VLM Survey
总览
多模态大模型(Vision Large Models)主要是能感知多模态输入(目前主要是图片和视频)并产出语言输出(也有直接的多模态输出架构)。目前常见的VLM架构有两种,
- Type A: Visual Encoder -> Cross Modality Connector -> LLM
- Type B: VQ-VAE -> Transformer
第一种能够利用到单模态训练时候的语言能力,具有计算资源需求少,且能达到较好效果的程度;缺点是基本只能语言模态输出,无法输出多模态内容;第二种能够直接把图片模态和文本模态进行tokenization,在decode的过程中可以直接产出多模态输出,但是VQ-VAE的训练难度比较大,基本需要从头训练,成本较高,目前处于更前期的探索阶段。
主要难点
目前,Typa A的主要难点是
- 如何处理不同分辨率的图片;因为大部分采用了Vision Encoder架构的模型使用的Vision Encoder都是ViT,ViT能处理的分辨率是224x224。
- 如何在一次生成中引入更多的图片;因为该架构会使用ViT的最后一层作为feature,大小一般是576或者768。这个feature的长度会给后面LLM模块带来较大的压力。
- 如何对视频进行建模;视频同时有稠密帧数据和temporal feature,如何能达到平衡是一个难题。
常规解法
处理分辨率
现在的多模态模型的technical report都会花较长的篇幅介绍自己如何对图片进行操作,下面介绍几种典型操作。
- 对图片进行downsampling或者upsampling;
- scale then padding。
MiniCPM-V:根据ViT预训练时候的分辨率,选择一个最佳的比例给原图进行切片,把所有切片加上缩略图平铺输入到SigLip。如果是多图的话,每张图会分别形成一个list。实际训练的时候,每张图会用换行符隔开。Resampler的意思很直白,就是用cross attention模块,再对SigLip的特征进行压缩,提取出来压缩后的特征。
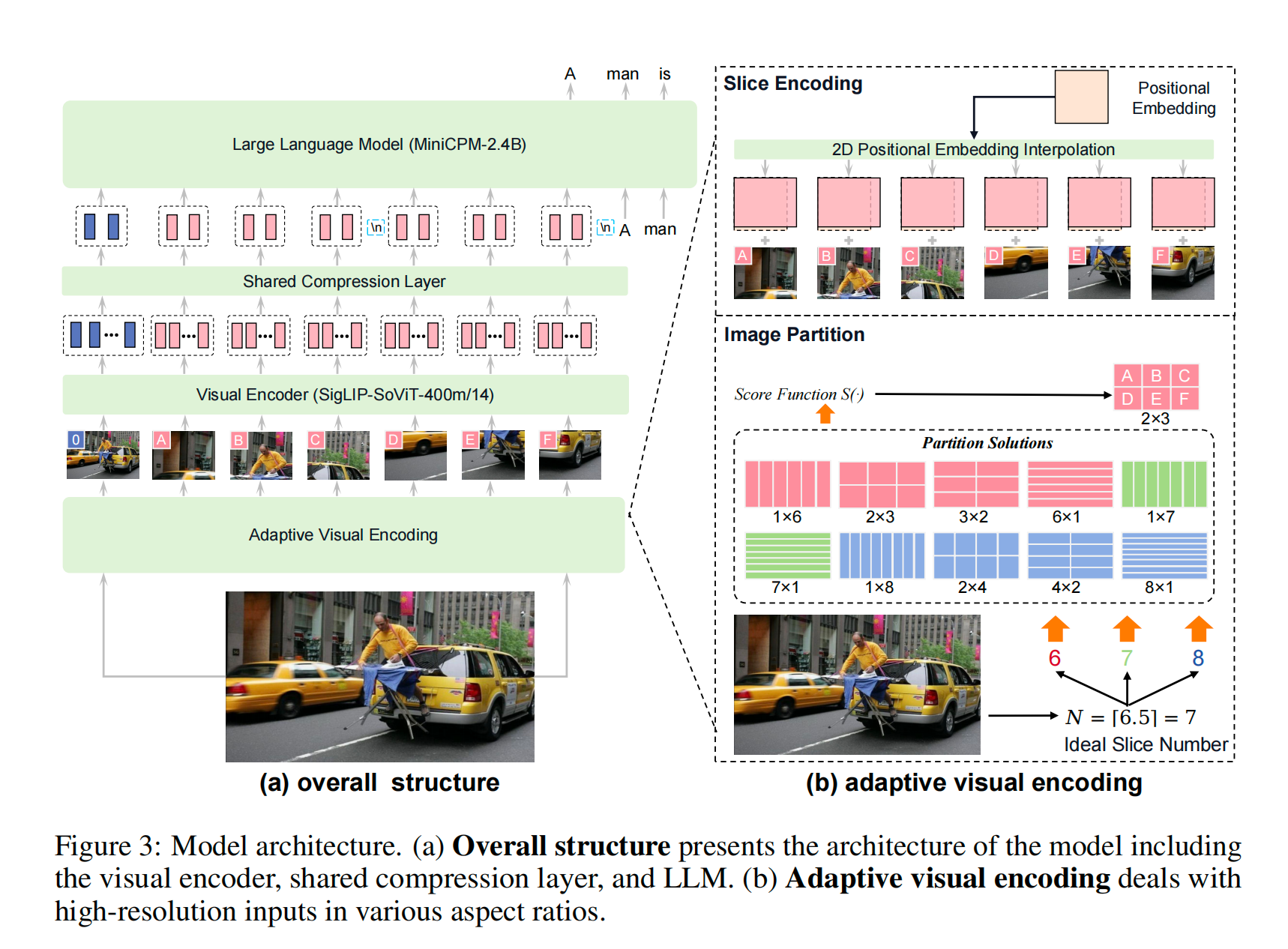
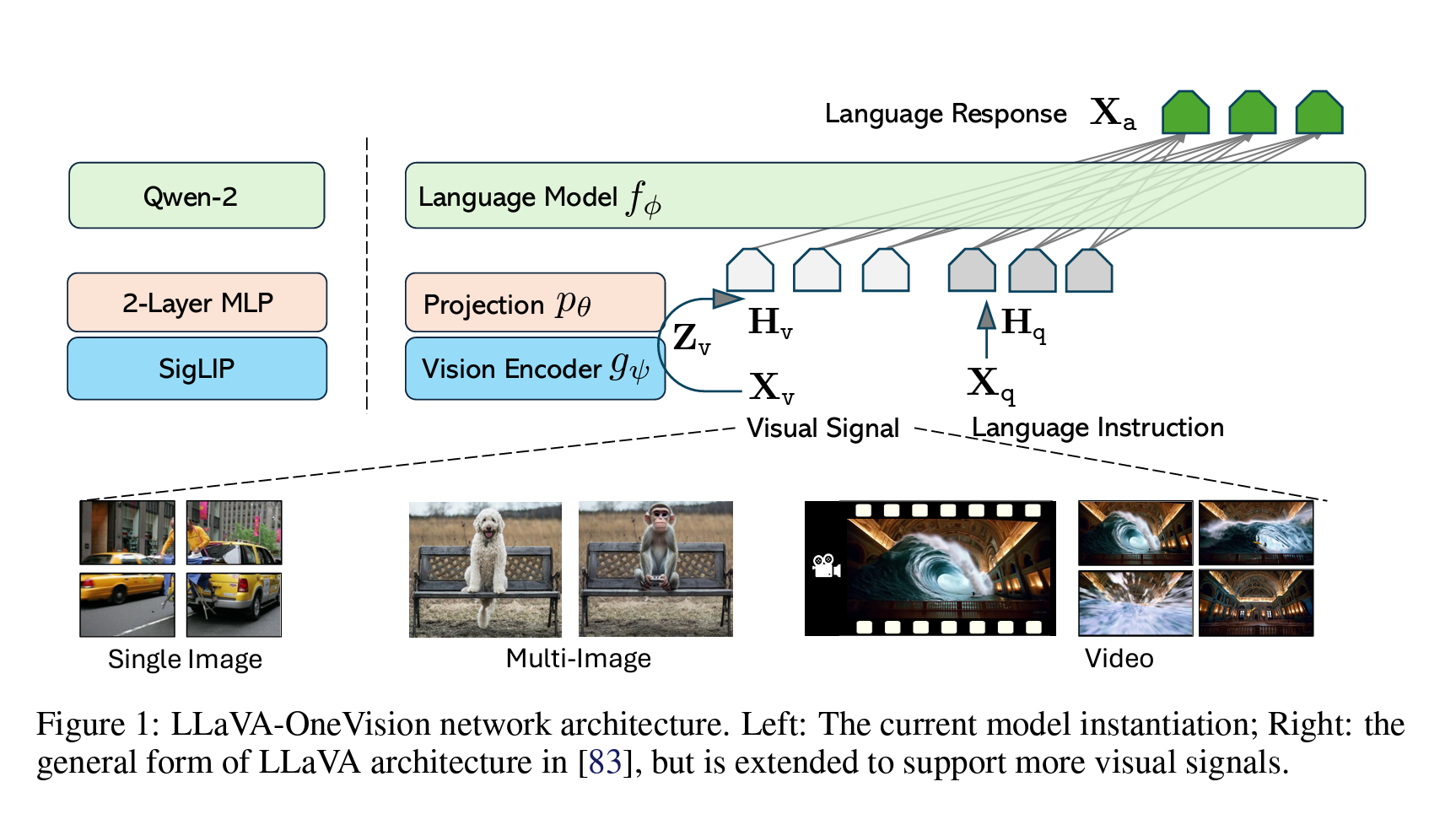
LLaVA onevision的图片处理策略:①单张图片,切分成$a\times b$大小的slices,每个slice都是SigLip能处理的大小,外加上一张resize后的整体的缩略图。②多张图片,每张图片直接按照SigLip的分辨率resize,然后把多图直接给SigLip处理。③视频,SigLip分辨率resize之后,再经过BiLinear Interpolation,得到更小长度的embedding,拼接后输入到LLM中。其实PiL库的resize function默认就是BiLinear Interpolation,作者就是直接resize了。
