ViT - 拼接图片
- 标题:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale(Vision Transformer)
- 时间:2020.10.22
- 作者团队:Google
- 作者:Alexey Dosovitskiy
- 有用指数:⭐️⭐️⭐️⭐️⭐️
- 贡献程度:⭐️⭐️⭐️⭐️⭐️
- 简单评价:Transformer在视觉领域的应用,把image patch拼接成Sequence,实现类似NLP中的Next token prediction的效果,也是目前很多多模态大模型的Vision Encoder。
出发点
Transformer架构在NLP上呈现出了很强大的Scale的能力,在Vision领域还没有类似能够Scale的模型。但直接应用Transformer到Vision有几个问题
- 如果做pixel-level的Self Attention,一张图片的pixels是非常多的,而且随着分辨率的提升,计算复杂度成平方增长。
Contribution
- 证明了Large Scale Training的Vision Transformer同样能取得不错的效果;
- 能扩展到中型大小的图片分辨率(这不是废话吗,人家2x2的patch对比你这个16x16的patch,你肯定能适应更大的)
Method
模型的整体架构如下图所示
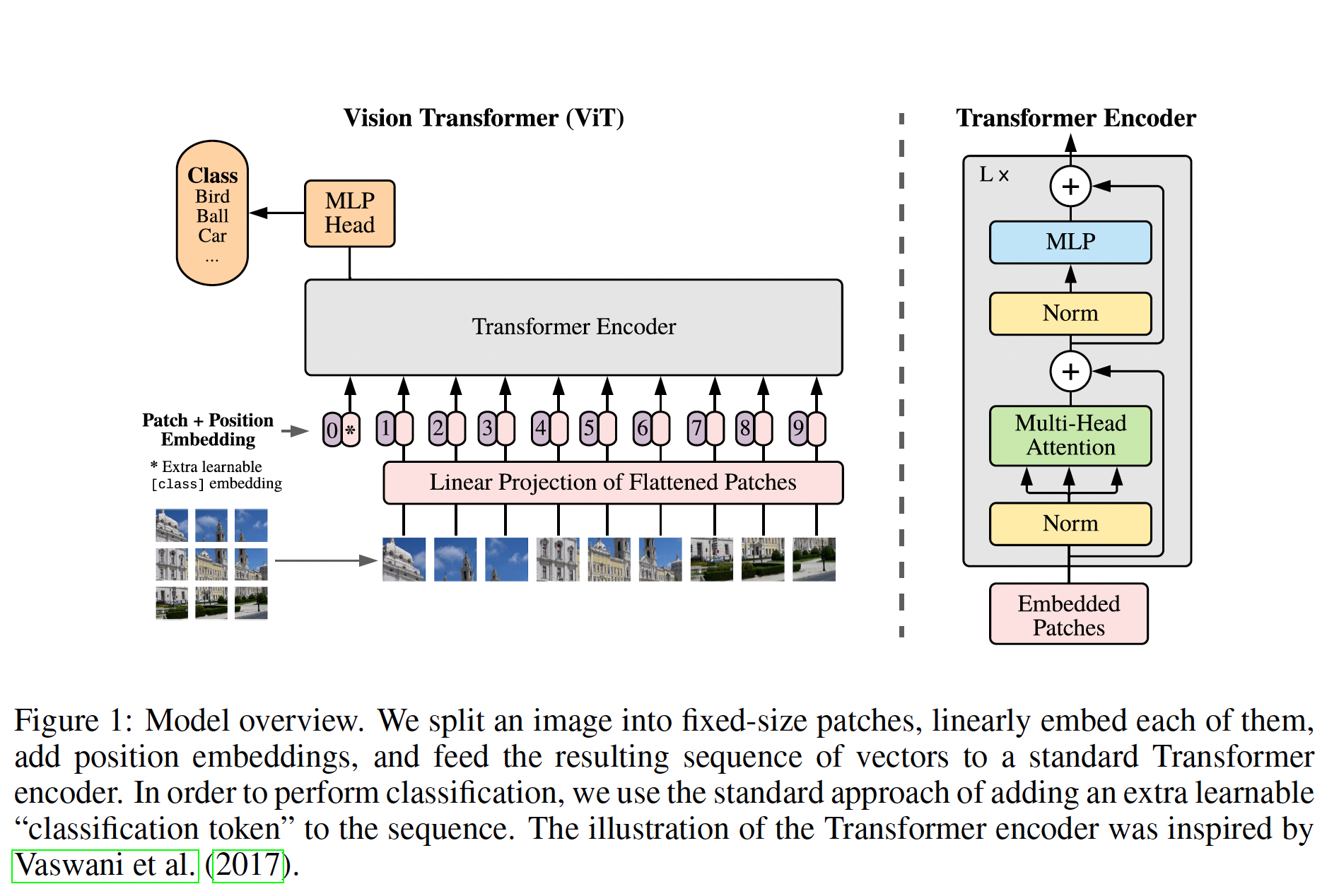
一张图片被切分成16x16大小的patches,这些patches会经过position Embedding后,和一个CLS Embedding拼接在一起,经过Transformer的Encoder后,可以被改造为一个针对不同下游任务的分类器。所以这是一个Encoder-only的Transformer架构。
主流程的代码实现,概述一下,
- Image通过一个Conv层,转化为Embedding
- 如果有classifier,则放在Image的前面(初始化是大小为h的全0 Embedding);
- 经过Transformer的Encoder;
- 如果是分类任务,则取出来Transformer Encoder最后一层的第一个元素,经过nn.Dense(),得到最后的概率(用于inference或者Training的backward)
