Vision Encoder in VLM Survey
TLDR
- 目标:本文主要关注VLM中Encoder的发展和最新进展,主要围绕Vision Transformer这个架构介绍;
- 主要脉路
- CNN和ViT的基础架构
- CLIP和SigLip两种让ViT架构实现zero-shot inference的训练思路
- NaViT和其他扩展ViT支持动态分辨率或者节约训练成本的训练方法
- ViT和VLM的结合(未完待续)
核心目标
本文主要关注VLM中的Vision Encoder,其核心目标是如何学习到图片的语义表征,并能低成本和Transformers基座的LLM连接在一起。
分类
压缩视觉表征(embedding)的传统做法:
Architectures
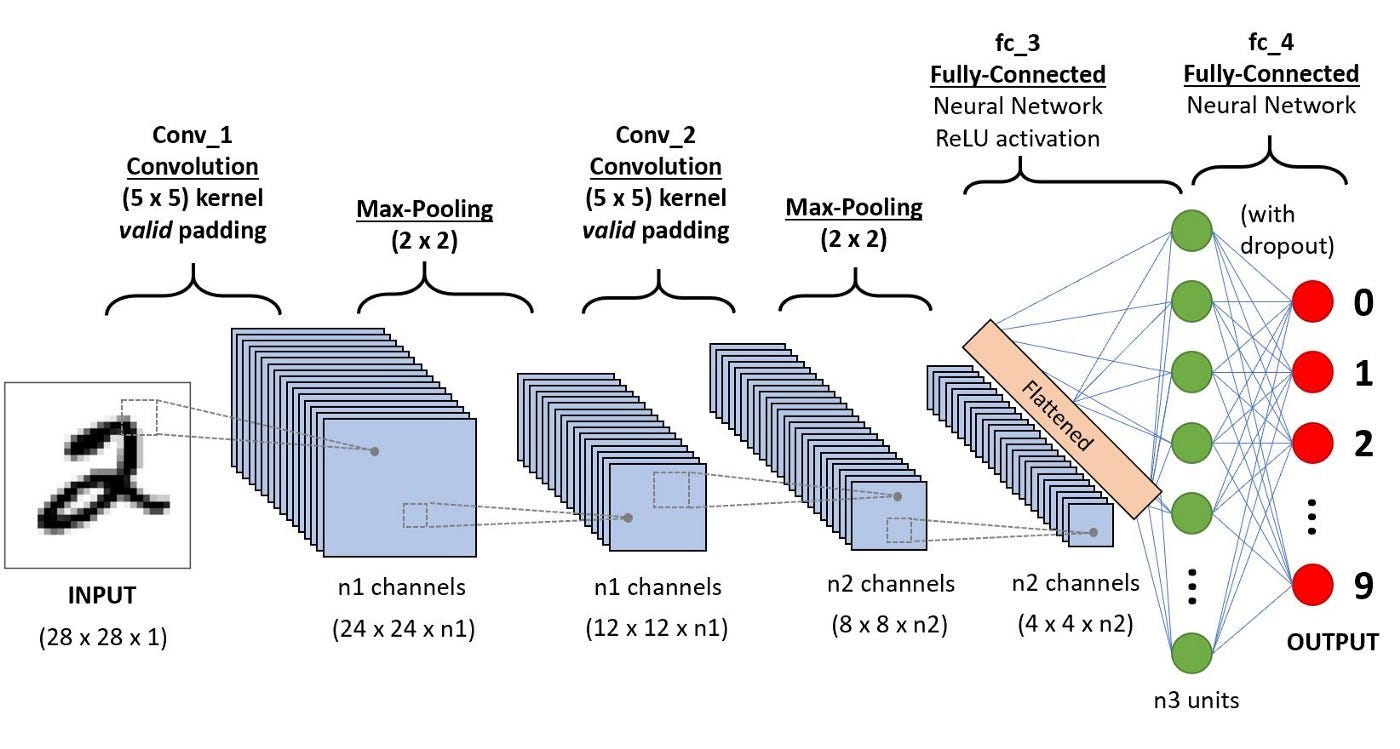
CNN
Reference:https://medium.com/@draj0718/convolutional-neural-networks-cnn-architectures-explained-716fb197b243
核心思路,通过kernal+pooling的方法对图片压缩,可以有多层Conv和pooling,最后把2D的feature flatten成一个1D,经过FC layer,最后可用不同的激活函数解决不同的问题。
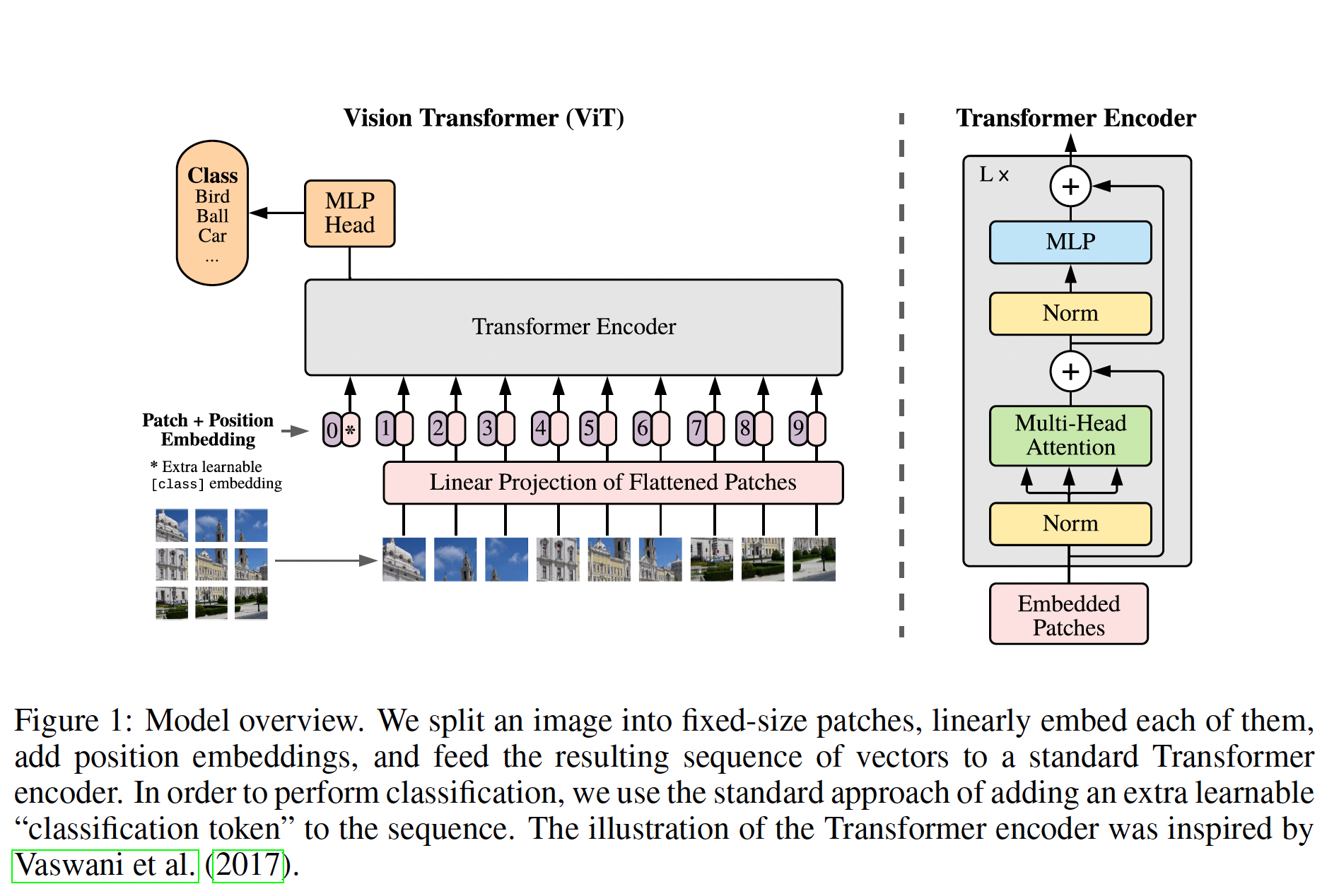
Vision Transformer
