VLM RL如何涨点 - 实践和思考
前言
过去的一个月在比较高强度做RL,最近终于有了一些阶段性成果,整理了一下整体的迭代思路和最近踩过的坑,分享出来,与各位共勉。结果上,部分Benchmark取得了同size 模型1-2个点的涨幅,最高的单项能有8-10个点的涨幅。这个过程最大的感触是
- No Silver bullet,从目标出发规划,做对10件小事,比做1件大事重要的多;
- 没做好数据基础就开始研究新算法的,要小心了,很可能长期做不出结果;
- 基础的RL算法,就能有较为明确的涨点,即使目标是做开源SOTA,也可以从最简单但正确的事情做起,千里之行,始于足下。
RL的目标
关于RL,我们不是第一批吃螃蟹的人,有很多前人的工作可以追溯,所以是站在巨人的肩膀上做事,对结果有一定预期。因此,基于开源tech report的结果和认知,我认为RL至少应该达成以下两个目标
- 在SFT的模型版本上取得1-2个点的整体涨点;
- 在RL特定的Benchmark上(例如数学、指令遵循、幻觉避免等)取得超过1-2点的涨幅。
RL整体思路
我认为RL的本质,是提高sampling efficiency,而并非能让Base Model学习到新的知识,关于这一点,我之前的博客里面有过论述,总结一下主要来自于两个结论
-
如果让Base Model无限次数回答问题,其正确的概率比RL过的模型更高:在Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?这篇文章中,作者做了较为详细的Ablation,增加pass@k中k的次数,随着Sample的次数增加,RL能答对的累加概率逐渐不如Base Model;
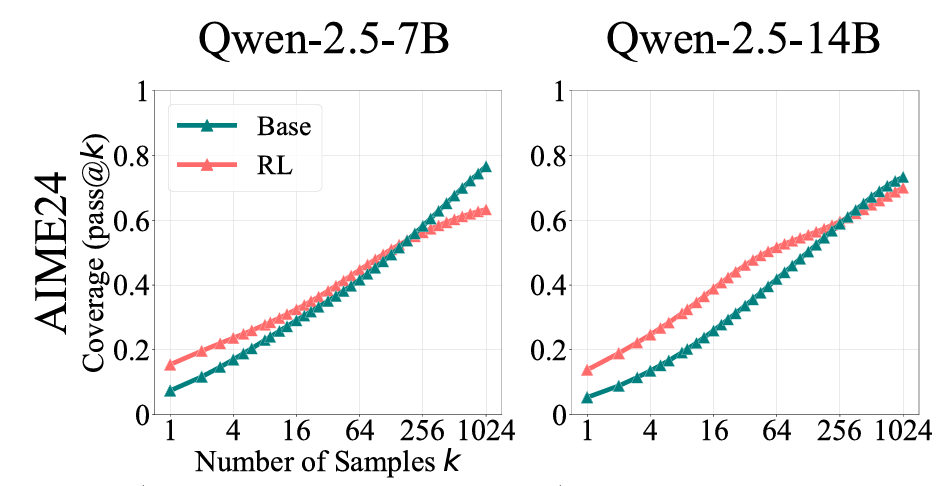
-
VLM RL的tech Report中,RL的版本整体涨点在1-2左右,而SFT最高可做到5-6个点:这个在很多Tech Report中都有验证,就不做详细引用了。
因此RL的本质其实就定了,和SFT的后训练相比,一定要基于Base模型Sample,如果你试图用别的模型回复作为好或者坏的回答,或者试图用一份数据来更新所有模型,可能是无法work的,RL的关键是一套完整的流程,而不是一两份已经成型的数据。
VLM RL难点
- 任务层面,指标要求全面:Benchmark的所有子项能力都要提升:在工业界做模型,需要模型的各项能力,例如OCR、推理、数学、指令遵循等都有提升,而不能只对某些Benchmark做到极致;
- 训练层面,infra要求高:RL不同于SFT,on-policy或者off-policy的RL都需要对原始模型Rollouts,前者的挑战甚至更大,需要同时对模型backward和多组forward,训练效率挑战极大;VLM的RL面临的infra难题更多,因为多媒体数据的引入导致IO、硬盘和内存都会成为瓶颈;
- 数据层面
- Input上,数据混合的平衡要求高:RL对数据的敏感度比SFT要高很多,SFT在数据量级不高,学习率不大情况下,一般训练完可能有掉点,但不一定很大;但RL在一份混合不够完善数据上训练,可能带来全面的掉点。
- Output上,回复长度和RL的算法相关度较高,各个RL算法,对数据的要求不太一样,比如GRPO,会做group-wise的Reward均值到各个token(即Policy)上,而DPO是两条回复的token-level的prob对数的sum相减值的margin,所以不同RL算法对于长度的感知不同,
- Reward Model或者LLM Judge需要特殊优化,RLVR某种程度上淡化了Reward Model,但实际上对于alignment或者OCR相关Benchmark,无法用Verifiable Reward来判别,则还是要通过RLHF等方法进行优化。
- 算法层面
- 算法选择,当前RL算法的探索非常前沿,如何能选择高效、上限高的RL算法,比较考验算法工程师的判断能力。
我们的做法
技术选型
首先,我考虑到了infra的困难程度,开始项目的时候,Verl的框架针对VLM尚不成熟,数据IO和训练都有较大问题,而我们想快速验证RL的能力,于是我们选择了infra成本较低的DPO RL算法。DPO的优缺点非常鲜明,主要是
-
DPO是off-policy的RL算法,
- 优点:①数据可以单独进行离线rollouts,可以提升单次训练的效率;②Rollout后的Reward评分,可以用很多模型实现,能把数据做精细;③无需引入在线RM,训练效率较高,infra要求较低;
- 缺点:DPO的accept和Reject Pair是由基础模型生成的,训练到后期这批数据已经无法反映模型的效果了,这也导致了其天然不如on-policy RL训练上限高;
-
如何最大化DPO的收益?
