OmniAlign - 模型自己调,数据我给你
TLDR
- 标题:OmniAlign-V: Towards Enhanced Alignment of MLLMs with Human Preference
- 时间:2025.02.06
- 作者团队:上海AI Lab
- 有用指数:⭐️⭐️⭐️⭐️⭐️
- 简单评价:
- 优点:开源界的老实人,搞了SFT和RL的数据,还放出来一个Human Alignment的Benchmark,数据和模型都开源给你,剩下的自己训练去吧。
Existing Gap
- 现在的Benchmark,都是在基础能力上测试,但是在人类对齐上(广义的instruction following)上面,还不够优秀;
- 但是LLM的instruction following挺好的,为什么MLLM就不行了呢?作者传达出一个insights就是MLLM进行的SFT数据对真实人类对话场景做的太差了,导致SFT过后的MLLM中的LLM能力下降严重;但是如果你加上LLM的数据混合训练,MLLM的Benchmark又会下降严重。
- Human Alignment能力下降证明:
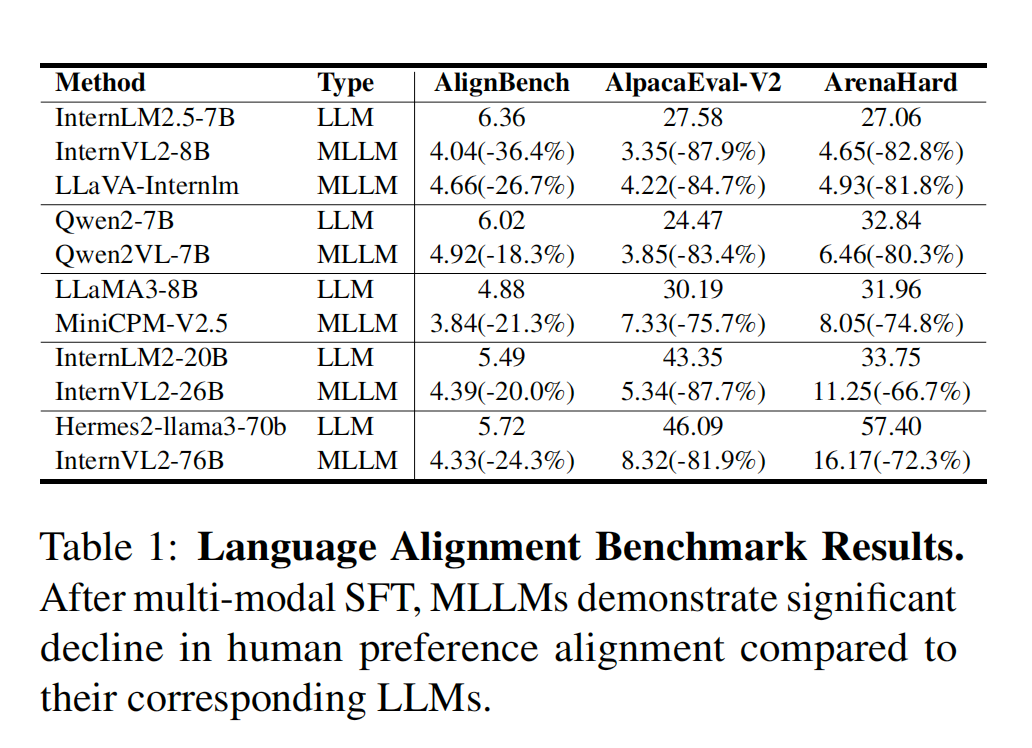
- 混合LLM数据MLLM能力不升反降:
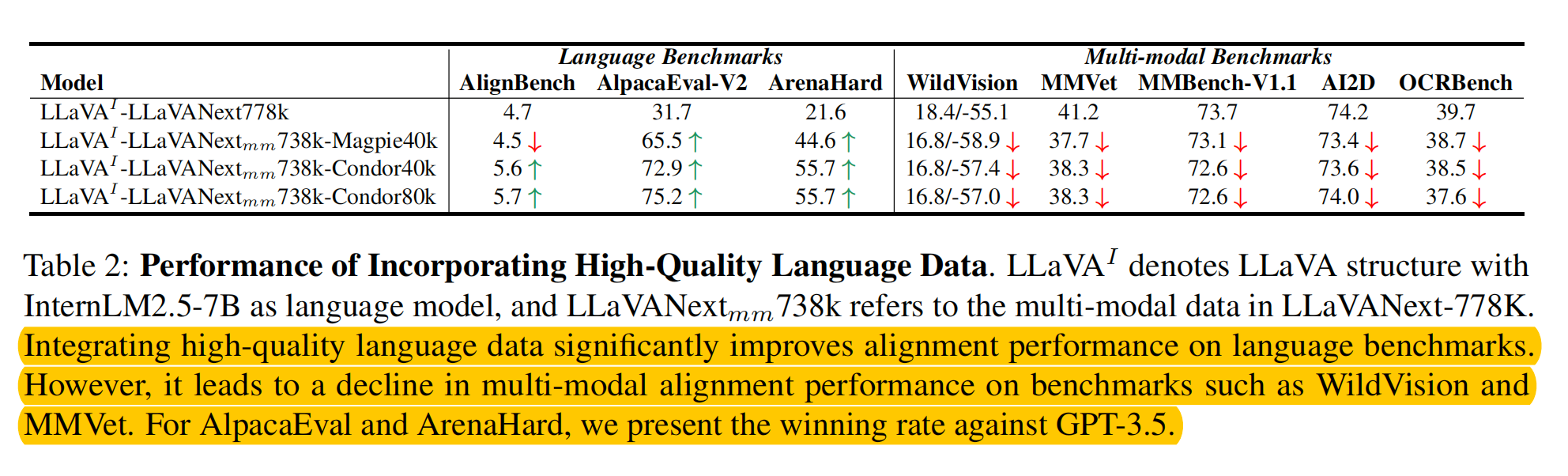
- Human Alignment能力下降证明:
- 所以作者提出,还是现阶段开源MLLM的训练数据太单调了,没有复杂的指令,所以得先扩充下开源的数据集。
