字节DAPO解决了很多我对R1的困惑
困惑来自哪里
- 在最开始,我比较质疑deepseek的tech report上Response length的test-time scaling曲线,我认为仅在Format reward和acc reward的作用下,很难学习到这样的曲线,除非数据就是这样组织的(base Model能力足够强),训练只是从数据中学习到了这样的pattern而已;
- 但紧接着第二个问题,假设训练数据中就存在这样的pattern,则RL算法就无关轻重,只要是有效的RL算法,能学习到训练数据的pattern即可;重要的还是组织reasoning的数据;
- 但GRPO是一个能学到这种pattern的算法吗?
- 首先考虑reward function,Format和acc reward都非常稀疏,而GRPO又是通过sample-level的reward计算到per-token level的advantage function,从而计算gradients;而Format和acc的rewards分布应该是非常不均匀的,这几乎一定会导致GRPO的训练不稳定;
- 其次,我们假设一开始Format和Acc都比较低,一开始会大部分都是0,如果训练过程中可以学习到Format和Acc,那后续两者会持续提升,但由于这两者设计的较为简单,假设可以学到这种pattern,那学习应该也是非常容易饱和的,后期可能loss完全为0,参考DPO的训练就能知道;
- GRPO在R1的扮演的角色是什么?
- 我们都知道在原始的tech report里面,R1训练的第四阶段使用了Deepseek-v3中使用到的reward Model,那么在这个阶段的训练到底是GRPO训练还是传统的PPO-clip或者PPO-KL其实也没写,即使都用了,那么两者谁能带来最终的效果也没有提到。
