RL给不了新知识,只是激发了Base Model的能力罢了
今天的思考来自于这篇论文:Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model? 这篇文章的主题就是我的标题,RL不过是让Base Model朝向一个更能给到正确答案的方向结题罢了,但实际上Base Model不会的题可能永远不会,会的偶尔能做对,RL能增加这个做对的概率。
Key Insights
- 尽管RL后的模型能够在pass@k(k=1)的情况下超越Base模型,但是Base Model在k的大小不做限制情况下,可能比RL后的模型pass率还高;
- RL优化的,只是Base Model在Sampling时候的效率,一方面增加了Base Model一次就能做对题的概率,但同时限制了模型的探索能力,这也导致了在增加pass@k的k时候,Base Model做对题的概率反而增加了;
- 除此之外,作者发现,数据蒸馏是真的能增加模型的知识,让模型有可能做对更多的题。
具体过程
首先作者提出了一个很有价值的问题:直接对Base Model进行RL,能提升的模型Reasoning边界到底在哪里?所以,
- 验证Reasoning的pattern是否在Base Model中就出现了?
- 是,作者用了perplexity(PPL)指标,这个指标是模型产出正确Sequence的概率的对数求和均值的指数,作者发现RL模型的PPL和Base模型的PPL差不多,这说明能产出正确答案的概率分布可能已经Encode在Base模型的概率分布中了,并非RL提升了原本的Reasoning能力;
- 如果Base模型原本就有reasoning能力,那能否想办法让Base模型做对题?
- 作者提高了对模型进行Sample的次数,并且得到下面的曲线;Base模型虽然一次做对的能力不如RL模型,但是只要做的次数足够多,甚至能比RL模型还好!这甚至说明了RL限制了Base模型的解题思路,在某些时延不敏感的情况下甚至可以不用RL。
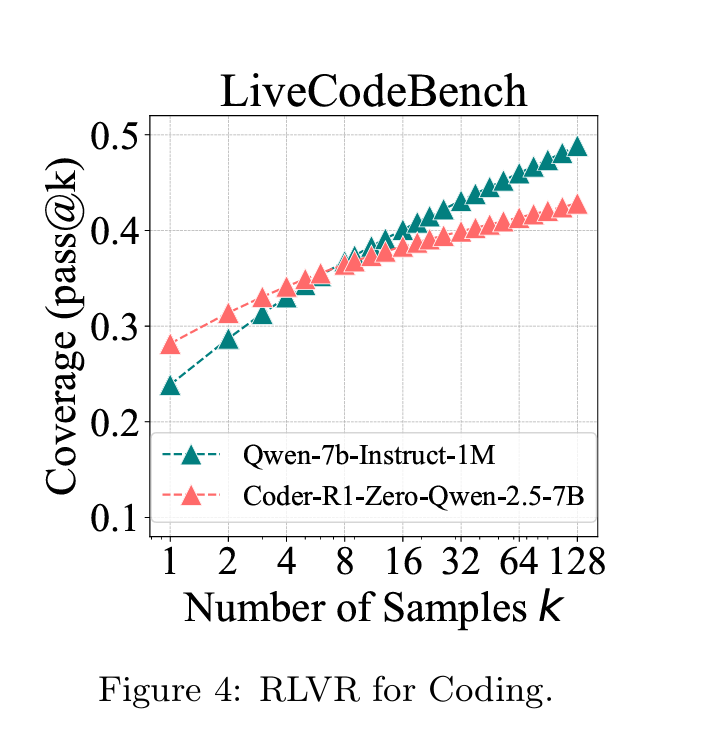
- 对比使用CoT对模型进行Finetune,哪种方法更能激发模型的做题能力?
- 作者用从R1蒸馏的数据对模型直接进行CoT Finetune,在同样的多次Sample看pass结果上,得到了如下曲线;证明CoT确实是在Base Model上进行了足量的提升,超越了Base Model原本的质保,并且也比RL的结果更好。但这个图里面很奇怪的是Instruct的模型甚至没有Base版本在AIME24的表现上好?