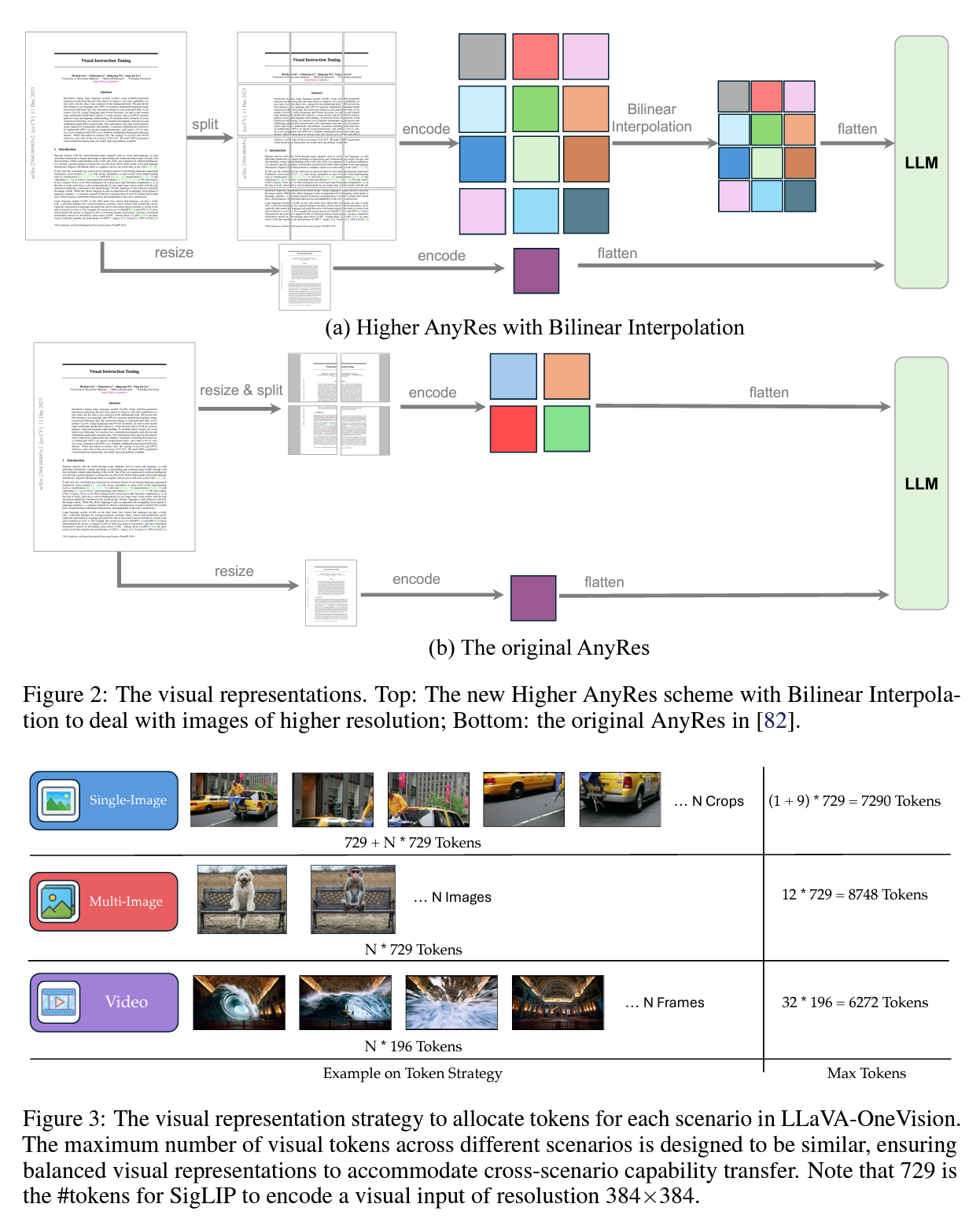
Qwen2-VL:认为上述两个方法都需要把图片分辨率适配到预训练的CLIP模型的分辨率,在高分辨率图片,尤其是OCR的场景表现较差,因此他们需要针对分辨率动态调整一张图片占用的tokens数量。所以他们对ViT的结构进行了魔改,把原来的ViT的positional embedding拿走换了个2D RoPE作为positional encoding的方法,同时加了一层MLP把$2\times 2$个映射成了1个token,已达到压缩图片的目的。这个做法看上去比较合理,但天下没有免费午餐,这样原来训练好ViT模型也丧失了一定的能力。后续训练也需要对原ViT模型有一定重新训练。但比较有意思的是,有其他文章1: Molmo & PixMo.验证了Qwen2-VL在所有学术Benchmark上表现比较好,但是在human eval的时候表现非常不一致。

2D RoPE的代码实现:
def forward(self, x, position_ids):
if "dynamic" in self.rope_type:
self._dynamic_frequency_update(position_ids, device=x.device)
