深挖Ovis-2.5技术细节
前言
阿里发布的基于Qwen3 LLM backbone的VLM,9B模型创下了40B大小下的SOTA指标。这种涨点一般来自于两个方面,首先LLM的升级,一般都能带来视觉推理类任务的提升;其次,数据和训练方式的升级也能带来提升。虽然技术报告一般不会透露过多细节,但一般来说看下还是能带来一些新的启发,细节是魔鬼,做好细节就能成功。
模型架构
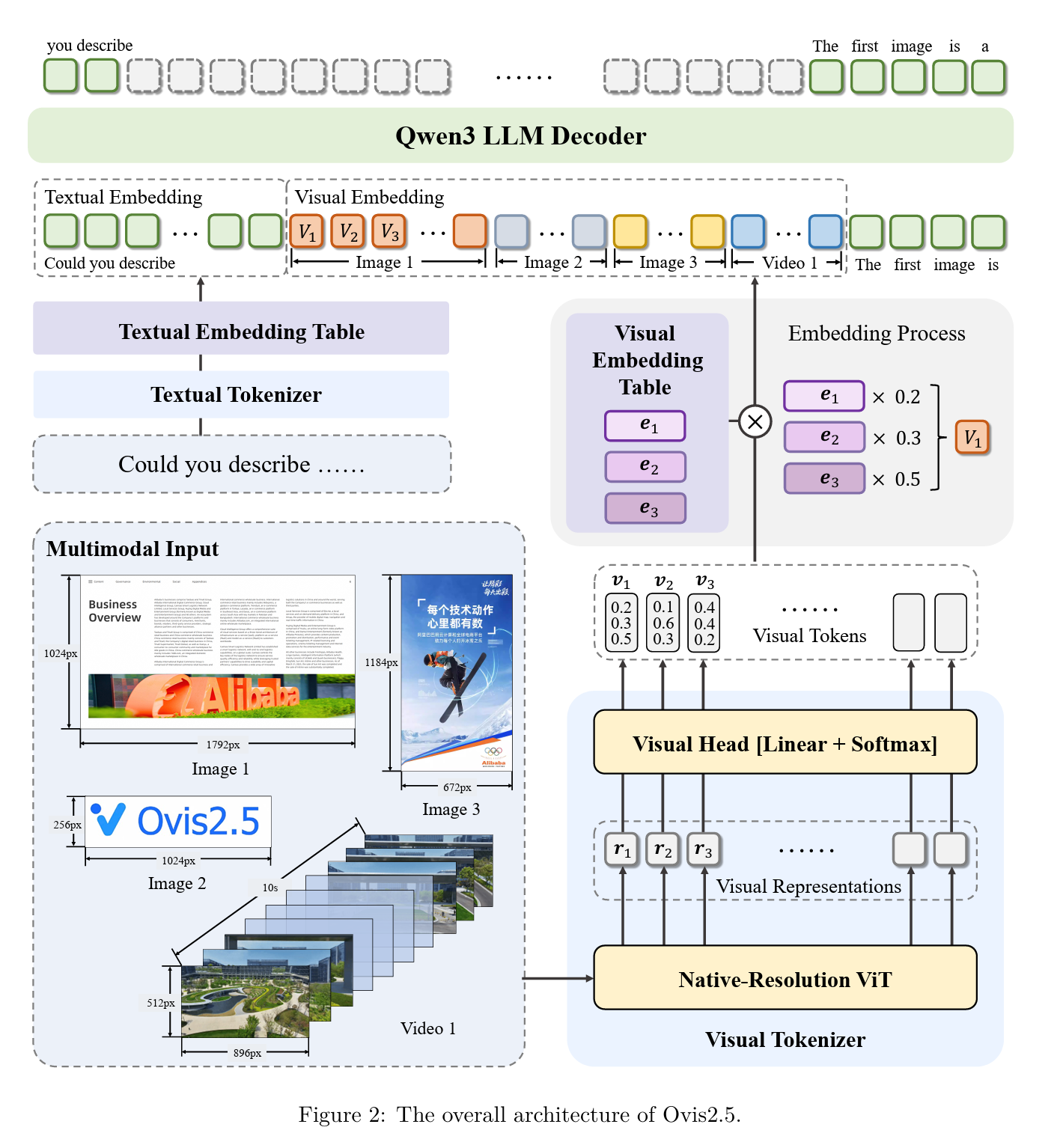
和QwenVL的有所不同,Ovis没有把NaViT的结果直接做pooling投射到LLM的embedding space,而是把Qwen25VL的PatchMerger变成VisualEmbeddingTable,转化为Vision tokens(默认的vocab_size为65536)。
代码区别:
Qwen2.5VL的Pooling + MLP投射
class Qwen2_5_VLPatchMerger(nn.Module):
def __init__(self, dim: int, context_dim: int, spatial_merge_size: int = 2) -> None:
super().__init__()
self.hidden_size = context_dim * (spatial_merge_size**2)
self.ln_q = Qwen2RMSNorm(context_dim, eps=1e-6)
self.mlp = nn.Sequential(
nn.Linear(self.hidden_size, self.hidden_size),
nn.GELU(),
nn.Linear(self.hidden_size, dim),
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.mlp(self.ln_q(x).view(-1, self.hidden_size))
return x
Ovis2.5的tokens映射
class Ovis2VisionModel(Ovis2PreTrainedModel):
config: Ovis2VisionConfig
def __init__(self, config: Ovis2VisionConfig):
super().__init__(config)
self.config = config
self.transformer = Ovis2VisionTransformer(config)
self.num_visual_indicator_tokens = config.num_visual_indicator_tokens
self.vocab_size = config.vocab_size
self.head_linear = nn.Linear(
config.hidden_size * config.hidden_stride * config.hidden_stride,
self.vocab_size - self.num_visual_indicator_tokens,
bias=False,
)
self.head_norm = nn.LayerNorm(self.vocab_size - self.num_visual_indicator_tokens)
def forward(self, pixel_values: torch.FloatTensor) -> tuple[torch.Tensor, torch.Tensor]:
outputs = self.transformer(pixel_values)
last_hidden_state = outputs.last_hidden_state
# Pixel values handling logic...
if self.config.tokenize_function == "gumbel_argmax":
prob_token = nn.functional.gumbel_softmax(logits, dim=-1, hard=True)
elif self.config.tokenize_function == "st_argmax":
prob_token = hard_softmax(logits, dim=-1)
elif self.config.tokenize_function == "softmax":
prob_token = nn.functional.softmax(logits, dim=-1)
return prob_token
class Ovis2VisualEmbeddingTable(nn.Embedding):
def forward(self, visual_tokens: torch.Tensor) -> torch.Tensor:
if visual_tokens.dtype in [torch.int8, torch.int16, torch.int32, torch.int64, torch.long]:
return super().forward(visual_tokens)
return torch.matmul(visual_tokens, self.weight)
看到这个架构有几个问题
- 这个是做Vision tokenization的方式,但Vision token的vocab_size才65536,真的能表征一个图片吗?
- 这个方法比直接pooling的优势在哪里?光从架构上看不出来,且由于加上了tokenization的过程,可能导致细粒度的感知力变差,直接导致OCR能力的下降;
PREVIOUSAI算法