MiniCPM-V2.6:面壁智能端侧图像大模型
- 标题:MiniCPM-V: A GPT-4V Level MLLMonYourPhone
- 时间:2024.8.03
- 作者团队:面壁智能
- 作者:Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui
- 有用指数:⭐️⭐️⭐️⭐️⭐️
- 贡献程度:⭐️⭐️⭐️⭐️⭐️
- 简单评价:
- 优点:代码完备,基本无缝在自建场景开启训练;可配置化图片占据的token数量,如果场景需要建模视频,可直接配置减少一张图片token数量。
- 缺点:目前只有和Qwen2对齐的节点,实际训练结果有些许不理想。
Existing Gap
作者认为现在模型参数都太大了,很难在端侧运行起来,于是他们的目标就是做一个小点的,能在quantize之后运行在端上且效果还不错的多模态大模型。
Proposed Solution
虽然目标是小模型,但是MiniCPM这次有在Qwen-2上训练的版本,本身并不算小,所以作者建议用Quantize之后的模型运行在端侧。本文的创新更多还是训练数据上的,其他方法是比较常见的。
目前大家做多模态大模型能够提升性能的常规操作是
- 提升训练时的图片分辨率;
- 加大训练数据的量;
- 调和训练数据的比例和优化训练过程。
MiniCPM的整体架构如下图所示
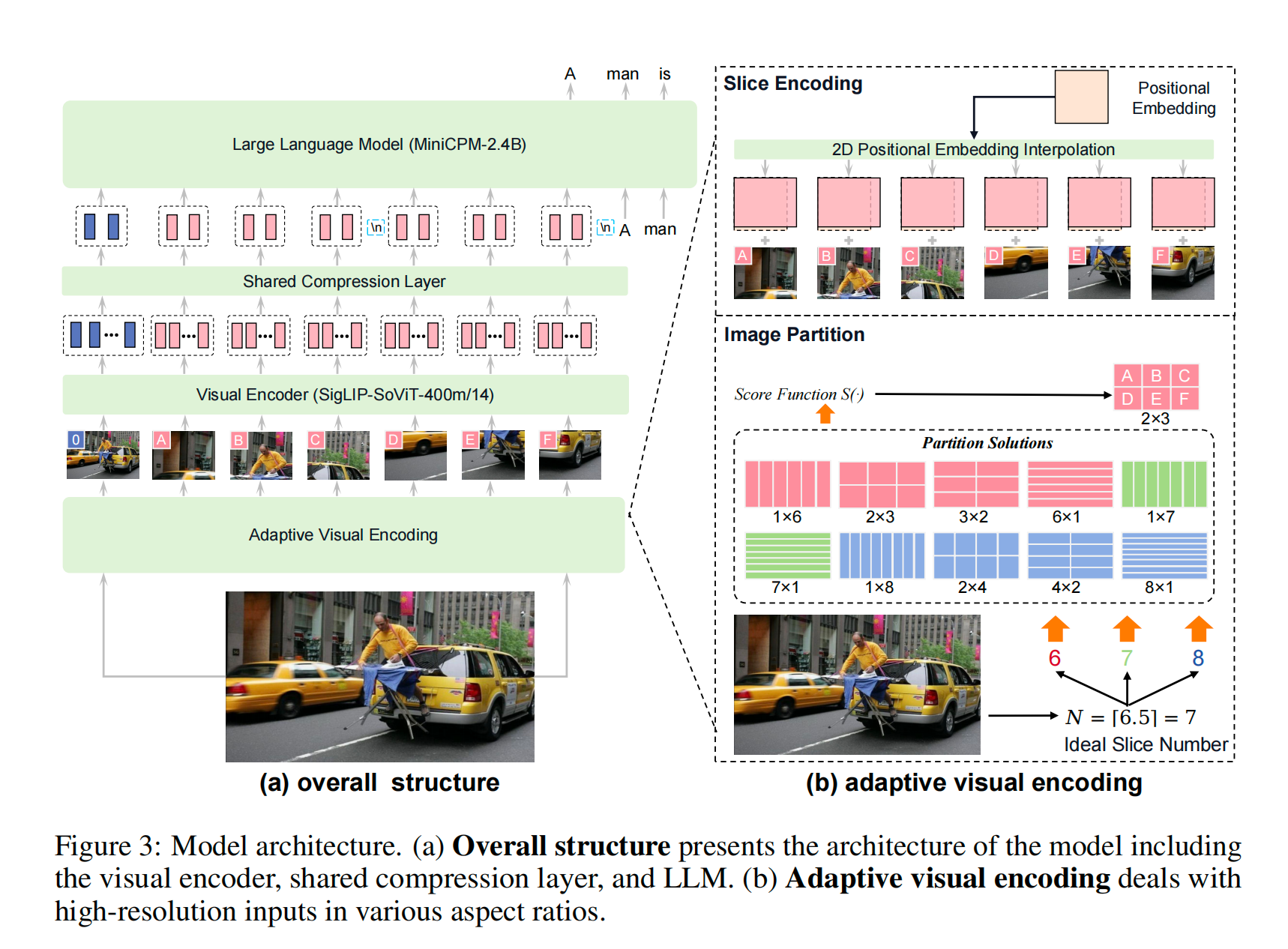
整体架构
- 图像切分(基本上对于高分辨率图片都得有类似步骤,比如LLaVA这里用的切分+pooling):使用adaptive visual encoding(下文会细讲)
- Visual encoder:ViT
- 模态对齐:一层cross-attention token压缩层对齐文本和视觉模态;
- LLM
实现细节
Adaptive Visual Encoding
如何能建模高分辨率图片?切分+合并。理想状态是,合理切分图片以对齐ViT预训练的分辨率。
for image in _images:
# 图片切分,默认配置最多切成9块
image_patches = self.get_sliced_images(image, max_slice_nums)
# 对patches进行normalization
image_patches = [to_numpy_array(image).astype(np.float32) / 255 for image in image_patches]