# Core RoPE block. In contrast to other models, Qwen2_VL has different position ids for thw grids
# So we expand the inv_freq to shape (3, ...)
inv_freq_expanded = self.inv_freq[None, None, :, None].float().expand(3, position_ids.shape[1], -1, 1)
position_ids_expanded = position_ids[:, :, None, :].float() # shape (3, bs, 1, positions)
# Force float32 (see https://github.com/huggingface/transformers/pull/29285)
device_type = x.device.type
device_type = device_type if isinstance(device_type, str) and device_type != "mps" else "cpu"
with torch.autocast(device_type=device_type, enabled=False):
freqs = (inv_freq_expanded.float() @ position_ids_expanded.float()).transpose(2, 3)
emb = torch.cat((freqs, freqs), dim=-1)
cos = emb.cos()
sin = emb.sin()
# Advanced RoPE types (e.g. yarn) apply a post-processing scaling factor, equivalent to scaling attention
cos = cos * self.attention_scaling
sin = sin * self.attention_scaling
return cos.to(dtype=x.dtype), sin.to(dtype=x.dtype)
效果如何
先说结论,从使用角度来说,如果用来在自有任务上做SFT,
MiniCPM-V > LLaVA onevision > Qwen2 VL
这几个模型都是基于Qwen2的LM,所以这个结论比较起来也有一定说服力。但是,这个只是我们自己训练得到的结论,实际上会根据任务要求和数据类型的不同,结果会有区别。个人建议,如果需要早期确定一个模型是否在某个任务上能够取得还不错的效果,可以自己构建一个较小的,数据分布和预训练数据有一定交叉,且和自有任务有一定交叉的验证集(实在不行就试试模型的caption能力)。每个模型训练之前拿来跑下这个Benchmark,比直接相信技术报告里面的结果要好一些。
为什么需要处理分辨率
现在业界普遍相信,对于偏向OCR的任务,需要高分辨率的输入,而其他任务并不一定需要高分辨率图片。从模型整体效果来看,有一篇不错的文章可供参考。
在LLaVA-next的2024.6月的blog中,https://llava-vl.github.io/blog/2024-05-25-llava-next-ablations/,作者在projector这条技术路径上进行了探索,对于Type-A模型来说,影响模型能力的是什么,先说结论