把image patches直接通过CNN映射成Linear embeddings或者通过$P\times P\times C$大小的patches映射成$P\times \text{n_emb}$大小的输入,再经过1D的positional embeddings进入Transformers架构。和image patches一起输入的还有一个MLP的head,是一个可学习的embeddings,最后这个MLP head的输出embedding会经过激活函数完成不同下游任务。
Zero-shot shot inference Training
CLIP
上述架构还是没办法做zero-shot的分类,分类标签必须提前定义好,无法把图片和任意的自然语言进行分类。而如何在上面架构开发,把image caption等用n-gram的方法变成一个个n-gram,再形成n-gram分类器,这种方法显然效率太低,而且由于分类可能过于多,导致训练结果不理想。
所以OpenAI提出了用Text Encoder把训练数据构造成image caption pair,分别经过Text和image Encoder,在一个batch里面计算contrastive loss。contrastive loss的精髓就是最大化对角线的相似度,最小化非对角线相似度,由于这个计算复杂度非常低,所以能够支持海量数据的训练,大大提高训练速度。这也是contrastive loss最大的贡献之一。
| Training | inference |
|---|---|
 |
 |
SigLip
从CLIP的训练方式看出来,它最大的问题就是对batch_size的要求比较高,一般来说需要32k的batch_size进行训练。所以SigLip提出了一个Sigmoid loss。简单来说,解决这个问题的思路就是divide and conquer,先想办法①把一个batch_size里面的loss能拆成可加和的方式,再②通过分别计算与合并完成loss计算。
\[\frac{1}{|\mathcal{B}|} \sum_{i=1}^{|\mathcal{B}|} \sum_{j=1}^{|\mathcal{B}|} \log \underbrace{\frac{1}{1 + e^{z_{ij}(-t \mathbf{x}_i \cdot \mathbf{y}_j + b)}}}_{\mathcal{L}_{ij}}\]上面非常直白,就是把原先一个batch里面的多分类问题(cross entropy loss)转化成了二分类,这个图文对是否match来计算loss。做yes/no的分类问题就不依赖batchsize的大小了。但这样会导致,正样本非常稀疏,负样本非常多,造成一开始的训练bias非常大。所以作者通过加bias的方式平衡这个loss,让训练变stable。
loss则可以通过在大Global batchsize中拆分小的batch,把每个小的batch计算好的loss进行汇总想加,以实现之前CLIP的训练效果。