综上所述,我当时的结论是,R1-zero的训练数据肯定是精心组织且叠加上了训练时候的一些策略(例如鼓励长回复),才能呈现出tech report上的结果。而字节Seed的这篇DAPO恰好解决了我的上述几点疑问。
实际上训练存在的问题是什么,分别怎么解
文中提到,至少存在Entropy Collapse,Reward noise和训练不稳定三个问题。
Entropy Collapse
可以理解为sample的回复长得都差不多,基本上后续的训练已经无法再发挥作用,模型更新幅度很小(浅蓝色的线);
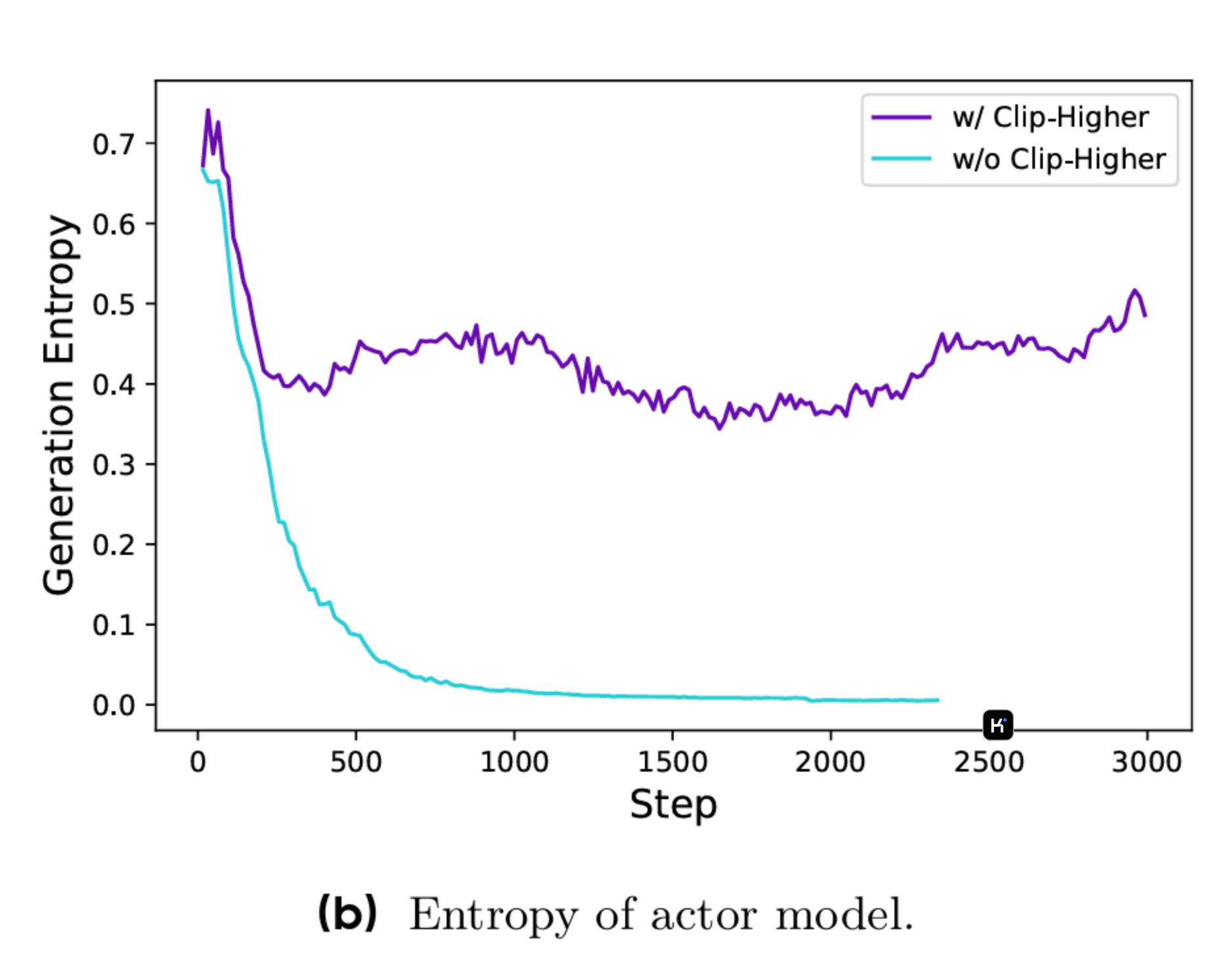
解法:
提出High Clip ratio,可以理解为让模型单步可更新的Gradient变大,允许模型探索原来更不可能的token。PPO有两个版本,使用KL Divergence或者CLIP-ratio(也即Trust Region方法)。前者作者认为不太合理,主要原因是前者强限制了两个概率分布之间的距离,但Reasoning的分布本身和预训练的分布差异可能很大,用KL限制可能导致模型永远无法学到差别更大的分布,所以使用了Trust Region + High Clip Ratio的方法。
Reward Noice
Format Reward和Acc Reward学习到后期会有很多Reward Value都正确,所以Acc可能永远是1,这种情况就导致Advantage Function永远在做Zero update。Reward noise会造成后续更新缓慢。所以作者进行了一些改动,简单来说就是不断进行sample,并且过滤prompts,直到一个batch中只保留非0和1的Reward Value。
-20250324153833917.(null))
训练不稳定
所谓稳定就是能够看到test-time scaling的曲线,但是原始GRPO训练的一个核心问题是,没有显式鼓励回复长度!这就导致除非训练数据中有类似的pattern,或者base-model能通过reflection得到更好的结果,否则回复长度不太可能增加。
