小米多模态大模型 - 全是细节
结论
[!NOTE]
- 经过测试,MIMo会优先出reasoning,但是部分任务,例如OCR、Grounding,会直接跳过reasoning出结果,是否reason无法通过template控制,但调整prompt可能可以控制;
- RL并非对所有任务都有用,实际上部分OCR任务存在掉点情况,在做Post-train时候的指标变化情况可以借鉴。
Architecture
MiMo完全就是Qwen2VL的架构,甚至官方repo里面的inference代码都是用的QwenVLConditionalGeneration,这个无可厚非,Qwen确实是基座框架比较优秀的一批,选择这个框架做数据scaling训练也是很多多模态训练的首选。
Data + Training
现在多模态大模型训练已经比较成熟,使用Next Token Prediction(NTP)loss的训练,基本上都算作pretrain,
- 对这个过程区分不同的stage,逐步实现质量由低到高,Sequence Length由短到长。
- 数据也基本follow Caption->Interleave->多任务->Long context
- 训练阶段基本follow MLP -> ViT + MLP -> All的流程。
Benchmark
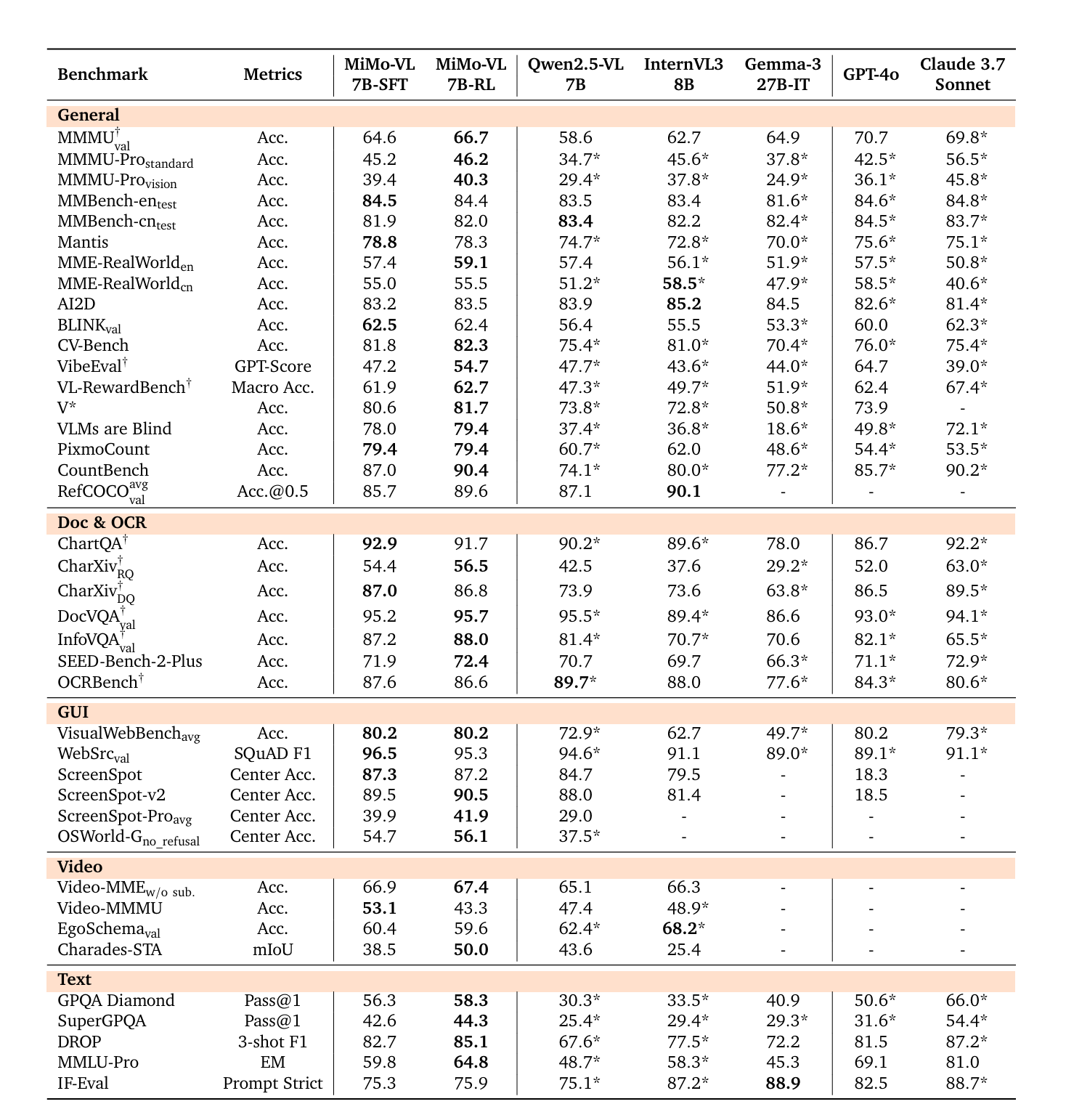
整体指标从下面可以看到,RL后模型表现更好的,往往是训练集中有Verifiable Reward的Benchmark,比如CountBench,MMMU这些,OCR任务甚至有点下降。
