MMEvol: 构造牛逼的instruction数据集
- 标题:MMEVOL: EMPOWERING MULTIMODAL LARGE LANGUAGE MODELS WITH EVOL-INSTRUCT
- 时间:2024.09.10
- 作者团队:阿里巴巴
- 作者:Run Luo, Haonan Zhang, Longze Chen, Ting-En Lin, Xiong Liu, Yuchuan Wu, Min Yang, Minzheng Wang, Pengpeng Zeng, Lianli Gao, Heng Tao Shen, Yunshui Li, Xiaobo Xia, Fei Huang, Jingkuan Song, Yongbin Li
- 有用指数:⭐️⭐️⭐️⭐️
- 贡献程度:⭐️⭐️
- 简单评价:
- 优点:针对多模态场景下的数据构造的痛点(数据多样化较差,认知推理能力不够,数据中的图片描述可能存在幻觉)提出了4种数据构造方法,数据本身要开源(但是还没开源),虽然其本身是为了通用能力设计的,但可以把构造方法迁移到Inhouse场景下,构造专有领域数据。
Existing Gap
现有的多模态模型一般都会经历预训练和指令微调两个阶段,指令微调这个阶段对于模型能力的提升是比较关键的。目前的方法一般都是使用GPT-4V,GPT-4o这种在多模态领域做的比较好的模型进行数据构造,这种简单的模型蒸馏方法比较受制于原本模型的数据分布,多样性也会打折扣。所以这篇文章想解决如何在成本可控的情况下,尽可能构造多样且有推理过程的数据集。
Proposed method
总体思路,从一些seed数据出发,构造出进化版数据。
构造数据类别上作者分了四大类,
- 细粒度感知进化:要在构造过程中尽可能关注图片的非主体内容,构造时使用的prompt主要是让模型参考原来Q&A的形式,但是构造对图片中更加rare的物体的问答行为,比如下图,构造的问题是图中有多少个旗帜。而尽可能让图片描述详细的原因也和之前提到过的不同模态之间可能share了相似的特征有关。
- 感知推理能力进化:在构造过程中,把原本标注的结果用reasoning的方式得到,以得到提升模型推理能力的数据。
- 交互能力进化:目前的指令微调的数据集的指令都比较单一,使用某些固定的rephrase过的版本作为训练的指令,这就让微调过后的模型比较难适应到更多的场景里,作者提出了构造数据时,同时让指令变得更加复杂,这样就能拜托一些预定义的指令集:
- 低质量数据过滤:在构造过程中肯定存在其他模型虚构了一些数据或者有部分幻觉,所以作者提出了使用一种打分机制,把构造不合适的数据全部过滤掉:




实验结果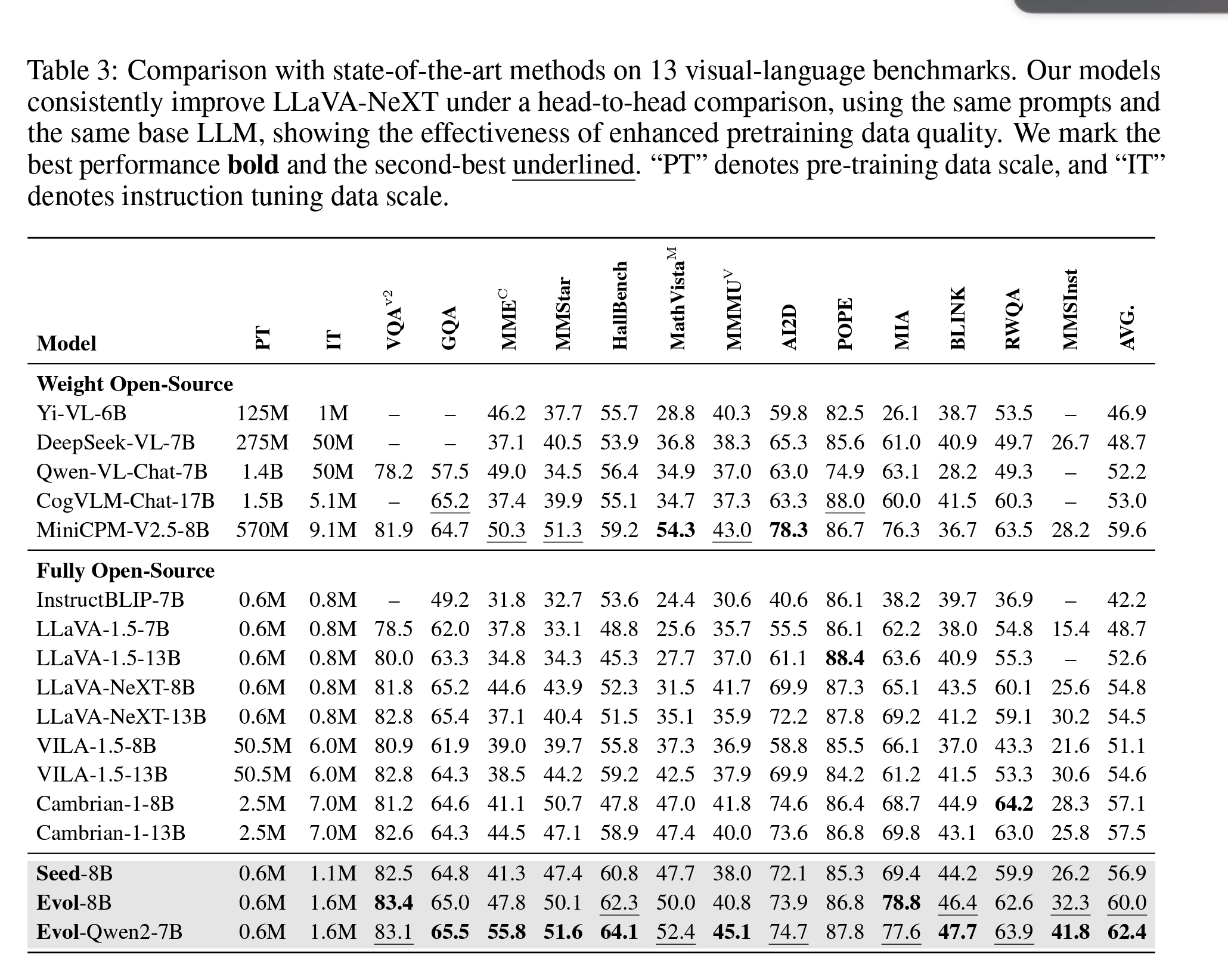
结论
作者通过对预选取的数据进行派生,并严格过滤了派生之后数据,在没有使用太多额外方法的情况下,就能在某些Benchmark上取得很好的结果,后续就等数据放出来再研究下了。
PREVIOUSAI算法