VQ-VAE 详解
- 时间:2017.11.2
- 作者团队:DeepMinds
- 作者:Aaron van den Oord, Oriol Vinyals, Koray Kavukcuoglu
- 有用指数:⭐️⭐️⭐️⭐️⭐️
- 贡献程度:⭐️⭐️⭐️⭐️⭐️
- 简单评价:开山鼻祖之作
背景知识
- VAE详解:https://towardsdatascience.com/understanding-variational-autoencoders-vaes-f70510919f73
VAE
Encoder-Decoder架构
Ilya曾说,压缩即智能。如果你能找到一个方法,有效地进行知识的压缩与还原,那么其本质与智能无异。大语言模型是通过next token prediction把一个概率模型压缩进了自己的参数里。而VQ-VAE也是信息压缩的一种方法。
对于LLM来说,一个Encoder-decoder架构的模型和下图的抽象无异
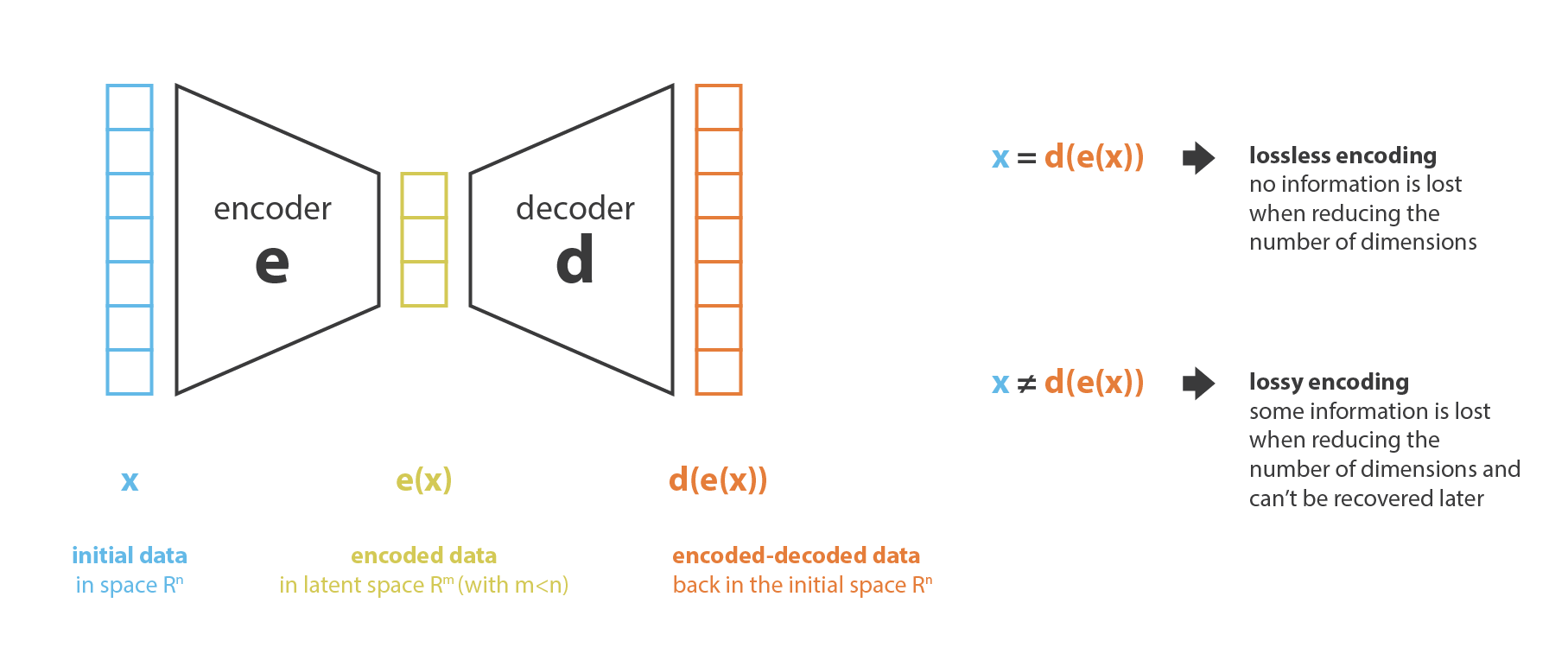
