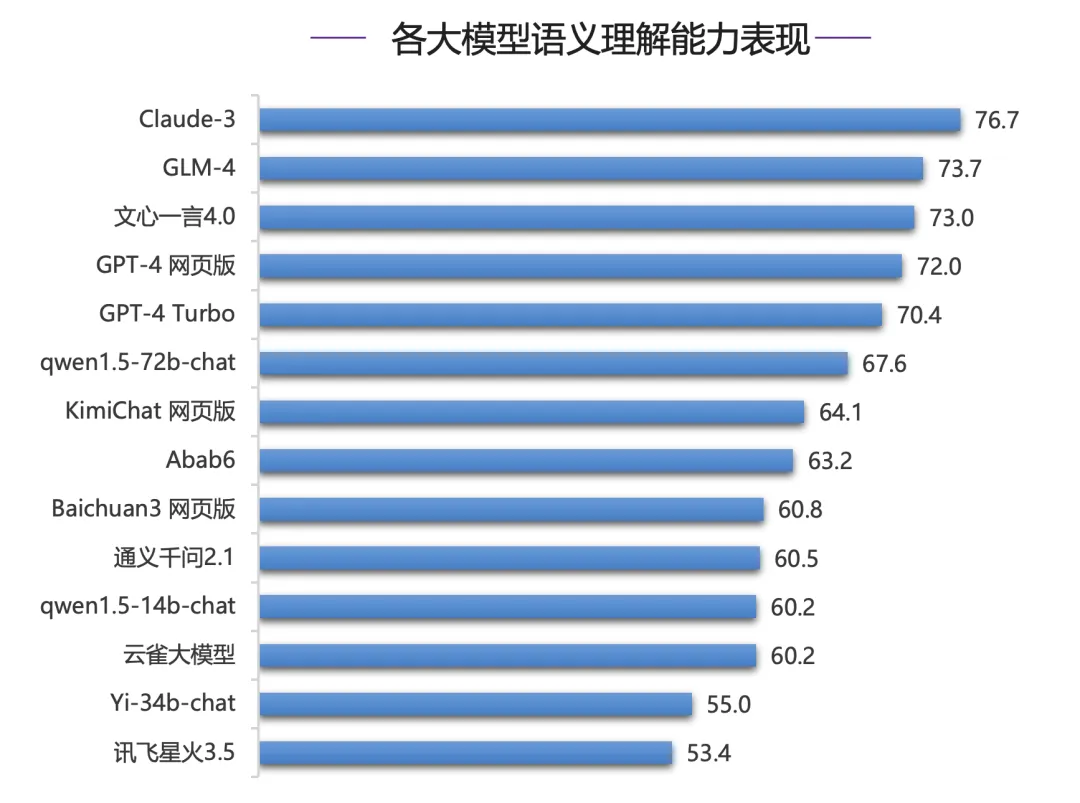
我们可以看到GLM-4的智能体能力在中文领域里是最好的,我们就来测试一个实际场景,对于我而言,我就测试小红书文案编写能力。
我的要求是,要根据SuperBench对LLaMA-3的测评结果,写一个爆款文案。下面是GLM-4给我的回复。
惊不惊喜,我文章的开头,就是完全复制了GLM-4给我的答案。而我的正文,就是参考了他的优化建议,加入了更多测评的细节,并用一些逻辑串联起了行文。

看了我的文章,你觉得如何?欢迎在评论区告诉我~