解法:
使用token-level policy Gradient loss,简单来说,之前仅在sample维度进行gradient update,实际上是把长回复和短回复都赋予了相同权重,那么对于长回复中可能存在的高质量reasoning pattern,其中的每个token能够对实际loss的contribution较少。并且,特别长的回复存在低质量的情况。所以,存在问题和高质量的长回复,都应该在训练时给予更高权重的考虑。所以作者提出了在一组Sample的Group中,应该按照token的来平均loss而不是一个Sample,核心的区别在于
$ \frac{1}{\sum_{i = 1}^{G} \vert o_{i} \vert} \sum_{i = 1}^{G} \sum_{t = 1}^{r} \vert o_{i} \vert $ v.s. $ \frac{1}{G} \sum_{i = 1}^{G} \frac{1}{\vert O_{i} \vert} \sum_{t = 1}^{r} \vert o_{i} \vert $
另一个问题是对于过长的回复如何处理的问题,有几种解法,第一,直接过滤掉过长的Sample;第二,给过长的Sample增加一定惩罚。
最终作者采用了软长度惩罚策略,即规定一个区间,在区间内越长惩罚越多,区间外则直接设置Reward=-1进行惩罚。
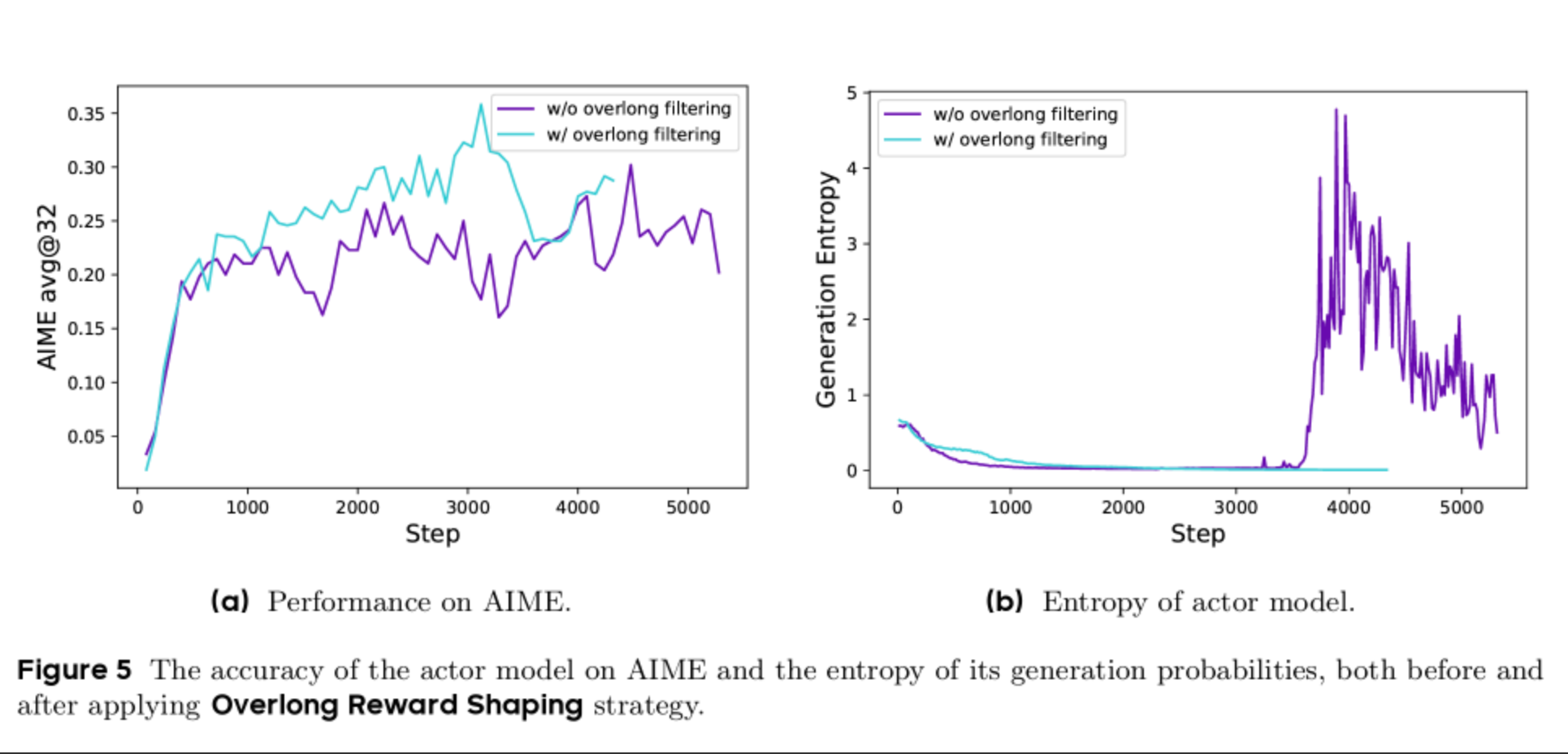
总结
Seed这篇文章提供了一些训练策略,不排除这些策略仅在Qwen32B的模型上训练结论才成立的可能性,但整体来说,对于一个基座能力不如Deepseek-V3的小模型,提供了一个可参考的思路集合。同时也不排除R1-Zero的RL训练并没有说出完整的训练细节,这篇文章进行了一定的补充。