这里的压缩本质上是为了降低input数据的维度,把原本输入压缩到一个latent space,从这个角度讲,PCA(主成分分析)也是一种降维的方法,只是PCA是在一个线性空间中降维,而Encoder是用一个神经网络来模拟这个降维函数。
所有的都可以Encoder-decoder的模型都有正向encode成latent vector和从latent vector decode的过程,可以把这个过程用如下公式表达: \((e^*,d^*)=\underset{(e,d)\in E\times D}{\arg\min}\epsilon(x,d(e(x)))\) 这里面的$\epsilon(x,d(e(x)))$就是重建error。
对于PCA来说Encoder和decoder就是两个矩阵,decoder是Encoder矩阵的逆。
实际上,Encoder-decoder的Transformers也是信息压缩与重建的过程。
如何做生成
但目前为止只讲到了如何进行压缩和重建,那么如何进行生成任务?一个比较直白的想法是,假设我现在已经训练了一个Encoder和Decoder的神经网络,我只要想办法在latent space上sample一个vector出来,在用Decoder解压缩,是否就能生成出来新的?例如下图的实例
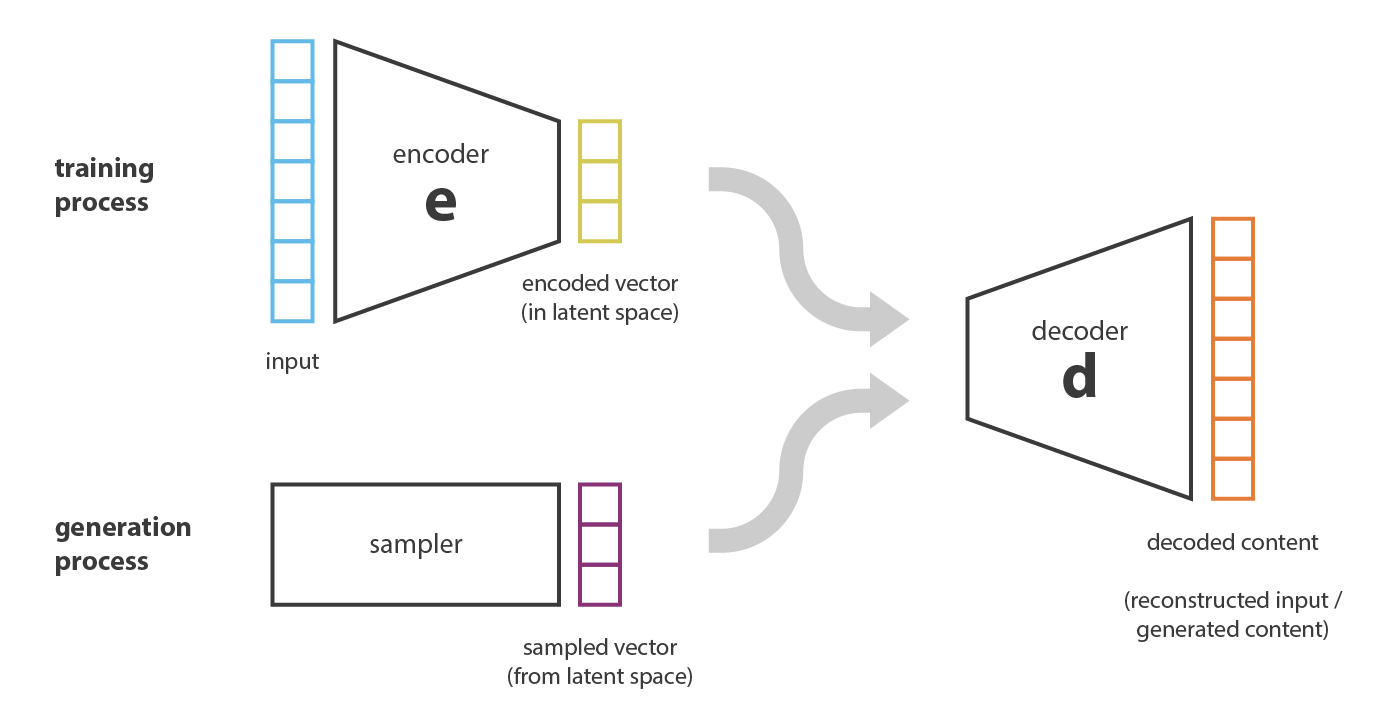
这样做虽然是可以的,但是这种OOD的情况模型是不认识这样vector,所以重建出来的结果基本上是不可用的。本质上就是模型overfit了,而且在这个架构下,overfit的问题基本上不可解。
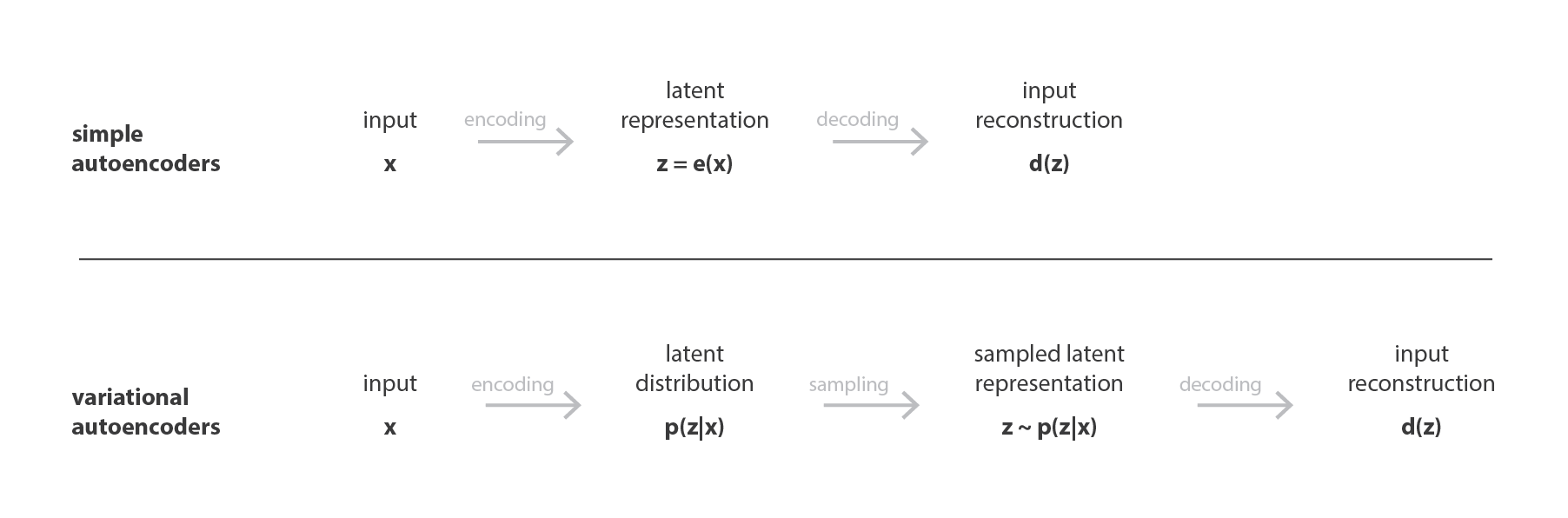
想到解决overfitting,一个很直白的想法就是做regularization。实际上,从autoencoder到variational autoencoder,再到vector quantized VAE,所有思想的根本都是如何对autoencoder做regularization。
Regularization - Variational
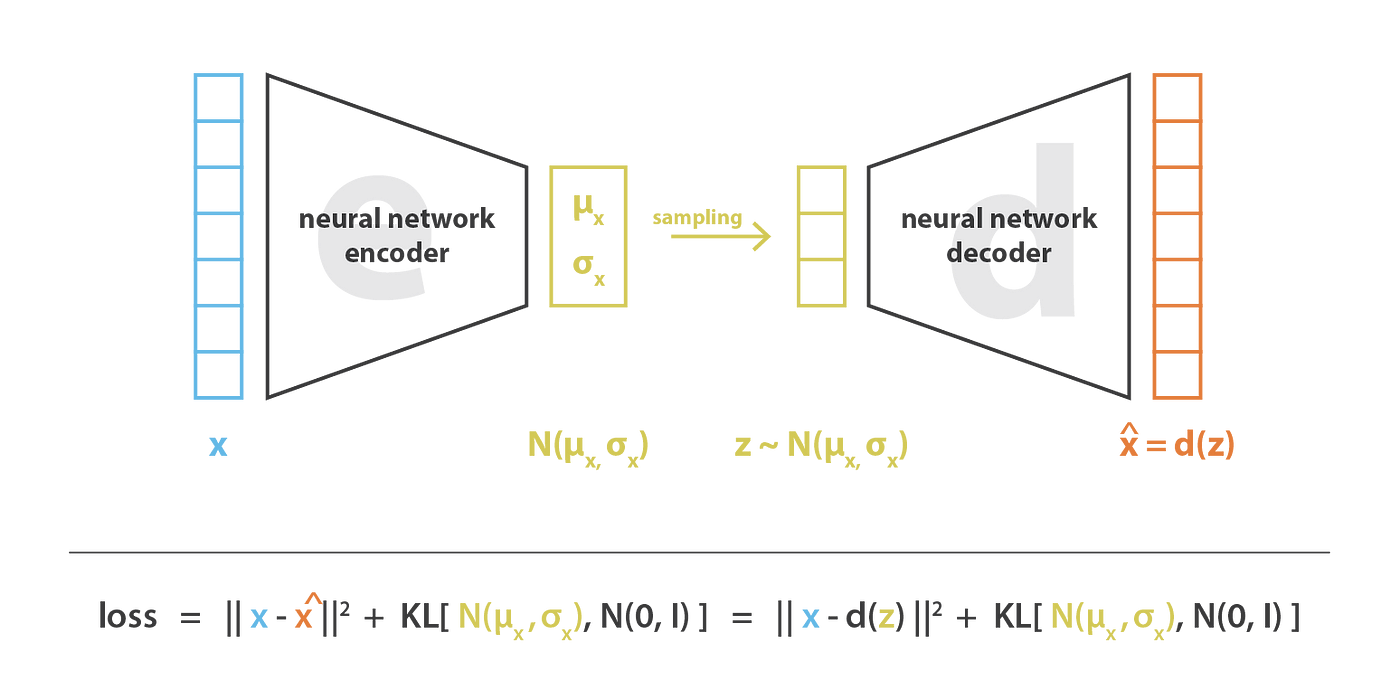
如上图所示,如果我们都需要从latent space中sample,那么是否可以直接学习一个robust distribution呢?Variational autoencoder的思路正是基于此。
VAE的训练过程会变成如下:
- 把input encode成latent distribution
- 从这个latent distribution里面sample出来一个点
- 对这个点计算reconstruction error并对神经网络进行反向传播。
为什么这样做好一些?由于这个点从固定的变成了从一个distribution里面sample,所以input并非定死的,增加了一定的鲁棒性。
但这里同样存在问题
- 从distribution sample的话,函数整体是不可导的,怎么进行反向传播?
- 单纯sample并不能解决overfit的问题,因为可能学到一个特别尖的高斯分布,这其实和传统的autoencoder没太大区别。
所以,VAE解决这两个问题的思路是
让这个distribution尽可能接近高斯分布:引入一个高斯分布和实际分布的KL divergence,并把这个divergence作为Regularization的term放到loss function里面;这个操作能同时解决上面两个问题,因为KL divergence是可以把loss function用连续解析解的形式表示出来的。