MiniGPT-4 详解
- 时间:2023.4.20
- 作者团队:King Abdullah University of Science and Technology
- 作者:一作朱德尧,现在字节,一直做的都是视频/图像内容理解相关工作。
- 有用指数:⭐️⭐️⭐️⭐️⭐️
- 贡献程度:⭐️⭐️⭐️
- 简单评价:这篇文章的方法没什么特别大创新,但是做了非常多实验,总结了非常多的经验,虽然有选取对自己有利的评估结果的嫌疑,但瑕不掩瑜,Ablation做的还是非常好的,对未来发展方向有两个特别大的Learning
- ==高质量数据非常关键,质量 » 数量==;
- ==模态对齐模块不一定要复杂,数据才是关键==。
原文地址:https://arxiv.org/abs/2304.10592
Existing Gap
23年早期的文章,还在探索GPT-4v的图像语言能力的来源,他们的目标就是尽可能复现GPT-4V的图片理解语言能力。
Contribution
- 用Vicuna这些有强大语言能力的大模型来对齐视觉特征,能够有效激发Image understanding的能力;
- 一个projection layer就能实现很强大的功能;
- ==使用短的Image caption数据来对齐视觉特征是不够的,必须使用更多小的但是细节更丰富的description才能远远提升其能力。==
Method
作者提出了一个非常简单但有效的结构:直接在BLIP-2的Q-former后面接一个projection layer,Training的时候只更新这个小projection layer的参数,其他视觉模块和语言模块都是完全不更新的。
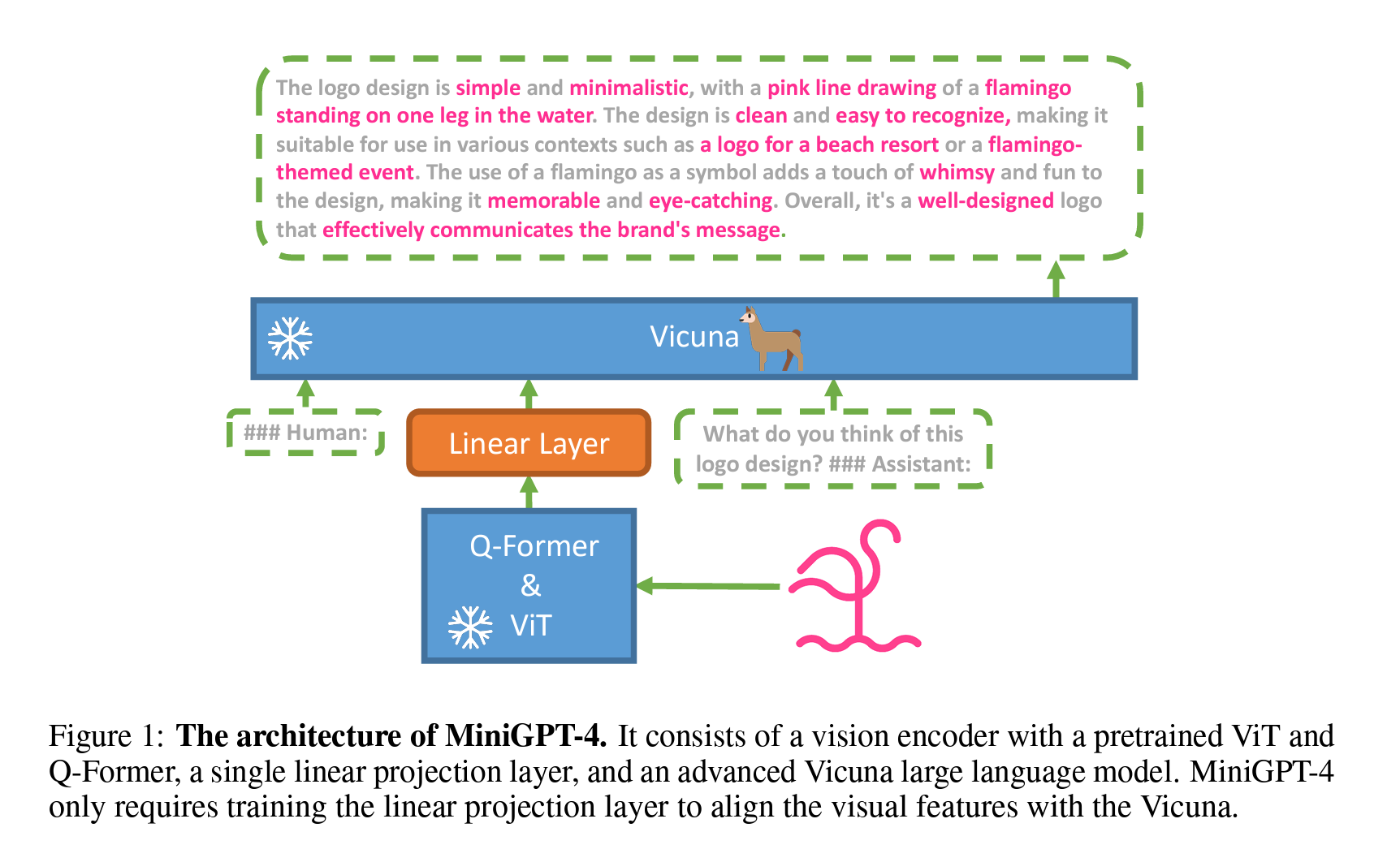
[!NOTE]
几个疑问