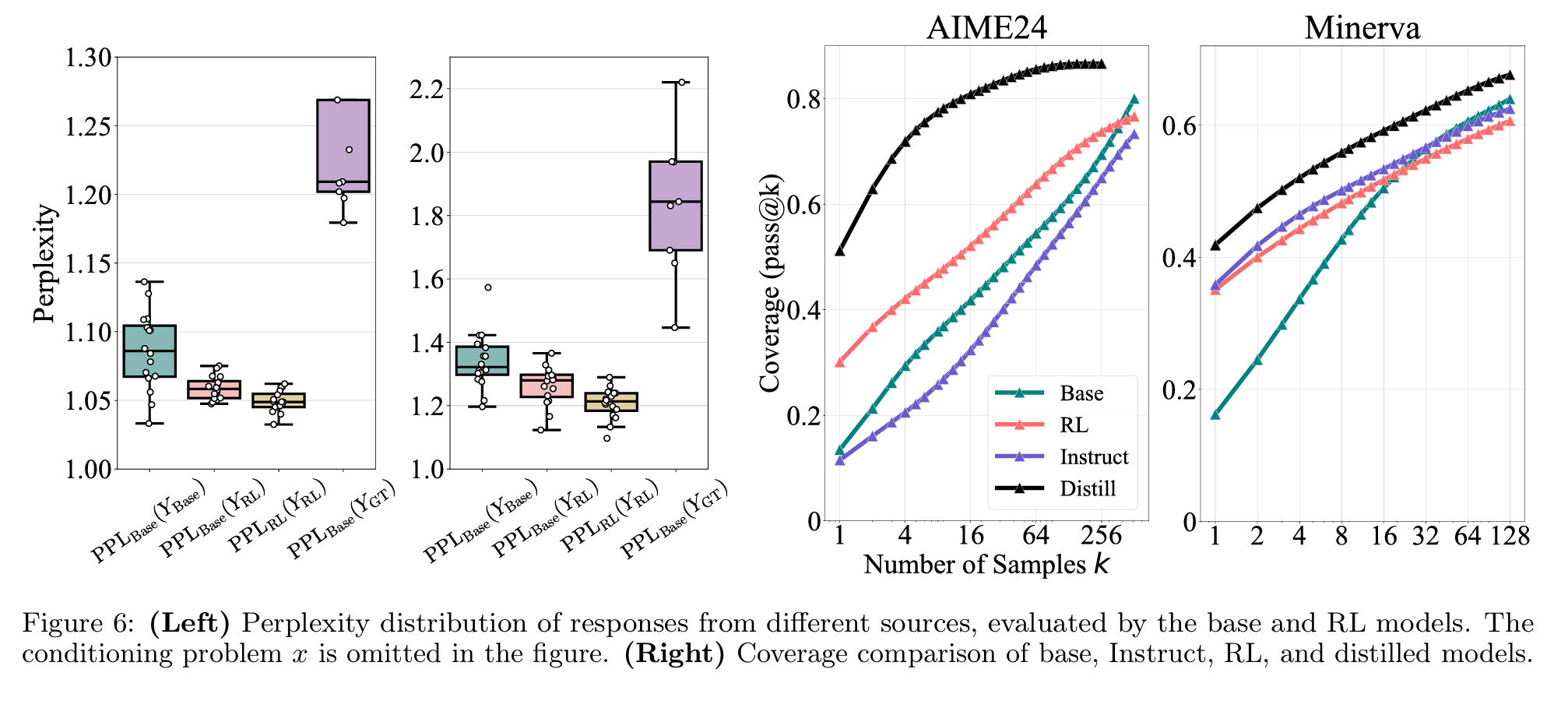
- 为了避免以上结论有偏差, 作者又实现了不同的RL算法,比如PPO,DAPO,GRPO等,确认以上结论是只对单一RL算法生效还是对所有RL算法都生效,得到的结论是不同RL算法带来的RL整体的差异并不大。
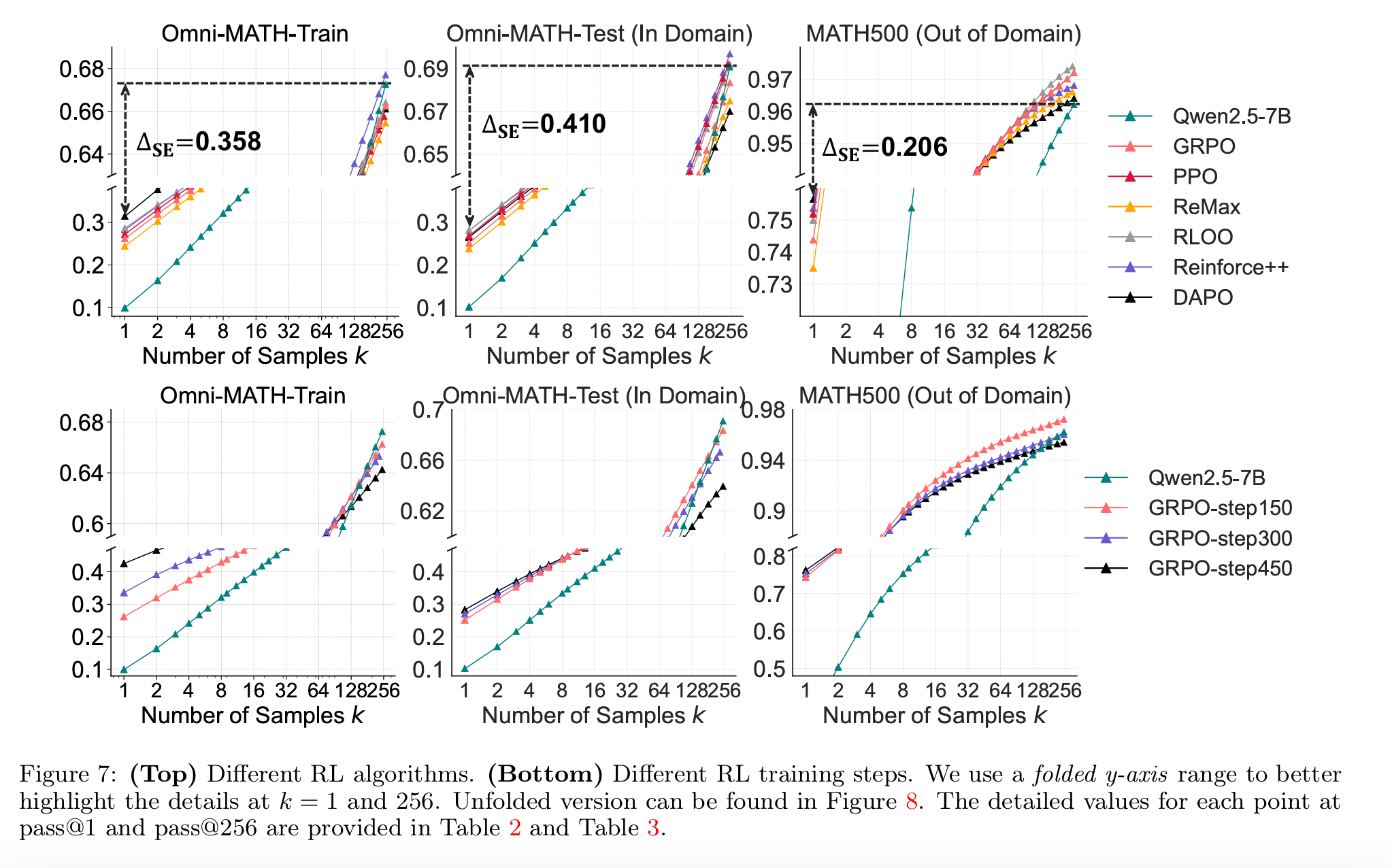
思考和结论
我个人非常喜欢这篇文章最后的Discussion环节,我认为作者的思考非常深入。
- 为什么在AlphaGO和玩游戏中,RL是能够发掘新的胜利pattern,而LLM中的RL不行呢?
- 作者认为原因在于一个LLM的输出token的概率空间要比游戏的概率空间大很多,因此使用RL优化LLM是个更难的问题,并且Reasoning经常是从Pretrain Model开始训练的,而Pretrain模型本身受限制于预训练的语料,训练游戏的一般都是随机初始化,这也导致了可能Pretrain模型本身就不包含所有能解决问题的先验(比如一个问题永远答不对,Reward永远是0),而随机初始化的可能本身就存在可能为1的情况,RL才有可能找到正确答案。
- Pretrain模型的先验知识的限制太强了,导致了模型可能稍微要探索下说话空间,都会因为错误的格式或者语句不通被干掉,因此导致即使有可能导出正确答案,也会因为中间步骤产生问题,而永远失败;