- 提升LLM的能力比提升Image Encoder和提升分辨率都更有用;
- Vision Encoder的大小和分辨率提升都对结果有提升,但是提升分辨率对效果的提升更多;
- 训练时要引入一个训练阶段,这个阶段需要全参数训练+高质量数据。
其中结论2对分辨率的ablation表格:
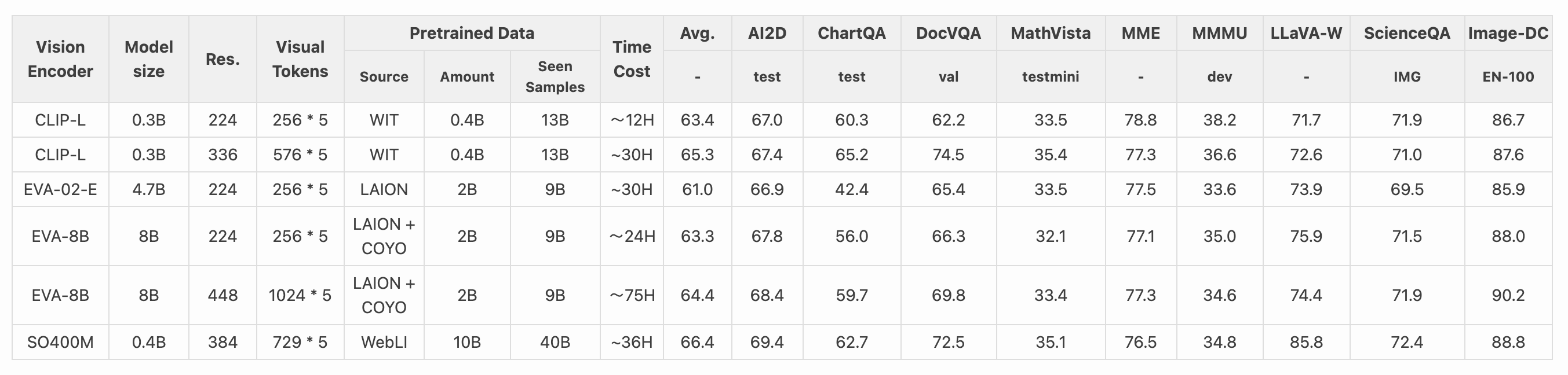
可以看到,在相同Vision Encoder下,分辨率的提升对效果都是有正向影响的。但细看这个表格,并非所有Benchmark都有提升,比如ChartQA和DocVQA的提升巨大,而MME,MMMU等甚至还有下降。前者任务类型更偏向OCR,而后者则是包含了推理和图像描述等任务的。所以callback一下开头说的,如果你的任务是OCR为主,那么先无脑提升分辨率再说;如果和OCR不相关,分辨率的影响可能不大。
视觉表征(Vision Representations)
不同分辨率的图片映射到分辨率就是Vision Encoder预训练的分辨率,Vision Encoder会把图片映射到到一个一维长度的Image representation。一般来说,大家会使用到Vision Transformers架构的模型的最后一层拿掉CLS token。ViT的架构可以参考我的另一篇笔记,简单recap一下,就是在下图的MLP Head之前的一层layer。
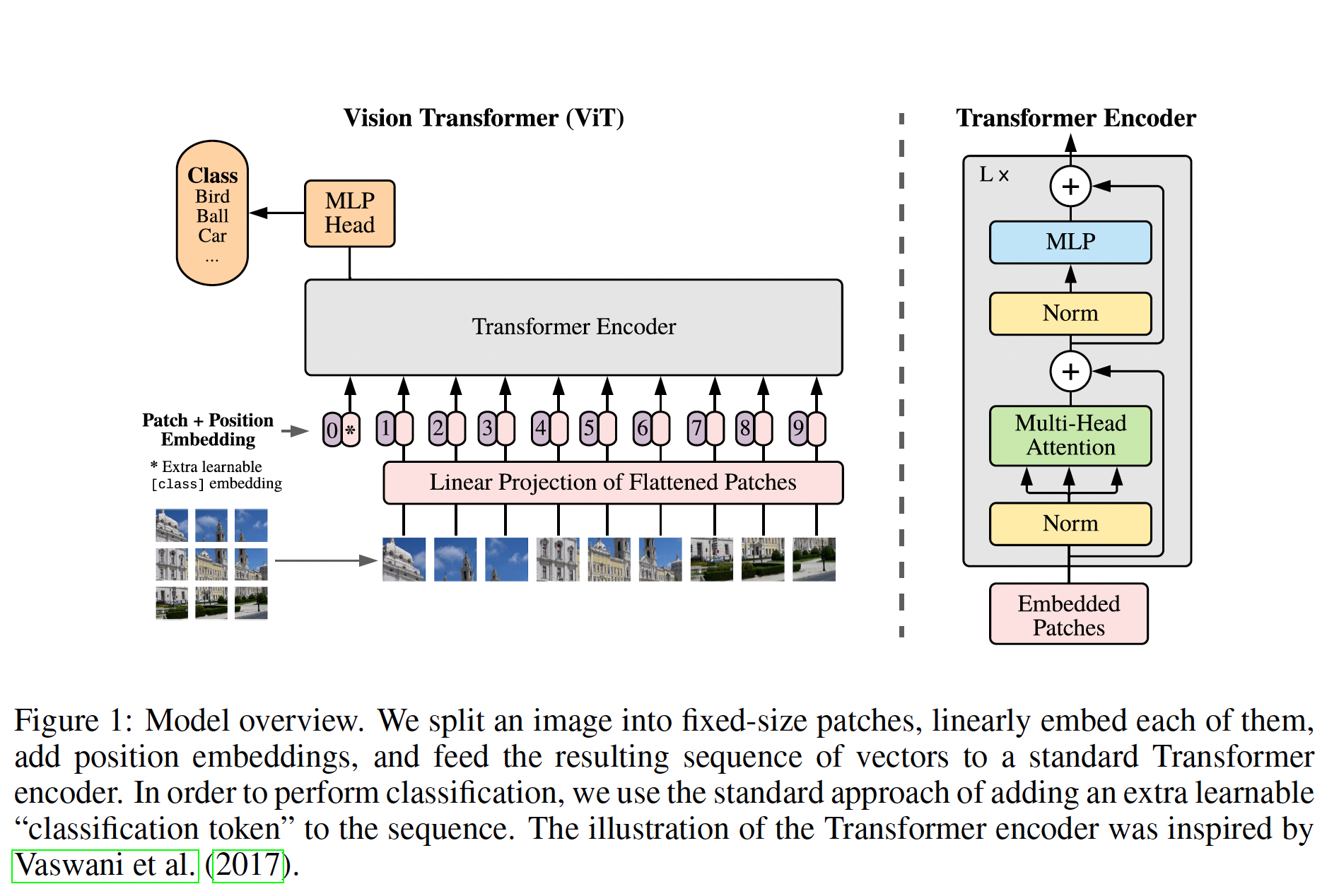
对于Type-A模型,MiniCPM和LLaVA使用的是 SigLIP SoViT-400m/14,Qwen2-VL使用的是DFN,这些模型都是基于CLIP的方法训练得到的ViT模型,只是训练的loss不同或者基于的初始数据集不同。这里需要重点关注,不同架构是将ViT的Output输出给LLM的。
- MiniCPM-V:基于Resampler的方法;
- LLaVA和Qwen2-VL:基于projector的方法;
Resampler:利用Cross attention模块对原representation进行resample,提取更短长度的特征,这种方法好处是resample后的特征长度比较好定制,可以用较少的token表征一个slice或者图片。一般来说,这个Resampler会把Query设置为可学习的参数,Key和value是经过ViT模型的原特征。
以MiniCPM-V的Resampler代码为例,看forward函数
class Resampler(nn.Module):
"""
A 2D perceiver-resampler network with one cross attention layers by
given learnable queries and 2d sincos pos_emb
Outputs:
A tensor with the shape of (batch_size, num_queries, embed_dim)
"""
...
def __init__(self,):
# 初始化为可训练参数
self.query = nn.Parameter(torch.zeros(self.num_queries, embed_dim))
def forward(self, x, tgt_sizes=None):
pos_embed = ...