具体方法
数据分类 & 数据选择
| 大类 | 二级 | 数据合成方法 |
|---|---|---|
| 自然图片 | 知识类 | 知识类和推断类,GPT-4o的多样性很高,能对不同细分类使用一个简单的prompt,针对问题构造出多样性较高的问题,因此直接用单一prompt + 细分类few-shots,多样性可以很高。 |
| 推断类 | 同上 | |
| 创作类 | 单一prompt较难给出多样性问题,所以作者预先构造了一个问题集合,并用较小的MLLM给图片先打了Caption,然后再让一个LLM做分类问题,从问题集合中选择几个相关性最高的问题,做few-shots,再prompt GPT-4o构造数据 | |
| 高信息密度图片 | 艺术类 | 从简单问题派生出需要一定背景知识才能回答的问题。 |
| 表格类 | 同上 | |
| 图表类 | 同上 | |
| 画报类 | 同上 |
目标:选择高质量且信息量较大的图片
- 图片复杂度过滤:把一些较为简单的图片从数据集中过滤出(因为这个工作目标就是构建高复杂度数据集),使用IC9600模型,能根据物体数量过滤。
- 使用Recognize Anything模型过滤复杂但语义含义很低的图像;
- 数据合成
质量提升
- 增强多轮Instruction QA的能力,例如在某个回答后,要求把答案分成几类中的某个,或者把字数缩小到xx以内。这一步是用LLM做的,并且与Visual content无关,这个问题集合也是作者设计的。