- 最后一点,是作者提到但是没具体讨论的,就是目前的RL算法本身的设计也可能是这个结果的原因之一,比如PPO算法中的KL Divergence,本身就约束了模型前后的概率分布不能差别过大,而约束了概率分布的差异就潜在的限制了模型探索便宜Base模型的先验,探索正确答案的可能性。
- 个人的一点想法:之前有很多人偏向认为,RL能泛化到不同任务,SFT能记忆知识点,还有R1-zero的结论等等,现在整体开源社区的探索深入了太多。就解题本身而言,我们可以做一个比较好的Base Model(很多Base Model都已经指令微调过了,只是没有复杂指令,所以你很难说那就是一个简单的Pretrain Model,毕竟Pretrain和SFT的学习模式也基本一样),然后在这个Base Model上进行RL,提升其解决某类问题的能力。
- 另一个我一直在想的问题,CoT本身是什么,为什么能提升答案的准确性?我想应该就是Think out loud。对于有答案的问题,我们要看其解决问题的步骤是否有错误,看结果是否错误;对于开放类问题而言,CoT就是增加回答的可信度罢了,其本身还是结构化思考,言之有理即可,是另一种的模型可解释性的体现。但我想,即使对人而言,think out loud本身就能帮助很多人思考问题,比如写文章就是一个think out loud的过程,因此,CoT的路线应该可以比较鉴定的走下去,但我认为模型收到的思考限制应该更少一点,即,即使思考是乱码也无所谓,牺牲一点可解释性,得到更好的结果,也许是一个更容易让模型探索结果的路线?极端一点,连我写这篇文章都是中英混杂的,对于不懂英文的人来说,这段夹杂在文章里的拉丁文语句,又何尝不是一段乱码呢?
PREVIOUSAI算法