混合精度训练
==方法提出的背景是什么?==
模型参数的增加,带来了准确度上的提升,Benchmark的提升,但是训练要求的显存也显著增大。如何在模型参数变多下,减小训练内存的使用,同时保证一定的训练精度?
必要背景知识
- AdamW优化器
原本的Adam优化器是AdamW的前身,它是RMSprop和Stochastic Gradient Descent (SGD) with momentum1这两个方法的结合版。
- Adam优化器如何工作
- AdamW如何工作
现在基本上大模型训练都使用AdamW,AdamW的核心是,L2正则化
- L2正则化的引入主要和过拟合相关,超多参数易导致过拟合。过拟合的==表现形式==模型学到了训练数据中的噪声,从而不能泛化到没有看到过的数据中。过拟合的==Root cause==是,模型的复杂度过高(参数过多),导致模型能够通过调整参数学到非常细小的数据噪声。训练过程中,一些==可能的操作导致其过拟合==,分别是①数据维度:训练数据过少;特征过多;特征的维度过高;②模型维度:模型参数过多;③训练过程:训练了太多的epoch。==解决方案==是,分别可以对应到解决其中的操作问题,在大模型的场景下,①和②的问题不太存在,主要通过L2正则化的方法来惩罚权重过大的参数。
- AdamW优化器的内存占用
AdamW优化器需要保存两份状态
- Ranning average of gradients(和参数的数量一致)
- Running average of squared gradients(和参数的数量一致)
加上模型自身的参数数量,所以需要存储三份状态,两份来自于优化器,一份来自于模型本身。
混合精度的核心原理是什么
在训练时的运算尽可能使用低精度。
整体的架构:
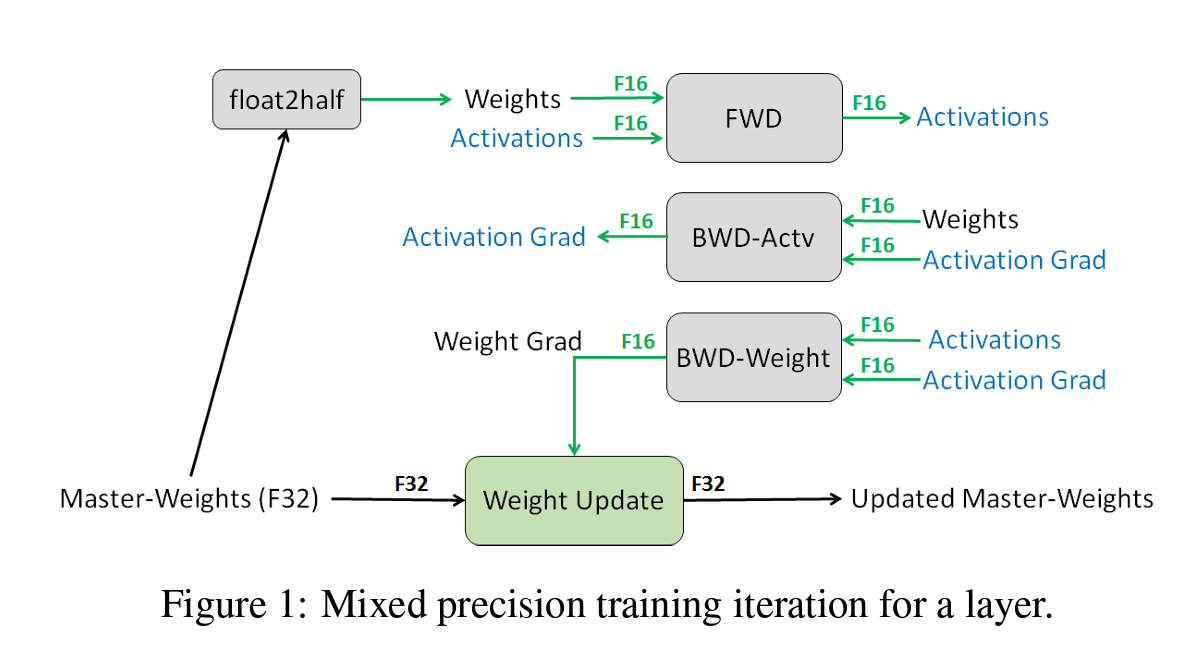
三个核心解决办法
- 存储一份FP32的单精度权重作为master copy,防止权重更新时候的梯度丢失;
- 通过放缩Loss,来保证FP16的半精度权重的丢失问题;
- 使用半精度计算partial product但是积累成单精度结果;
其中1、2和3都是在解决半精度梯度更新时候的梯度丢失问题(underflow)。
1就是简单的加了一个原本权重的master copy,很好理解;
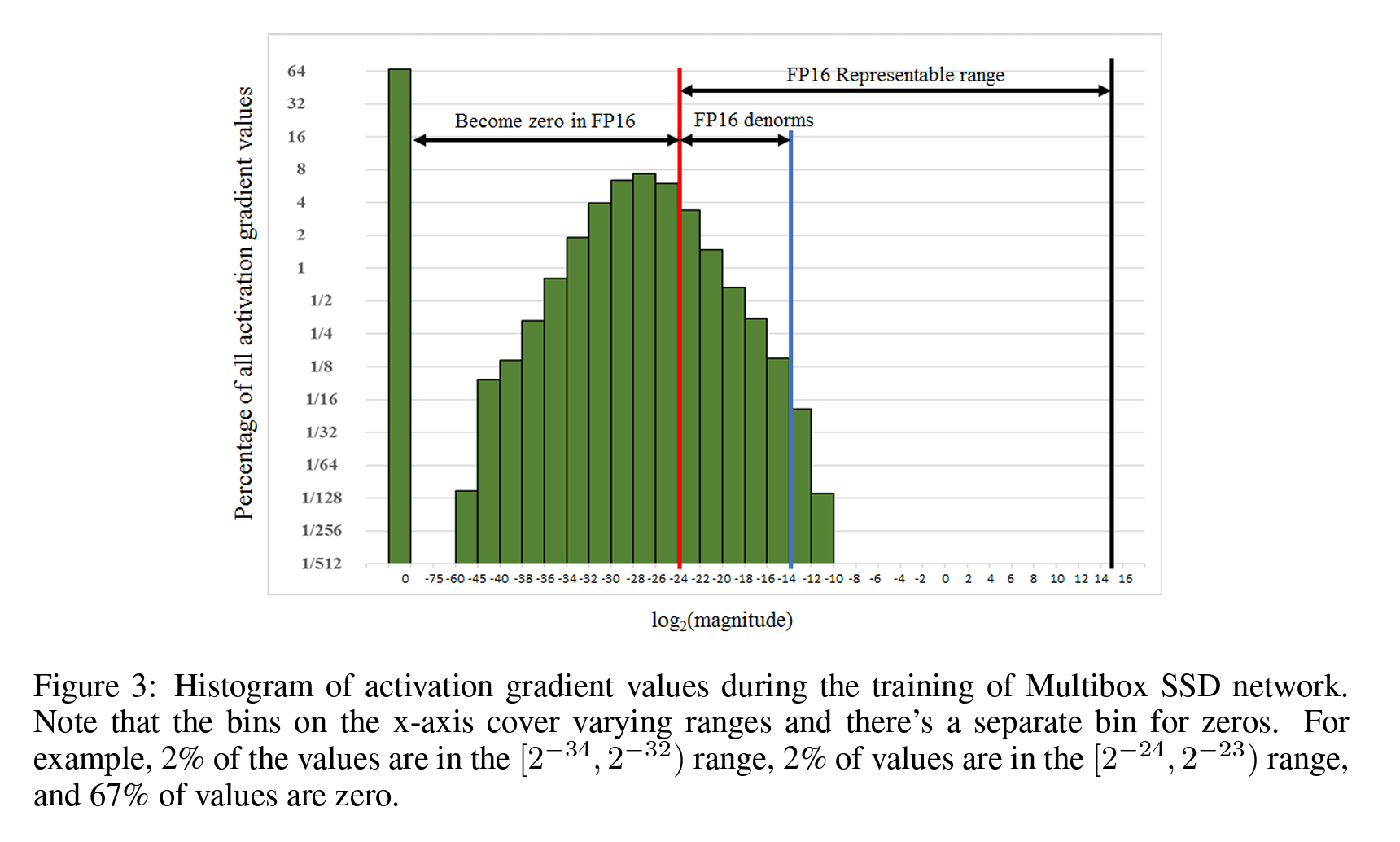