总结
- 整体来说,小米这篇文章和字节之前的Seed-1.5-VL那篇文章都很好,都有很多可以借鉴的地方,小米的文章在数据处理方面的介绍更加详细,借鉴意义更高;
- 训练模型最重要的就是数据,这篇文章中也可窥见一二,如果现在做大模型还没有构建起自己完整的数据处理方法论,就有点out了。
Appendix
试用了下小米的模型,并非所有任务都可以reason,例如下图,模型会跳过think直接输出答案;
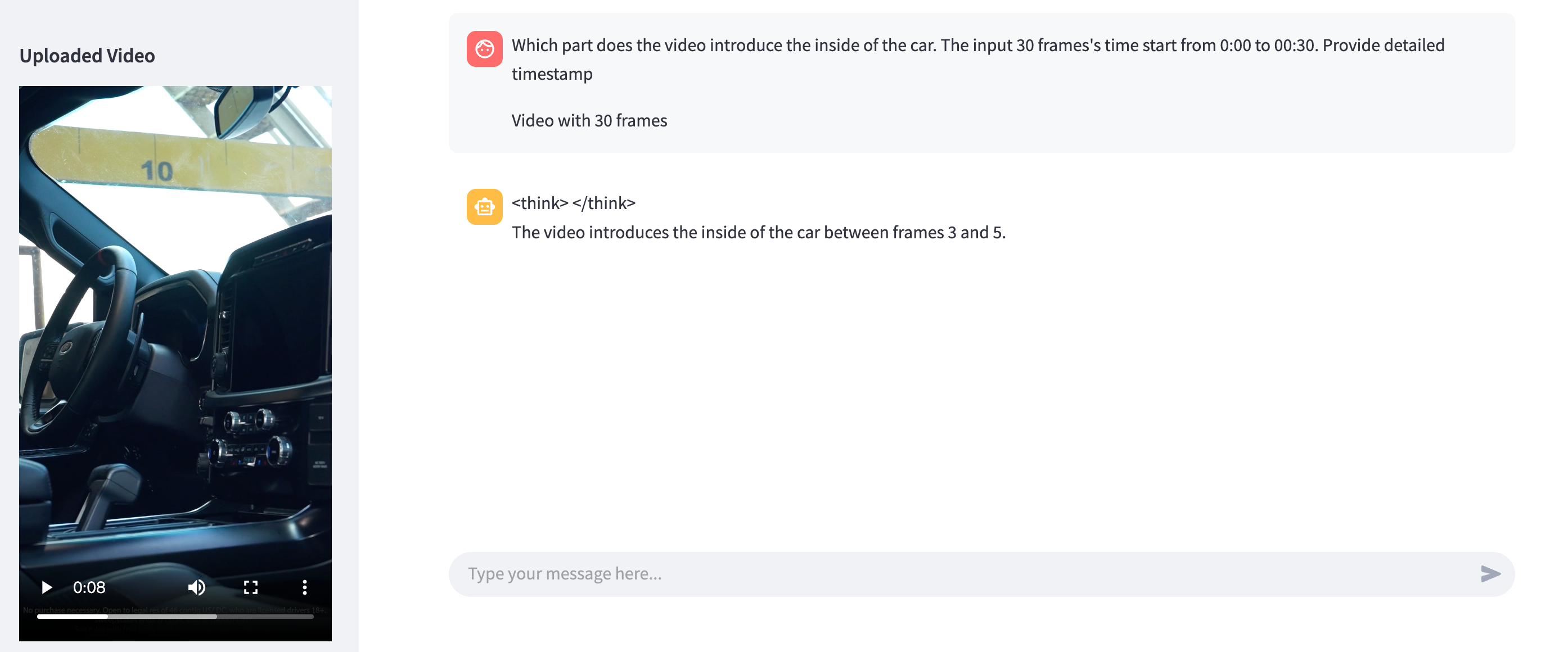
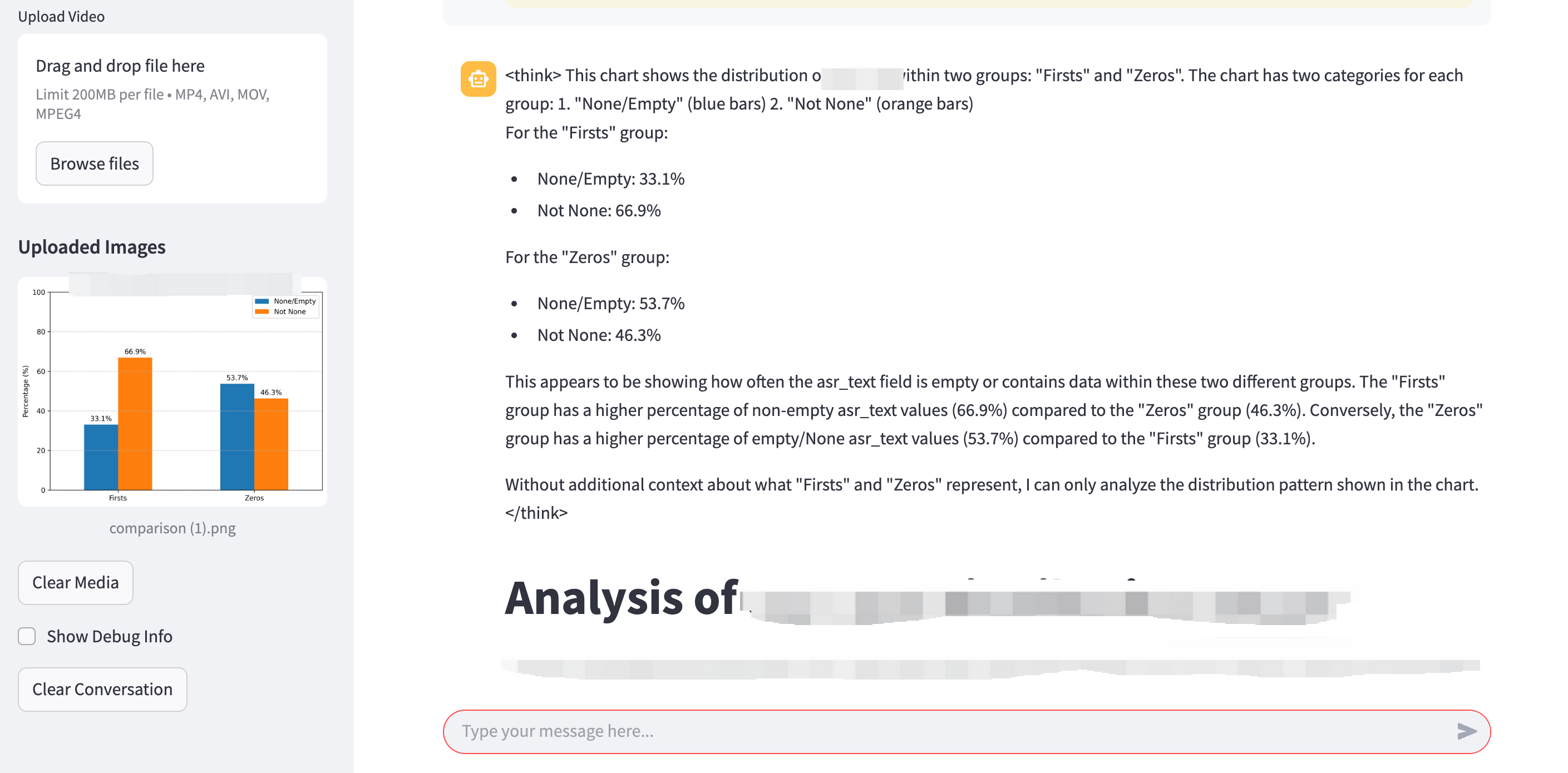
在没有更改prompt template的情况下,分析一个图标,模型会自动吐出output tag。
PREVIOUSAI算法