DeepSpeed
这篇文章主要回答
- DeepSpeed要解决什么问题?
- DeepSpeed如何解决的问题?
- 如何部署DeepSpeed进行训练?
- 相比于其他训练方式DeepSpeed有什么优势?
- 还有哪些训练框架?
DeepSpeed要解决什么问题
为了解决千亿甚至万亿大模型的训练问题,因为这种大模型训练通常需要占用巨大的显卡内存,因此很可能拥有的设备根本训练不起来,即使训练起来了,也可能速度很慢。
如何对训练的效率进行衡量?
训练的内存占用如何计算
1.5B参数量的大模型,如果精度是FP16(单个参数占用2bytes),则模型内存占用为2x1.5=3B,如果用Adam Optimizer + 混合精度训练1,模型存储自身参数+梯度,就变成了3B+3B=6B,混合精度训练相加时,又需要FP32的拷贝(momentum+variance)即4x1.5(原模型参数)+4x1.5(momentum) + 4x1.5(variance)=12B,加上自身参数和梯度,共16x1.5B=24G。所以1.5B参数量的模型,训练就需要24G内存。
训练速度如何衡量
FLOPS来衡量,就是每秒可进行的浮点数计算。
DeepSpeed如何解决问题
常见优化手段
- Data Parallelism(数据并行):每个GPU都存储一个模型,不会减少每个GPU的Memory使用,只能提升训练速度;
- Pipeline Parallelism(流水线并行):一个GPU装不下一个模型,但装得下一层或者多层,因此把同一个模型拆开训练;
- Tensor Parallelism(张量并行):每个张量被拆分成多个块,因此不是整个张量驻留在单个GPU上,而是张量的每个分片驻留在指定的GPU上。在处理过程中,每个分片都在不同的GPU上单独并行处理,结果在步骤结束时同步。
流水线并行和模型并行的概念似乎是等价的,好处是能开起来训练了,坏处是训练速度和通信强相关,会显著变慢。
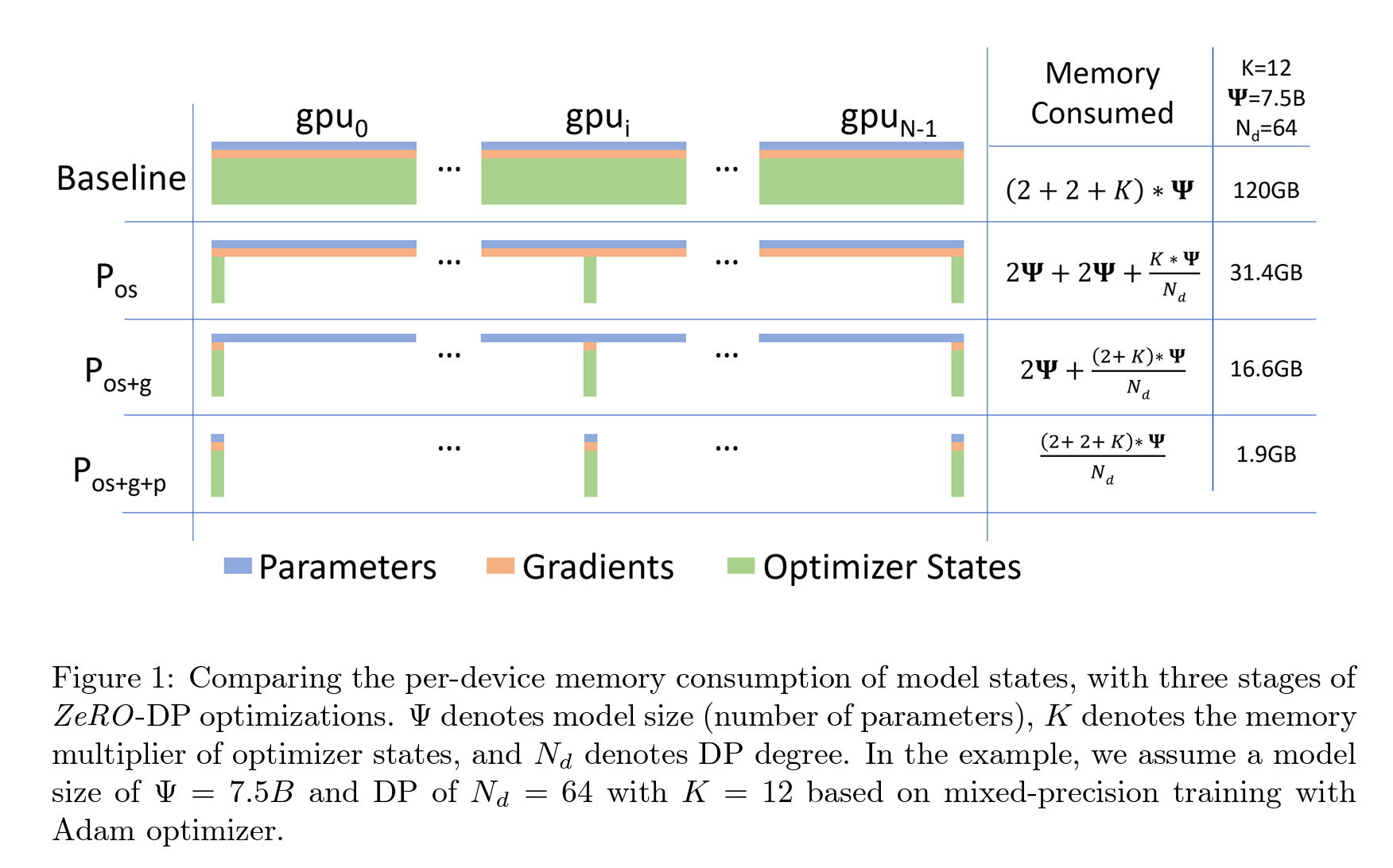
DeepSpeed的优化手段
DeepSpeed主要关注在Data Parallelism,这样不存在模型并行时候存在的更新通信速度问题。在解决DP问题的时候,DeepSpeed主要是把Model states进行分片,而不是复制。
DeepSpeed共有三个级别,分别能实现三种级别的内存效率。
- 一级:优化器状态分片
- 二级:梯度分片
- 三级:参数分片
https://github.com/microsoft/DeepSpeed/issues/3889
PREVIOUSAI算法