Internlm-xcomposer 2结构详解
- 有用指数:⭐️⭐️
- 贡献程度:⭐️
- 简单评价:引入了新的架构进行模态对齐,该模块的intuitive没讲清楚,没有详实的ablation分析,现有问题分析不够明确,改进不够有针对性,看上去是没想清楚的暴力尝试,比如提升分辨率可能有用?改对齐模块可能有用?最终可能是都没用,就是暴力加数据最有用。
原文地址:https://arxiv.org/pdf/2401.16420
Existing Gap
作者认为,现在的VLLM任务还有一个没怎么探索明白的方向,就是怎么做模态对齐。目前业界对齐模态时对待Visual Tokens通常有两种方法,作者认为他们各自都有弊端。
- 平等对待Visual Token和Language Token,这样做忽略了两个模态之间本身的巨大差异;
- 认为不同模态是不同的实体,这样做会增加对齐成本。
Contribution
基于以上的Gap,作者认为自己做了两点贡献。
- 提出了一个PLoRA的结构,把image Token经过LoRA Module转化后再和Language Token结合在一起,这样就没有简单的把Image Token和Language Token进行混合;
- 组织了高质量,丰富的训练数据集。
看到这里个人有两个疑问
- 大部分工作(LLaVA除外)都没有把Image Token和Language Token等价,都还是使用了Q-former等结构对齐过的,所以文中提到的忽略模态差异,到底是什么差异?谁在忽略差异?
- 第二,即使这个差异被忽略了,==有业界共识或者实验表明,这个差异是不可忽略的吗==?LLaVA这个结构真的不好吗?如果不好为什么Benchmark呈现的结果还行?
Method
作者提出的PLoRA结构
这个PLoRA结构,把原来LM的每一层预训练的权重换成了Low Rank Adaptor \(\begin{align*} \hat{x}_t &= W_0x_t + B_0 \\ \hat{x}_v &= W_0x_v + W_BW_Ax_v + B_0 \\ \hat{x} &= [\hat{x}_v, \hat{x}_t] \end{align*}\)