- 增强推断能力:在正常的推断回复后面加上了一些相关知识背景,从而让得到的答案更加可信。
- OCR任务增强:即使是GPT-4o,在这里也经常犯错。所以作者提出把GPT-4o和各个MLLM展现区别较小的数据作为最终的数据,把discrepency比较大的数据丢掉(现在大部分MLLM都有从GPT-4o蒸馏出的数据,各家训练数据也都差不多,所以这里很可能是大家都错了或者都对了)
- DPO数据集:作者使用LLaVA-Next的原生Baseline用high temperature生成很多回复,再用LLM做pair-wise的选择(这里的bias也可能很大,LLM可能会更倾向回复更长的答案)
- Benchmark数据集:从SAM-1B,CC-3M-Test中过滤掉低质量和不太多样性的数据集后,再用GPT-4o创造很高多样性的问题,最终形成这个Benchmark
评估结果
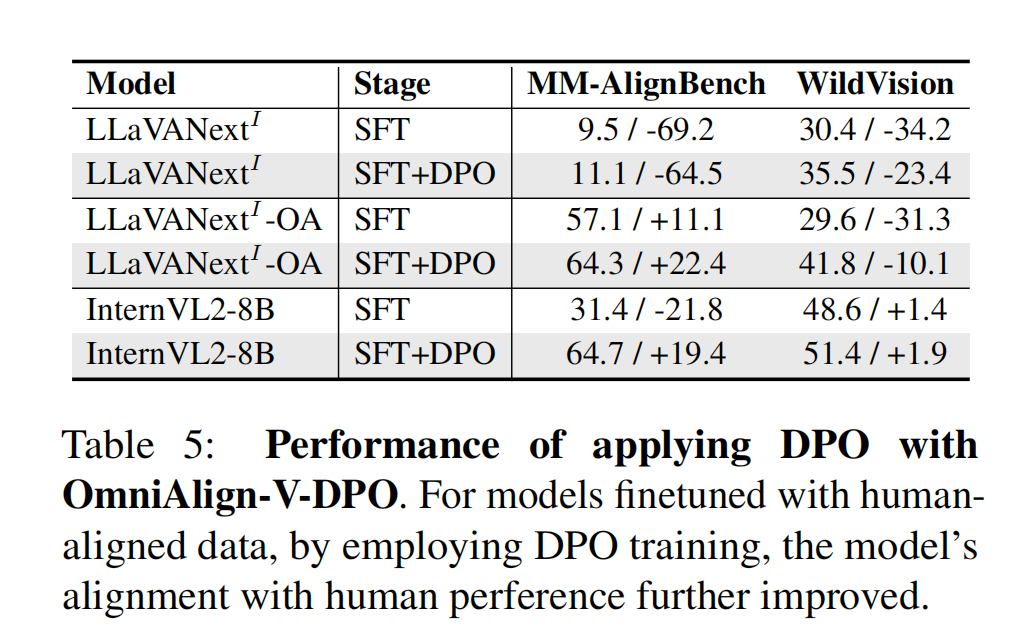
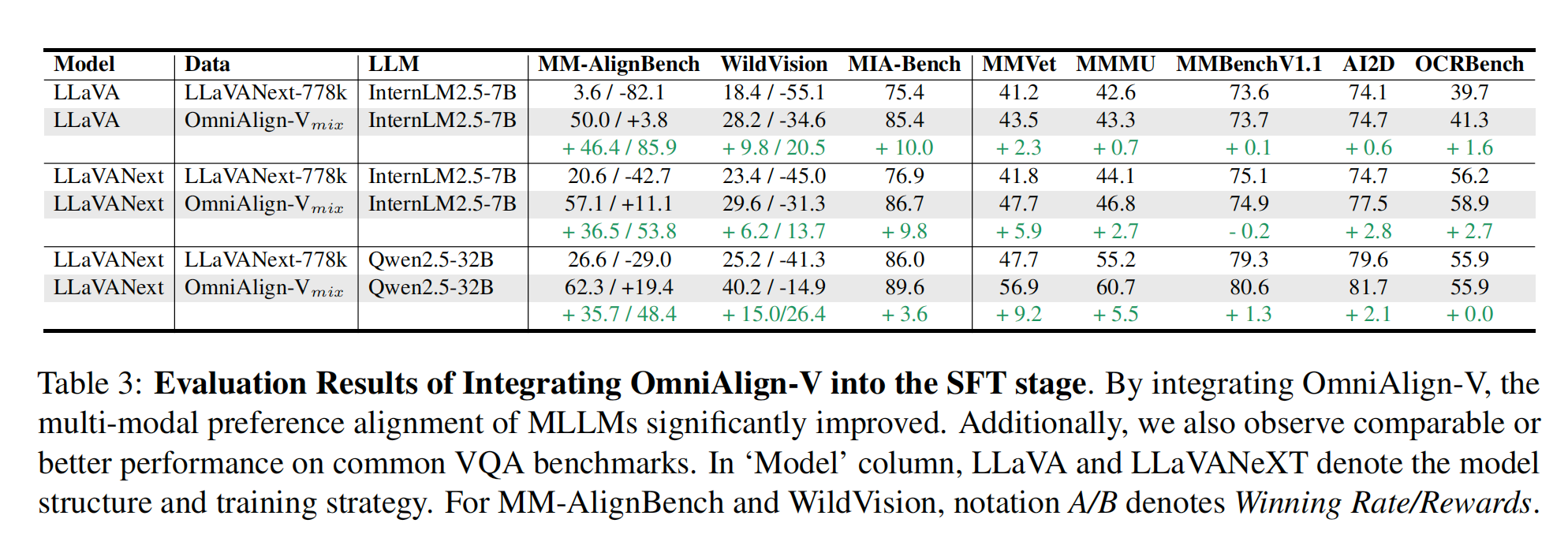
在SFT数据集上训练过的模型明显都比之前取得了更高的成绩。
结论
- 公开了数据集跟数据合成方法的都是大善人,我就不过多强调了;
- 其中DPO数据和SFT数据的部分合成方法比较有风险,因为引入了太多LLM和MLLM评判的部分,可能这些模型在类似的数据集上训练过都有相似的bias,导致最终输出的数据质量没那么高;
- 但是瑕不掩瑜,都开源了数据和模型了,就别要太多自行车了,唯有感恩。
PREVIOUSAI算法