x = self.kv_proj(x) # B * L * D
x = self.ln_kv(x).permute(1, 0, 2) # L * B * D
q = self.ln_q(self.query) # Q * D
out = self.attn(
self._repeat(q, bs), # Q * B * D query
x + pos_embed, # L * B * D + L * B * D key
x, value
key_padding_mask=key_padding_mask)[0]
# out: Q * B * D
x = out.permute(1, 0, 2) # B * Q * D
x = self.ln_post(x)
x = x @ self.proj
return x
基于projector的方法:以LLaVA为例,LLaVA用一个两层的MLP直接将representation投射成长度h的n维的embedding。然后直接和文本的input embedding拼接在一起后进行LM的后续Transformers block。
效果如何
先说结论,这个和任务强相关,如果对于每张图片的分辨率要求不高,但是对图片数量(多图推理任务)有要求的,那么Resampler模型效果好;否则效果差不多。LLaVA的projector方法胜在结构简单,训练方便。实际上LLaVA在提出这个架构的时候,就明确表达了自己想做Data-centric,用最快的方法验证构造的数据是否有效。但从可定制化角度,更复杂任务的角度看,一个简单的projector还是略显力不从心。
VQ-VAE
等深入研究后再完成该部分内容。
训练过程
先说结论:
- 实际下游任务微调中,数据量不多的情况下,SFT只训练LLM效果是最好的。其他微调方法效果都会更差。
- 适配下游应用时,大部分试图创新模型结构或训练方法来提升效果的努力都是徒劳的(搞大模型的人太多了,你能想到的方法早就被人试过无数遍了,这些方法之所以没出现在论文里,是因为这些方法没用),除非你训练数据非常多,且训练过程的把控很好。
- 模型效果提升没有Silver Bullet,全是搞数据和炼丹的苦工。
模态对齐简单而言就是让训练好的LLM能够认识Image features,并赋予该feature特定的含义。比较直白的想法是,既然ViT和LLM都是训练好的,那么他们的Output就本来具有特定的意义,因此,对齐的过程往往就是单独训练对齐模块,比如Resampler或者projector。
现在的多模态训练一般会分成几个阶段,第一阶段用来Warm-up视觉模块和文本模块的connector,对于MiniCPM就是Resampler,对于LLaVA来说就是connector,以MiniCPM的训练举例
- 预训练
- Connector Warm-up:不改变预训练的ViT的分辨率(默认224*224),选用Image caption数据库,仅训练connector,其他参数都冻结。各家可能会采用不同的策略,比如MiniCPM会使用Image caption和OCR两个数据训练,下面是一些训练的数据sample(from LAION-COCO)。这类数据的特点是caption较短,分辨率较低,数据量非常大。
| URLstringlengths22961100% | TEXTstringlengths17.01k100% | top_captionstringlengths6154100% |
|---|---|---|
 https://i.pinimg.com/736…-street-view.jpg https://i.pinimg.com/736…-street-view.jpg |
Hello again ! Today is Wednesday, January 13, 2016, and we have nothing to hide, thanks to Google Street View. Google has updated the streetview of West Java, and here are some higlights related to destinations that we have mentioned in our previous post, Indonesia Travel Plan, Free & Easy 2016 . Ujung Kulon National Park The last … | The view from a google street shows several different locations. |
-
分辨率提升:第二阶段会把训练图片的分辨率提升到448*448,并只训练Vision Encoder,其他所有模块冻结。用到的数据和第一阶段相同。
-
encoding策略训练:MiniCPM使用了一些特殊方法来处理高分辨率图片(LLaVA和其他模型也是类似的),比如pooling或者adaptive Slicing+pooling等,这些高分辨率图片处理方法会改变ViT预训练模型感知图片的特征,因此这里需要针对该方法对Vision Encoder+Connector进行训练,并冻结LLM的参数。
- SFT
- 基本上就是传统的SFT阶段,会使用QA或者具体的下游数据对模型进行指令微调,MiniCPM这里在训练的时候把所有参数都打开进行微调了。如果我们看LLaVA,他们用的策略也是类似的,都是打开全参微调。但我在实际训练过程中,全参微调的效果不如只训练LLM,应该主要是数据量和数据分布的原因,分布和原数据有差别的话,效果可能不如只训练LLM。
- RLHF
- 几乎所有开源的多模态模型都在Alignment tuning这一步取得了效果,并且会在减少幻觉这个Benchmark上大书特书。目前正在计划做这一步的训练,会在有结果的时候分享出来。
总结下,
- 现在ViT+LLM的训练过程普遍包含Image caption的预训练,分辨率提升训练,高分图片或多图encoding方法的训练,SFT和DPO几个流程。
- 实际做SFT的话,数据量小只训练LLM就行了。
下面提出几个问题,大家可以关注我看后续问题的结果(我也在学习)
- 每个阶段的衡量标准是什么?如果全都训练完看端到端的效果,流程是否太长了?
- 每个阶段训练完的消融实验有没有?为什么训练过程要这么设计?哪些手法是特别有效果,哪些手法的增量微乎其微?
- 训练数据都是百K,M的量级起跳,训练的时候有哪些数据处理的细节?有没有科学手段衡量自己的应用数据集应该如何构建和清洗?
每个阶段的衡量标准
这里至少有两个问题
- 该训练阶段目标达成如何?
- 该阶段训练目标如何和下游任务的目标对齐?
比如,第一阶段是训练projector,使用Image caption数据,那么projector对齐的越好,对Benchmark的提升就越大?projector对齐到什么程度,对下游任务的影响就比较小了?
关于VLM SFT训练后的一些实验和思考
SFT本身并不算有技术难度,可以简单到两个流程,① 组织好任务需要的数据,② 开几个实验进行超参的探索。实际上第二步甚至也可以不做,SFT的脚本里已经预设了一些超参,直接跑下训练就可以了。那么问题来了,一次训练完了,有一个初始效果了,后续如何继续优化?