疑问 回答 只用projection layer方法的多模态在LLaVA中试验过了,是比较有用的,但LLaVA还更新了LM的参数,这个没有,性能上会有差距吗? 个人认为在图像多轮对话上的能力肯定是逊色于LLaVA的,因为LLaVA用图片多轮对话训练过LM,肯定是有性能提升的。但是图像理解能力可能差距不大,或者MiniGPT-4还更好点。
训练过程
- 第一阶段
- 用Image<>caption pairs进行训练,==只更新Linear projector的参数==。这步训练完发现模型能够给出一些合理的返回,但是会有重复说话,句子碎片化,输出不相干等问题(这也是多模态大模型的常见问题了)。
- 为了解决这个问题,作者首先进行了==更多的数据构造==。构造主要是产出对==图片更详细的描述==,而不是简单的caption,可以理解为,作者在构造image<>description pairs。构造的方法有两种
- 基于之前训练好的,能力不太行的模型版本,用==多轮对话的方法==让模型继续生成结果,直至完整。多轮对话就是在模型第一轮回复以后,在第二轮加上continue这个prompt,就像这样:
###Human: Continue ###Assistant: - 基于生成更详细描述,再对这部分数据用GPT-3.5后处理,主要是为了修复里面可能产生的语法错误等。prompt:
Fix the error in the given paragraph. Remove any repeating sentences, meaningless characters, not English sentences, and so on. Remove unnecessary repetition. Rewrite any incomplete sentences. Return directly the results without explanation. Return directly the input paragraph if it is already correct without explanation.