-
从DPO的loss Function出发看数据的潜在影响:
- \[\mathcal{L}_{\text{DPO}} = \mathbb{E}_{(x,y^w,y^l)} \left[ - \log \sigma \left( \beta \cdot \left( \log \frac{\pi_{\theta}(y^w | x)}{\pi_{\text{ref}}(y^w | x)} - \log \frac{\pi_{\theta}(y^l | x)}{\pi_{\text{ref}}(y^l | x)} \right) \right) \right]\]
-
求导之后发现,DPO更新的本质,就是最大化Accept回复的每个token的prob sum和Reject回复每个token的prob sum的margin。
- 细致观察就能发现,这个算法对于回复的长度非常敏感,长回复的loss会stable一些,而短回复,类似分类或者选择题,loss就不会非常stable;
-
-
原文中的训练细节
- 对于不同任务,$\beta$值是不同的,简单来说,长回复的任务,这个值相对较高;否则相对较低;
- 如何理解$\beta$,这个值是等价于PPO中的Clip ratio,决定了模型到底在一次更新中的步长(和原来概率分布的差距的大小);作者在这里的分类问题设置了较小的值,我判断也是为了防止某单个短回复更新过大导致模型训练有问题;
- 对于不同任务,$\beta$值是不同的,简单来说,长回复的任务,这个值相对较高;否则相对较低;
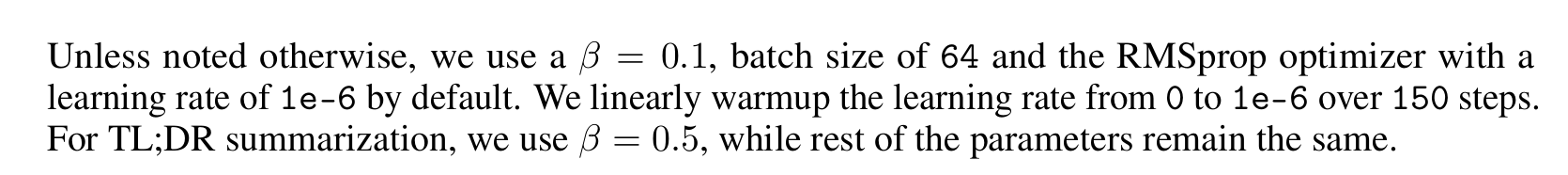
数据组织
先说重点和结论,总结下踩过的坑
-
回复太短了,训练效果很差,对训练效果帮助不大
- 找Rollouts的一组里,差异较大、且有真正对错的的组成pair,否则训练效果不好;
- SFT阶段如果必须混合选择题和长回复,否则评Benchmark会因为不直接回答ABCD而掉点;但是DPO时候,全用长回复是没问题的,效果会稳定提升
- 最重要的一条:认真check你的每一条数据,以上结论全都不绝对,实际训练效果跟你的数据分布、训练超参、回复pair-wise构造都关系非常大,没有Silver Bullet,只有绝对的细心和认真,清晰的实验目标制定和严谨科学的分析实验结果
数据侧我主要分成两个部分
- DPO的prompt库,数据Mixture,能力分类;
- DPO的pair-wise数据构建逻辑;
Prompt库构建
基于之前对原文和DPO公式的理解,我们尽量避免回复特别短的Prompt,测试下来两个方法比较有效
- 针对数学类、推理类有正确答案的任务,构造能引导CoT回复的Prompt格式,这样能把ABCD的回复有效扩展为长回复;
- 针对OCR、开放式回答类任务,直接过滤掉短回复;
还在测试的一些方法
- Prompt rewrite,结合答案,直接改造成开放式问题;
数据Mixture
我不会说明具体的数据配比,能比较明确的是,尽可能让不同任务的数据比例平衡。这里有个质变的过程,一旦数据混合搞对了,基本上能看到所有指标的涨点,任务之间彼此有帮助,而不是有升有降最后差不多持平。
Rollouts过滤
Rollouts一定要满足两点要求
- 尽可能收集差异较大的N个回复;
- 保证回复的Accept和Reject有明确的好坏区分;
Pair-wise构造
这里基本上是DPO最重要的部分,拆分下来应该有几类方法
- 使用开源的Reward Model;
- 基于开源的RM或者$\pi_{sft}$模型训练一个RM;
- 直接使用VLM Judge做pair-wise数据构建。
第3点由于DPO的数据可以离线构造,所以可以做的相对细致。
从成本由低到高来看,2需要引入额外的RM训练和评估,成本较高,因此可以从1和3先尝试。
结论
- 想直接用开源Reward判分的,需要谨慎:我们之前试过直接用开源的打分,发现模型会比较偏向有明确答案的,答案偏短的数据;当然可能我们的测试不够充分,开源Reward可能有更好的但是我们没有使用到;