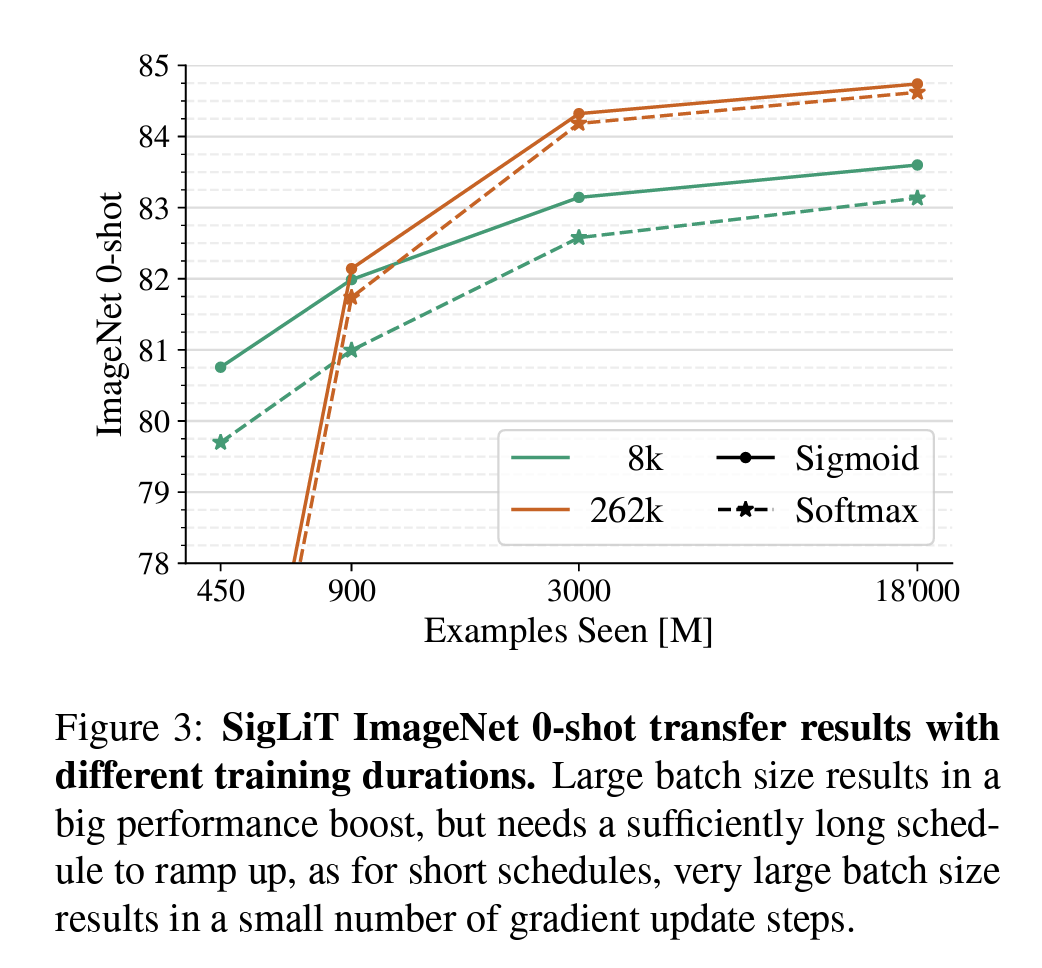
从结果上来看,这两个loss在batch大小相差很大的情况下取得了接近的效果,所以这个方案非常有竞争力。
ViT Extension
NaViT
CLIP和SigLip都是为了ViT模型能够支持zero-shot的图片文本分类而做的努力。CLIP和SigLip训练出来的ViT模型可直接用于VLM的Vision Encoder。但是并不涉及到ViT本身的改变,ViT本身还是只能处理224x224分辨率的Transformer架构。并且之前ViT的架构不能处理多图输入。
所以NaViT在这里面的思考就是
- 能不能像LLM的Transformer一样,把n多张图放到一起给到Transformers做训练呢?这样就能保证类似于LLM的Pretrain阶段一样训练模型。
所以他们提出的NaViT方法如下,
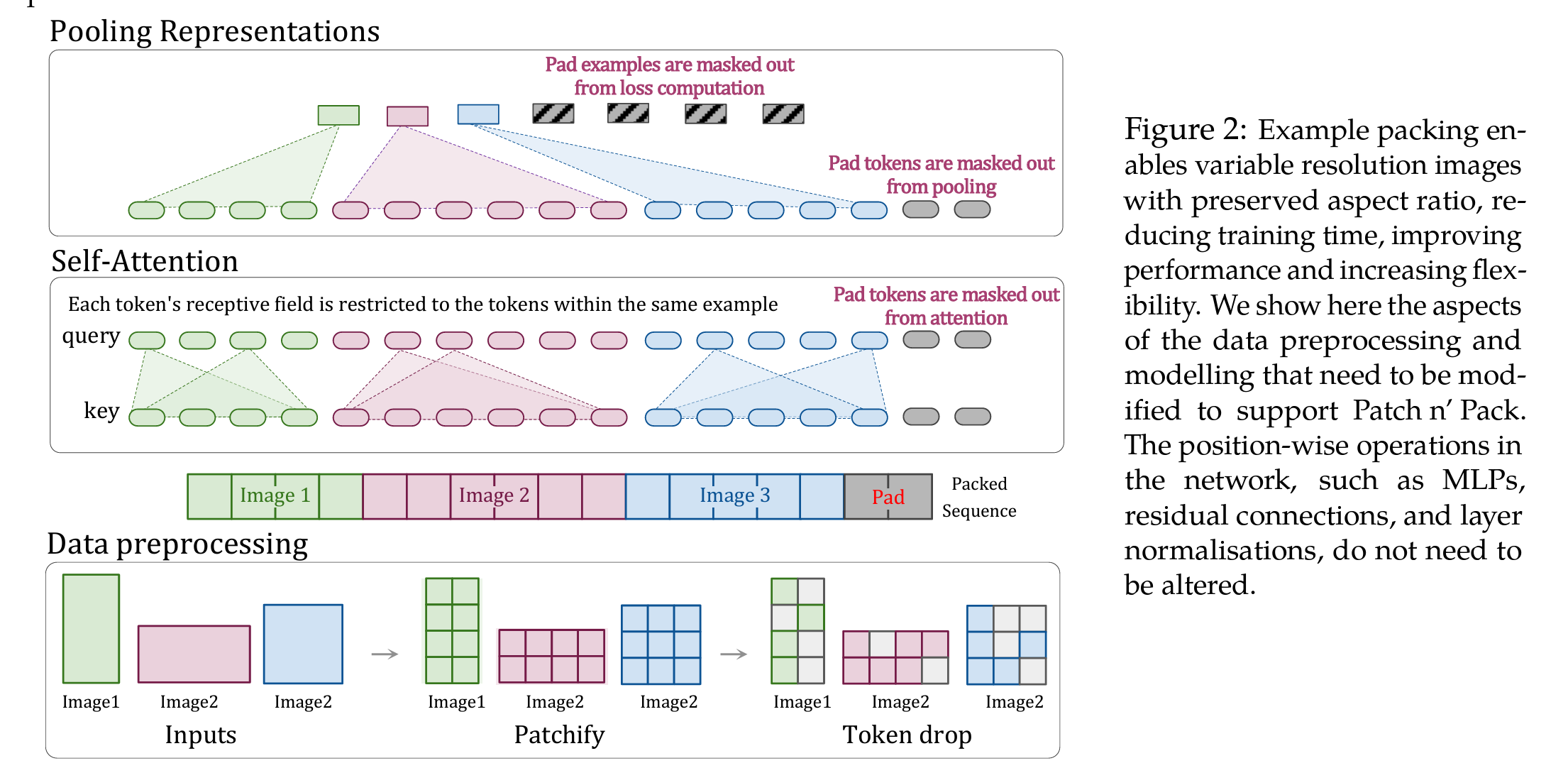
- image token pooling:对输入的tokens做pooling,使其成为一维的序列;
- masked attention:qk只attend本身的,并且对pad tokens做mask(和LLM的思路是一致的)这里一定要保证每个图只对自己做self attention。
- token dropping:在训练时候随机丢掉输入image的部分tokens,提升训练速度(后文讲了对效果的影响几乎可以忽略,但是能把训练时间缩短到原来的1/4)