- 基于之前训练好的,能力不太行的模型版本,用==多轮对话的方法==让模型继续生成结果,直至完整。多轮对话就是在模型第一轮回复以后,在第二轮加上continue这个prompt,就像这样:
- 第二阶段:
- 做完以上两步后,作者进行了第二阶段的fine-tuning,这里也是优化Generation Loss,用
describe this image to me作为prompt进行调整,依然只训练Linear Projector。做完之后效果有显著提升。
- 做完以上两步后,作者进行了第二阶段的fine-tuning,这里也是优化Generation Loss,用
实验结果
-
stage-2之后的效果:
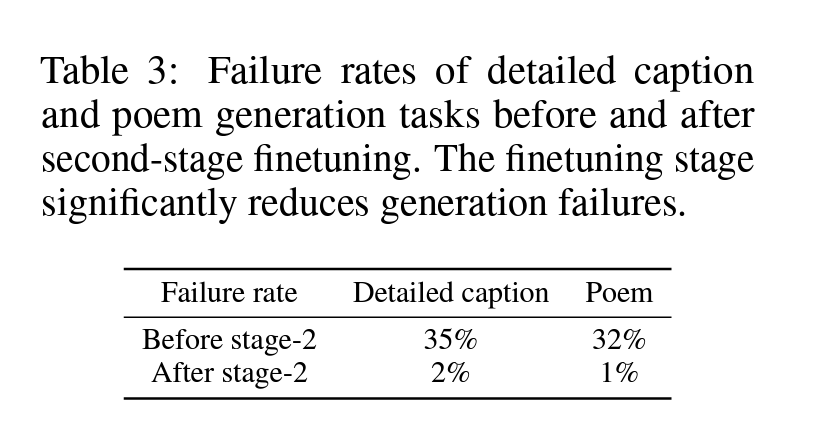
- 那么这个stage-2的效果提升,对其他模型是否有效呢?由于作者是基于BLIP-2的架构进行的,那BLIP-2是否有类似提升呢?作者表示这里有提升,但是benefit没有MiniGPT-4大,这里非常有意思,==作者没有进行Quantitative的分析,只进行了qualitive的分析==。可能是cherry-pick了一些对自己有利的结果展示,BLIP-2也有很大的提升。
- 那么除了fine-tune新加的Linear layer,fine-tune其他的模块有用吗?作者设计了三个实验
- 移除Q-former,直接用Projector map ViT的特征到Vicuna;
- 用三层MLP,而不是一层;
- Fine-tune Projector的同时也fine-tune Q-former
- 结果如下:
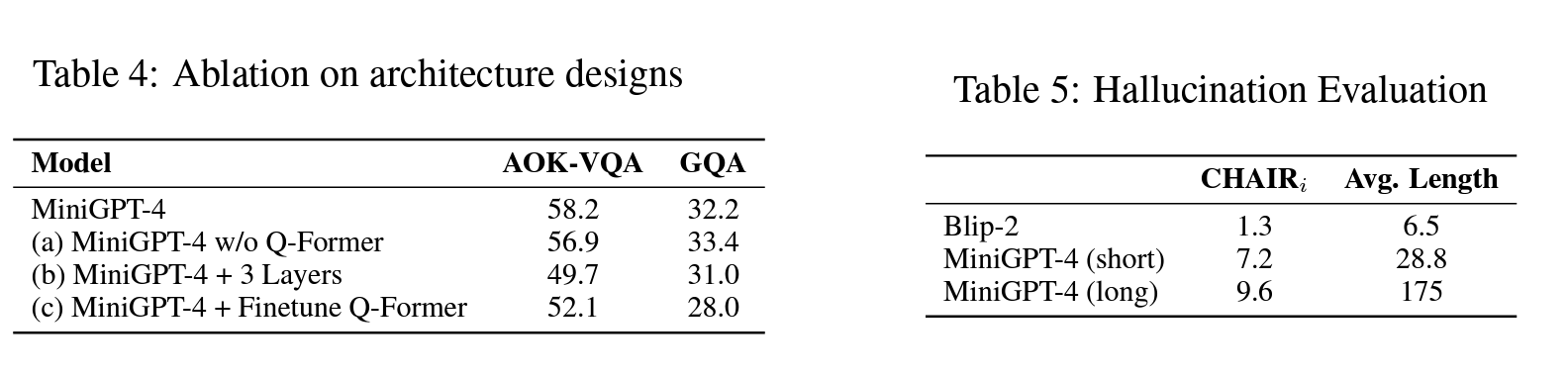
这个结果非常有意思,说明
- 复杂的Q-former结构对alignment帮助不一定大,一层MLP Projector足矣;
- 深层MLP映射不一定有用;
- 原本Align过的Q-former如果在小的数据集上fine-tune,效果甚至可能适得其反。
总结
总的来说,这篇文章的方法没什么特别大创新,但是做了非常多实验,总结了非常多的经验,虽然有选取对自己有利的评估结果的嫌疑,但瑕不掩瑜,Ablation做的还是非常好的,对未来发展方向有两个特别大的Learning
- ==高质量数据非常关键,质量 » 数量==;
- ==模态对齐模块不一定要复杂,数据才是关键==。
PREVIOUSAI算法