还是要从业务角度出发,发现存在的问题。先说我们任务对于VLM的要求是,
- 回复有一定多样性,业务需要一次生成很多候选集,即一次生成结果中需要存在多样性;并且在Input相同的情况下,需要给出多样性更高的回复,即多次生成需要存在多样性。
- 回复的质量要够高,需要在离线和人工评估的Benchmark上有持续的涨点。
这里说一个暴论:如果我们的任务是服务于应用,不要轻易改模型结构,如果是分类问题,可以尝试改下最后一层或者加一层,可能效果还不错。原因也很简单,做一个好的基础大模型是一门系统工程,需要标注资源,数据资源,训练资源和人力资源的投入,除非能论证价值并调动很大团队做,否则大概率是无用功。模型结构的改动必然会导致LLM已经Align过的部分改变,效果大概率是下降的。
所以这里初始也是最有效的方法就是想办法构造更多更高质量训练数据。
回到VLM的要求,针对相同Input也要求回复多样性的场景,有几种方法。
- 纯inference方法:
- RAG:做一个带Recall的系统,一次生成的每个给不同的prompt,回复自带多样性,但要模型有较强的in-context learning的能力;而且RAG的内容会潜在影响模型训练好的回复质量。
- High temperature:用的多了会发现这个最大的问题就是回复和我们想象的多样性差别较大,整体来说还在一个框架内进行回复。
- Dynamic temperature:算是一个折中的方案,增加前几个token的temperature,后面token的temperature是不固定的。
- 训练的方法
-
我们的思考非常直白,就是增加相同Input下面生成tokens的多样性,Next token prediction的公式是:$p(x_{t+1} x_{1,2,…,t})=f(x_{1,2,…,t})$,如果我们能让模型在相同Input下看到不同的token,是否就天然让生成带有多样性?
-
这里我们利用了闭源的VLM对相同Input构造了n条完全不同的回复,并保证这n条回复的每条的质量都是达标,甚至更高的。并用这些数据对模型进行了训练。但不知为何,模型突然开始拒绝回复!

经过思考,我们初步确定了两个假设
- 构造数据的Input数据是来线上的真实分布,所以图片的分辨率的多样性非常高,考虑到VLM预训练时的分辨率都是相对一致且逐步提升,直接动态分辨率训练可能引起问题;
- 给相同Input的不同回复的数据导致模型参数corrupt,干脆不知道怎么回答了。
所以我们设计了一个实验,
实验1:把相同Input的5条回复缩小到1条,如果还是回复有问题,就确定至少和多个回复无关;
结果我们发现模型还是存在拒绝回复的情况,那么可以确认问题至少不是假设2引起的。
为了验证假设1,我们可以设计另两个实验
实验2:把所有输入图片的分辨率都统一;
实验3:给不同分辨率的图片进行归并,进行分阶段训练,例如限定224$\times$224,336$\times$336,448$\times$448,这几个区间,把一个sample中的多图找中位数进行分辨率统一,先训练低分辨率组,再训练高分辨率组。
我在做这两个实验之前,顺手起了另一个任务,用相同数据换了个backbone,从MiniCPM-v换成了LLaVA-onevision,然后效果突然就变好了。不仅没有拒绝回答的情况,而且按照预想的结果,给出了多样性非常高的回复。
这让我们陷入了思考,为什么backbone对模型的影响这么大,到底哪里对我们之前的认知产生了冲击,产生了这样的结果。
多模态大模型里,奥卡姆剃刀原则和贝叶斯定理还在发光!
我们首先进行了实验2,统一所有输入的分辨率,随后同时训练了LlaVA onevision和MiniCPM-v 2.6. 这两个模型都基于Qwen2-instruct,所以理论上两者回复的差距应该都是由他们预训练的数据和Vision与LLM的连接方式带来的。
实验2的结论是,两个模型都能正常说话,回复质量差距并不大,对图片中的内容都可以理解,对于in-distribution的instruction都能回复地还不错。但是!注意这里但是!一旦你改动Input的prompt,让这个prompt的格式和训练格式略有不同,那么MiniCPM的回复质量会急剧下降,主要表现是回复的逻辑性变差,并且会重复某些句子。
是否过拟合?