和上面的架构图略有出入的是,positional Embedding其实是在Encoder里面做的,做的时候把所有的包括CLS Embedding都考虑在内了。
n, h, w, c = x.shape
# We can merge s2d+emb into a single conv; it's the same.
x = nn.Conv(
features=self.hidden_size,
kernel_size=self.patches.size,
strides=self.patches.size,
padding='VALID',
name='embedding')(
x)
# Here, x is a grid of embeddings.
# (Possibly partial) Transformer.
if self.transformer is not None:
n, h, w, c = x.shape
x = jnp.reshape(x, [n, h * w, c])
# If we want to add a class token, add it here.
if self.classifier in ['token', 'token_unpooled']:
cls = self.param('cls', nn.initializers.zeros, (1, 1, c))
cls = jnp.tile(cls, [n, 1, 1])
x = jnp.concatenate([cls, x], axis=1)
x = self.encoder(name='Transformer', **self.transformer)(x, train=train)
if self.classifier == 'token':
x = x[:, 0]
elif self.classifier == 'gap':
x = jnp.mean(x, axis=list(range(1, x.ndim - 1))) # (1,) or (1,2)
elif self.classifier in ['unpooled', 'token_unpooled']:
pass
else:
raise ValueError(f'Invalid classifier={self.classifier}')
if self.representation_size is not None:
x = nn.Dense(features=self.representation_size, name='pre_logits')(x)
x = nn.tanh(x)
else:
x = IdentityLayer(name='pre_logits')(x)
if self.num_classes:
x = nn.Dense(
features=self.num_classes,
name='head',
kernel_init=nn.initializers.zeros,
bias_init=nn.initializers.constant(self.head_bias_init))(x)
return x
训练过程
训练有两步,第一步是大规模预训练,第二步是finetune。
- Pretrain:大规模预训练的都是分类任务,这里的第一个loss是交叉熵loss,就是用上文提到的prediction head做的分类问题。
- Finetune:这步会把prediction head移除,同时加一个$D \times K$的FF layer,$K$就是下游任务的类别总和。在这一步一般会使用更高分辨率的图片。
实验设置
实验数据
| Dataset | size | Comment |
|---|---|---|
| ILSVRC-2012 ImageNet | 1.3M, 1k classes | |
| ImageNet-21k | 14M, 21k classes | |
| JFT | 303M, 18k classes | |
模型变种
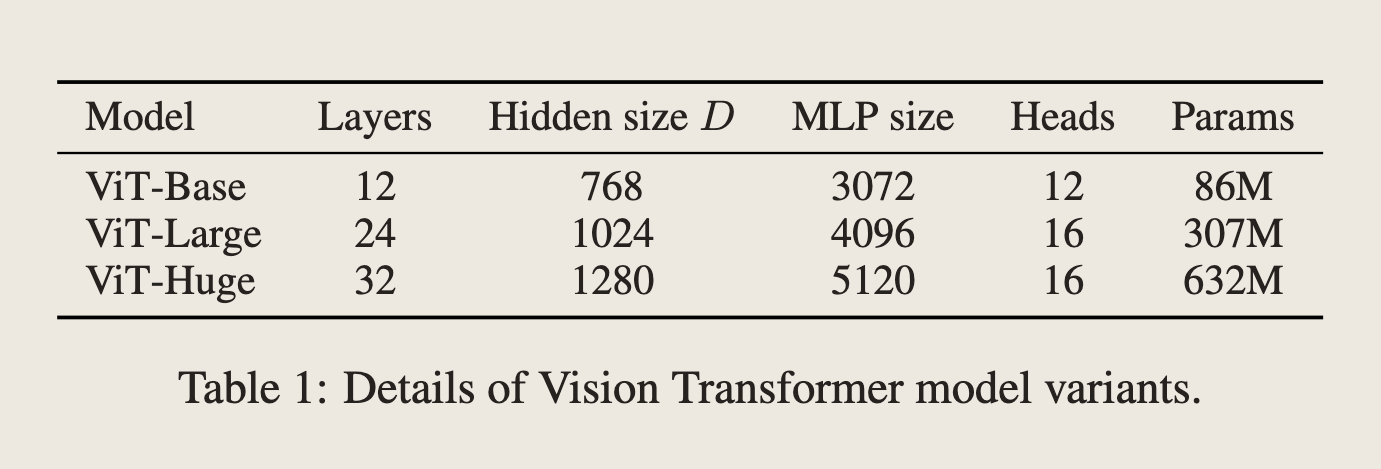
实验结果
在几个评估集上都取得了比ResNet更好的成绩。

Limitations
- 没有用Contrastive Learning的Objective来训练,未来会尝试;
PREVIOUSAI算法