# standardization
image_patches = [
self.normalize(image=image, mean=self.mean, std=self.std, input_data_format=input_data_format)
for image in image_patches
]
# HWC转化成CHW,图像channel在前
image_patches = [
to_channel_dimension_format(image, ChannelDimension.FIRST, input_channel_dim=input_data_format)
for image in image_patches
]
# 合并成新的图像数组
for slice_image in image_patches:
# 每一张图都变成了多个小patches
new_images.append(self.reshape_by_patch(slice_image))
tgt_sizes.append(np.array((slice_image.shape[1] // self.patch_size, slice_image.shape[2] // self.patch_size)))
Compression layer
上面这种做法有个明显的坏处就是,如果是多图输入,明显这个输入被放大了很多,如果直接把原始结果给到LLM,那么能装下的图片数量肯定很少。所以作者在这里加了一个compression layer,主要目的就是压缩直接产出的token数量。(他们源码还没更新到最新的模型,所以如果看源码到Huggingface上面看)。这个compression layer就是一个单层的cross attention layer,一般来说Resampler架构的架构,cross attention模块都是更新learnable Query。MiniCPM-V2.6在Qwen2 LM上默认对齐的Query embedding的size是64,就是一组slice(单张图)占用64个tokens。
训练过程
| Training | Stage | 目的 | Trainable modules | Data |
|---|---|---|---|---|
| Pretraining | 1 | warmup compression layer 224x224分辨率 |