[!TIP]
拓展知识
由于这个LoRA的adaptor是原来语言模型拓展出来的,所以可以按照计算LoRA的Memory saving来计算这个Adaptor节省的内存。比如,按照LoRA的公式: \(\begin{equation} h = W_0x + \Delta Wx = W_0x + BAx \end{equation}\) 原本的权重$\Delta W$可以被拆解为两个低秩矩阵的乘积,如果两个低秩矩阵的秩足够低,那么理论上LoRA的参数可以无限小。
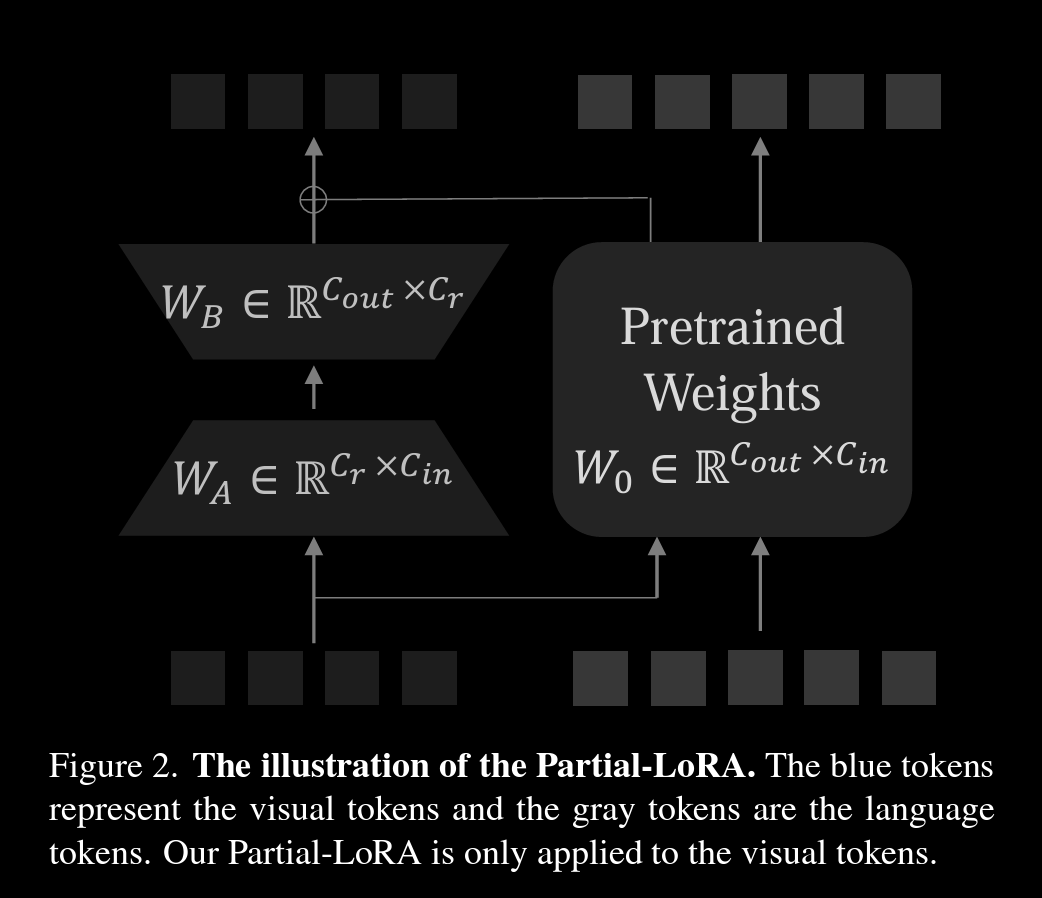
==几个疑问==
- 为什么要引入一个类LoRA结构的模块来处理Visual Token?个人猜测是,从训练角度,LoRA和Q-former都可以算作对齐模块,且微调参数可以控制;从实践角度,LLM已经证明了Fine-tune LoRA可以实现部分SFT的效果,所以拿来做对齐也是可以尝试的选项。
训练过程
- 预训练:LLM的参数全程Freeze住,调整Vision Encoder和PLoRA的参数。预训练的能力主要由训练数据保证,数据的组织主要有几个目标
- 基础语义对齐(General Semantic Alignment):比如图片里有什么物体等,主要用Image<>caption数据。
- 整体知识认知(World Knowledge Alignment):比如图片中包含的物体和对物体一些描述(动作,语言,简介)
- 视觉基础能力(Vision Capability Enhancement):比如OCR,Grounding的一些能力。
- 预训练的数据集组织:

- SFT:针对下游任务组织了数据微调,主要是QA多轮对话,Instruction数据,文本图片组合等。
- SFT的数据集组织:

- 引入了10%的Internlm2的训练数据来维持Language Model的能力。
- SFT的数据集组织:
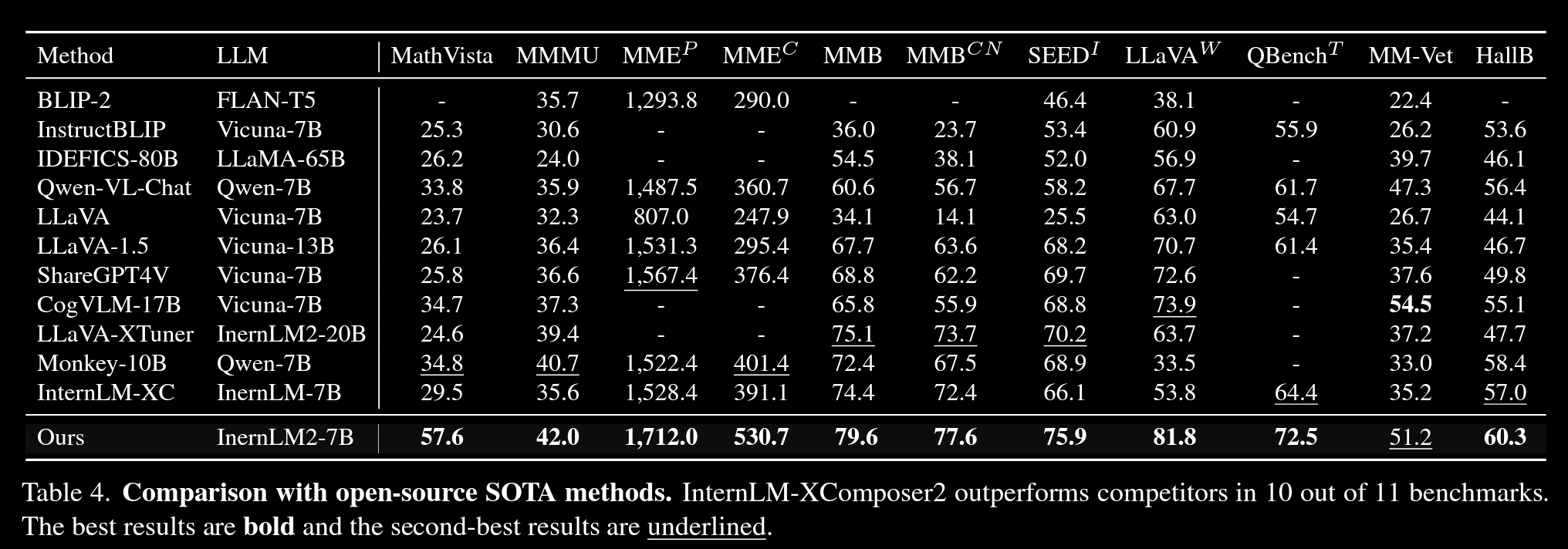
整体效果
在7B模型的范围里,取得了一些SOTA的结果。
PREVIOUSAI算法