2就是通过移位的方法来扩展FP16能够表示的范围。引入了一个Loss Function的scaling factor,简单来说就是直接在计算FP16的时候乘上一个常数,放大FP16防止精度丢失,更新完后立刻在放缩回来。比方说下面这张图,作者把(-15,15)范围的原本的FP16右移几位即可。
3主要是在计算矩阵乘法的时候,dot product出来的每个子项(partial product)用FP32表示,算完加法后,再存储成FP16的格式。核心思想还是在考虑了整个运算过程中可能产生哪些underflow,并处理好这些underflow。
细节问题
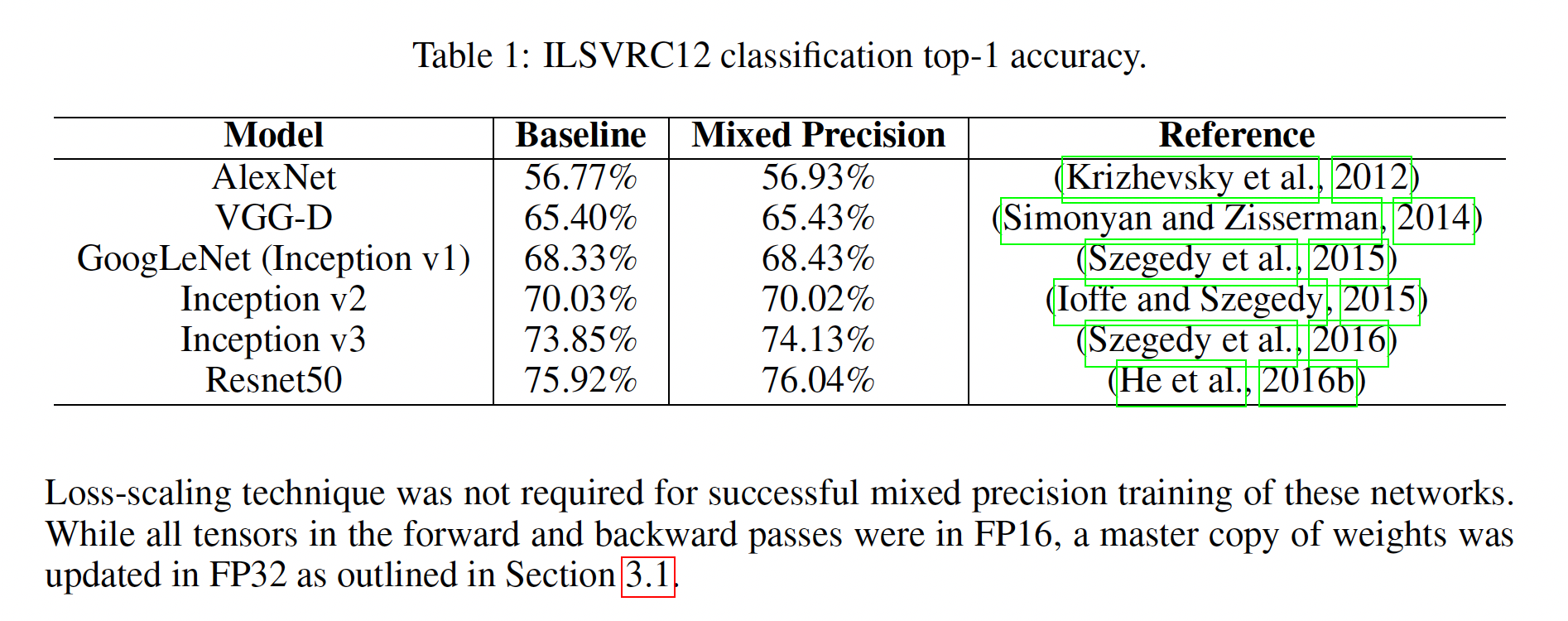
- mixed precision training的整体效果?
Top-1准确度都没有明显下降,都在正常的波动范围内。
- 能节省多少内存?
除了存储了一份模型的master copy是FP32没有变之外,其他全都是FP16的形式进行存储。计算时,占用Memory的主要是Activation,Gradient和Weights。Activation训练时占用60-80%显存,Gradients占用20-30%,Weights占用5-10%,因此整体能够节约一半的训练显存。