Compression layer only | 200M Image captioning |
| 2 | extend the resolution of pretrained vision encoder | vision encoder(SigLIP-SoViT-400m/14) | Another 200M image captioning | |
| 3 | further adapt to high resolution with adaptive strategy | compression layer + vision encoder | OCR + image captioning | |
| SFT | 1 | downstream tasks | vision encoder + compression layer + LLM | 只用Human label过和GPT-4生成的数据做训练 |
| DPO - RLAIF | 1 | reduce hallucination | 原文没写,但大部分的DPO主要训练的是LM和fusion模块 | 6k preference pairs |
这里唯一的问题就是DPO阶段训练的参数没写,不知道训练了什么。常见的是训练LLM和模态Fusion模块(Compression layer),但这个确实没写。如果有知道的麻烦留个言。
DPO RLAIF就用SFT之后的Base Model,在High temperature下生成10个回复,然后先用LLaMA 3给回复划分claims,再针对这些claims中的每一个用LLaVA-next Yi-34B给这些claims打分,从而获得有打分分数的回复。训练的时候,会针对这10个回复sample出来一些pair,用这些pair的相对分数来决定reject和accept的数据集。
Results
部分Benchmark上在8B的size上能够实现这个大小下SOTA的结果,对于有需要压缩图片占用tokens数量的应用有比较高的应用价值。
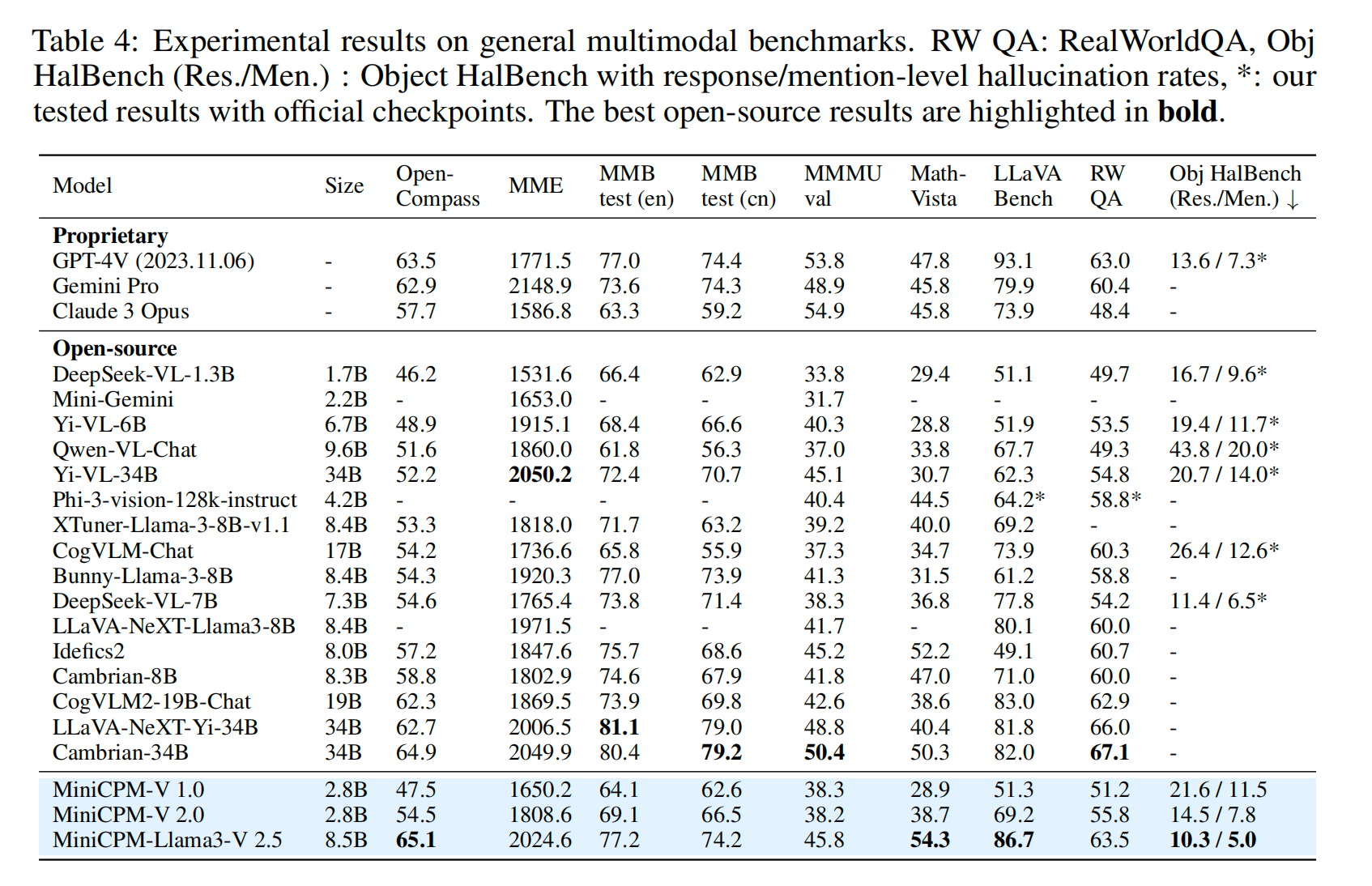
Conclusion
总结来看面壁智能的这个release还是非常有诚意的,SFT的代码比较完善,基本上改改数据就能在应用场景里直接用上;其次由于他有这个compression的模块,对于图片压缩能力还是提升比较明显的。有需要多帧输入的也完全可以直接用上。注意这个MiniCPM-V2.6的代码要直接在Huggingface上看,开源的代码库还没更新到这个模型的代码。