- 基于现成的VLM做Judge进行数据构造
- 需要做好数据分类:不同的任务类型,例如有明确答案,verifiable的,我们试过用Qwen-2.5-VL 32B的VLM进行标注,和GPT标注的F1 Score能达到0.95以上;因此,对于verifiable的任务,使用medium size的开源VLM Judge就已经可以实现较好的效果;对于Alignment类的任务,此类任务较为鲜明的特点是没有标准答案,但是这部分任务对于减轻模型的幻觉,提升通用能力比较关键;我们验证下来比较有效的做法是让VLM根据GT回答,对多个Rollout的结果在事实、幻觉、与GT风格相近程度等方面进行打分标注,并根据评分排序得到pair-wise的数据集,当然这个过程中一定注意作对评估,验证打分的人工评估准确度,甚至可以对不同能力分类或者数据集做单独的数据策略,以确保大规模的pair-wise构造是正确的。
实验过程
- 直接使用GT作为Chosen,使用Rollout的结果作为Reject是否可行?
- 不行,训练得到的经验是,这样会导致模型训练快速饱和,同理,使用某个固定的模型结果作为Chosen(例如GPT的回复),使用Rollout作为Reject,也会让训练快速饱和。我们猜测模型学习到了某些shortcut,或者某个pattern,而不是真正提高了sampling efficiency;benchmark的评估结果也验证了我们的猜想,这样训练得到的模型评估基本没有变化。
- 不行,训练得到的经验是,这样会导致模型训练快速饱和,同理,使用某个固定的模型结果作为Chosen(例如GPT的回复),使用Rollout作为Reject,也会让训练快速饱和。我们猜测模型学习到了某些shortcut,或者某个pattern,而不是真正提高了sampling efficiency;benchmark的评估结果也验证了我们的猜想,这样训练得到的模型评估基本没有变化。
- Training Dynamic长什么样是训练有效果的?
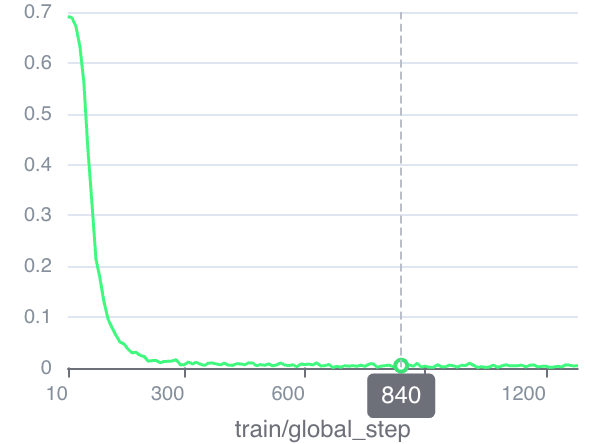
- 使用TRL仓库原生的DPO Trainer,会记录一个Reward Accuracies的值,这个值的计算逻辑是:
reward_accuracies = (chosen_rewards > rejected_rewards).float(),根据我们的训练经验来看,accuracy在不断增长,模型的训练效果往往是更好的;但是这个accuracy的绝对值在不同实验之间没有太多参考价值,因为这个值是相对训练数据而言的,不同实验的数据可能不同,这个值没有可比性; - 这个值和benchmark是否有关联关系?目前观测是没有的,毕竟这里的acc其实是一条回复的trace的log_prob sum,所以很可能真正的答案被稀释了,比如,模型在一本正经的胡说八道,用正确的reason得到了错误的答案,虽然这条回复的acc可能很高,但并不能带来增量;
- 那如果把答案就变成ABCD这种一个token的回复,岂不是正好能解决上述问题?从训练结果上看,回复过于简短会导致DPO训练崩溃,虽然Acc能直接代表作对的比例,但是训练本身效果会变差。
- 使用TRL仓库原生的DPO Trainer,会记录一个Reward Accuracies的值,这个值的计算逻辑是:
总结
VLM的RL的几个大块,数据prompt的混合,数据Rollout,pair-wise数据构建,以上几个事情作对,模型是一定有涨点的;主要还是要细心,有耐心,多看数据,把事情做对即可。
对于以上工作,我们的探索还远没有结束,DPO的训练简单告一段落,后续会投入到VLM的Online RL训练中,这里也有很多未知的挑战等着我们,有效果了会继续跟进我们的实际效果,感谢大家关注。
另外,最近在上海看了《衔尾蛇之歌-中西女性视角下的艺术和收藏》,推荐大家闲暇时间可以多多去线下看看,线下的艺术作品往往是人灵魂的映射,真实且真诚。