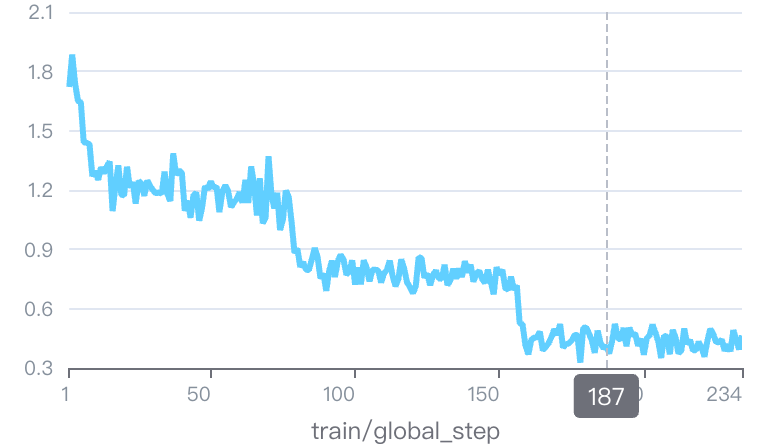
我的第一个猜测是MiniCPM可能在这些训练数据上出现了过拟合,所以我先check了一下他们各自的loss曲线,结果如下
| LLaVA Onevision | MiniCPM-v |
|---|---|
 |
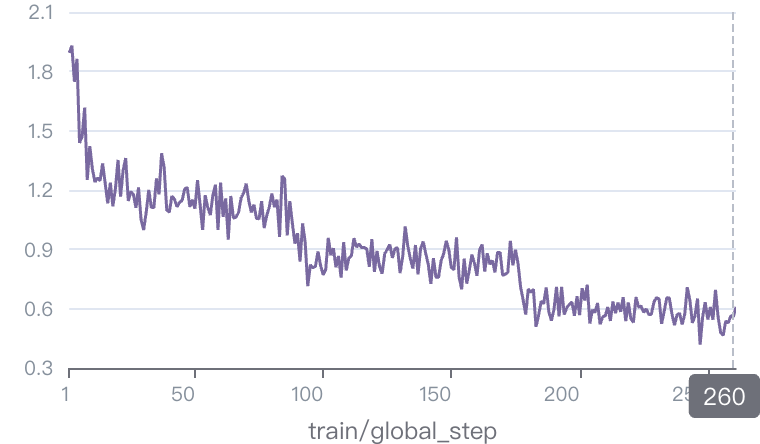 |
可以看到,这两个训练结果的loss曲线是相当接近的,甚至MiniCPM最后的loss是0.5左右,而LLaVA Onevision是0.4左右,说过拟合可能LLaVA的问题还更严重一些。
从实际业务的角度出发,无论这个模型承载的应用是哪种类型的,比如说Chatbot,用户随意输入,或者服务于某个业务,该模型是业务的一环,我们都不可能接受一个泛化能力较差的大模型,否则就失去了做大模型的意义。结合我这几天看的关于贝叶斯定理的书,我的思考如下。
先说结论:
如果两个不同结构的模型能完成同一件事,我们应该选择结构更简单的那个。
简单来说,
从贝叶斯定理的角度出发,从结果推断原因,我么可以得到下面的公式:
| P(原因i | 事情发生) =P(原因i) x P(在该原因下事情发生) |
在多模态模型场景下,假设你用了非常复杂的方法对模态连接进行了处理,而一个简单许多的模块能达到相似的效果,那么真实情况更可能是什么呢?更可能是简单的方法,因为这个简单方法的先验概率更高。即,P(原因i) = P(手法1) x P(手法2) x P(手法3)的概率要小于P(原因i)=P(手法4)。很有可能为了解决一些corner case过拟合了Benchmark,导致看似一个模型的Benchmark很高,但在实际应用的过程中结果差强人意。
但这并非说所有添加的手法都无用,对于一些显而易见的问题,解决了就是会效果变好。例如部分CLIP模型都是在224x224的分辨率上训练的,在这里添加一些处理方法能够适配到高分辨率就是一定要做的,但是可以选择一个相对简单的方法,这个方法可能就是一切结果的答案。
我后面准备验证自己的这个想法,继续简化LLaVA的分辨率处理模块,看是否能让结果变得的更好。关注我看后续结论。
重复说话问题
大模型训练能解决大部分问题,但把模型上到业务上,你会发现自己开始不断和corner case作斗争。短期内可以想一些后处理的方法,通过增加First token latency的形式在中间添加一些处理模块,防止产出离谱结果。但是显然,通过规则或者多步生成规避问题是短期方案,长期来看还是要从模型侧解决问题。
在我们的场景中,我们发现了训练后的模型存在重复说话的问题,简单来说,就是模型在重复同一句话,例如You are so good. You are so good. 有时候可以自动结束重复继续说别的,有时候无法结束重复的话直到达到context length。
Image token到底被理解成了什么?
既然现在多模态大模型都是在蹭LLM的说话能力,那这里肯定有个问题就是,图片的token在LLM侧到底被理解成了什么,导致LLM可以“认识”这些tokens,并能对这些tokens进行文本描述。如果我们能看到这些Visual tokens被映射成了什么内容,那么是否就很容易判断一个多模态模型是否在经过了微调以后产生了能力的变化?
Visual tokens是如何被映射的?
Resampler就可以理解为字面意义的把Vision Transformers的特征resample成LLM能理解的内容。具体做法就是用一个Cross attention模块,把Query设置成可学习参数,key和value都是ViT的输出特征。好处是Query的dimension大小可以定制化,所以想把这个特征压缩成多大的token数量都是可以的。如果做视频的内容理解,Resampler可以极限压缩图片的token数量。
projector类的就是单层MLP,其实并非Visual tokens,而是直接给出embedding,然后和已经从tokens转成embeddings的文本拼在一起组成embeddings传入LLM。
- 从问题出发,当前的结果到底还存在什么问题,是否有继续提升的必要?
- 如果有继续提升的必要,应该从哪些角度继续思考?
-
Molmo & PixMo.https://arxiv.org/pdf/2409.17146 ↩