推理阶段提升采样效率,同样可以达成RL的效果?
前言
在之前的博客中,我有提到RL的本质是提高Base Model的sampling efficiency,而无法注入新的Knowledge,印证这个认知的主要有一些开源社区的发现,比如
- 并非所有base Model都能被激发:在年初一波火热的RLVR训练中,只有部分LLM取得了和Deepseek类似的效果,例如Qwen系列可以,但LLama不太行;
- pass@k,随着k增加,base Model的表现优于RL后Model:在Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?这篇文章中,作者做了较为详细的Ablation,增加pass@k中k的次数,随着Sample的次数增加,RL能答对的累加概率逐渐不如Base Model;
因此,假设以上猜想成立,则如果我们在inference阶段,能够用一种方法提升pass@1,那么理论上base Model有机会在Training-free的情况下,超过RL后的Model。最近有来自Harvard的学者,发表了这篇文章:Reasoning with Sampling: Your Base Model is Smarter Than You Think,就探讨了这个问题,并提出了一个inference方法(还是增加了推理的成本,但是Training-free),能够逼近RL后模型的Pass@1.
方法引入
提升sampling efficiency的方法,本质上就是让能回答对的Sequence具有更高的整体概率。例如下图,本质上我们想sharpen回答正确的Sequence分布,等价于我们想sharpen一个token trace的分布。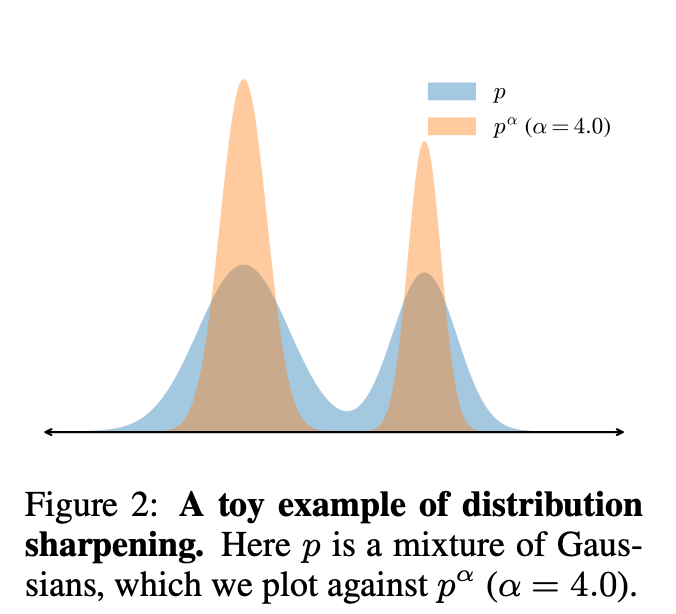
Sharpen一个分布的最常用的方法就是直接加一个指数(power distribution),实际上在Auto Regressive的生成方式下,给每个token sharpen的方法就是降低temperature,当足够低的时候,就变成了greedy decoding,只采用下一个概率最高的token。不过,直接增加sharpen每个token的生成分布(用low temperature),不等价于给整个Sequence的生成概率做了sharpen,作者在这篇文章中给了公式证明。不过即使没有公式证明,也很容易想通,类似于局部最优解,不一定是全局最优解,生成过程可能受到几个pivot token的影响,从而导致整体Sequence的生成概率变低。
因此,这里的关键就在于,如何能找到一个Sequence维度的$p^\alpha$(对原始Sequence的产生概率$p$的power distribution),从而能使整体的采样的分布被sharpen。
提出的方法
在Auto Regressive Generation的场景下,p(x) 是可计算但未归一(unnormalized),不能直接从 Target pᵅ 精确采样,因此就需要一种方法,能够在未知真实概率的情况下,尽可能模拟真实概率进行采样。所以,作者提出了一个基于Metropolis-Hastings方法的生成逻辑,可以想象为一种“不断更新的短期终局思维”。该方法
- 先把一个生成好的Sequence分块;
- 每个分块的随机位置计算Sequence的joint概率;
-
通过这个公式计算是否接受新的Sequence:$A = \min{{1,\frac{\pi(x’),q(x x’)}{\pi(x),q(x’ x) }}}$。
为什么要通过一个概率接受,是为了保证马尔可夫链严格收敛到指定的目标分布,而不是做 hill-climb 优化。
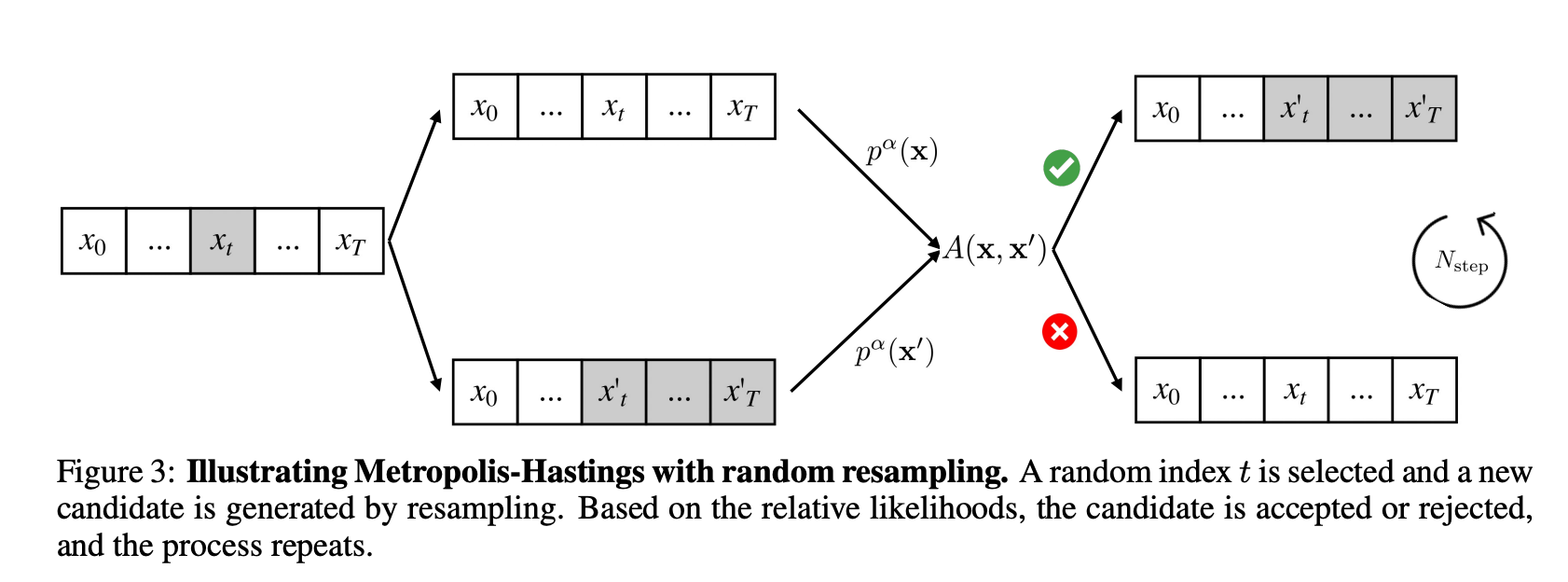
打个比方,就像一个人在走迷宫,在复盘自己怎么走能更好,并且有个计算器可以计算每一段路线的整体概率高低结果。这个人采用的方法是,把自己的路线分块,然后在每个分块看看自己有什么新的走法,如果新的走法整体的每一步加起来概率更高,就以一定概率选新的路线,直到自己复盘完毕。
结果
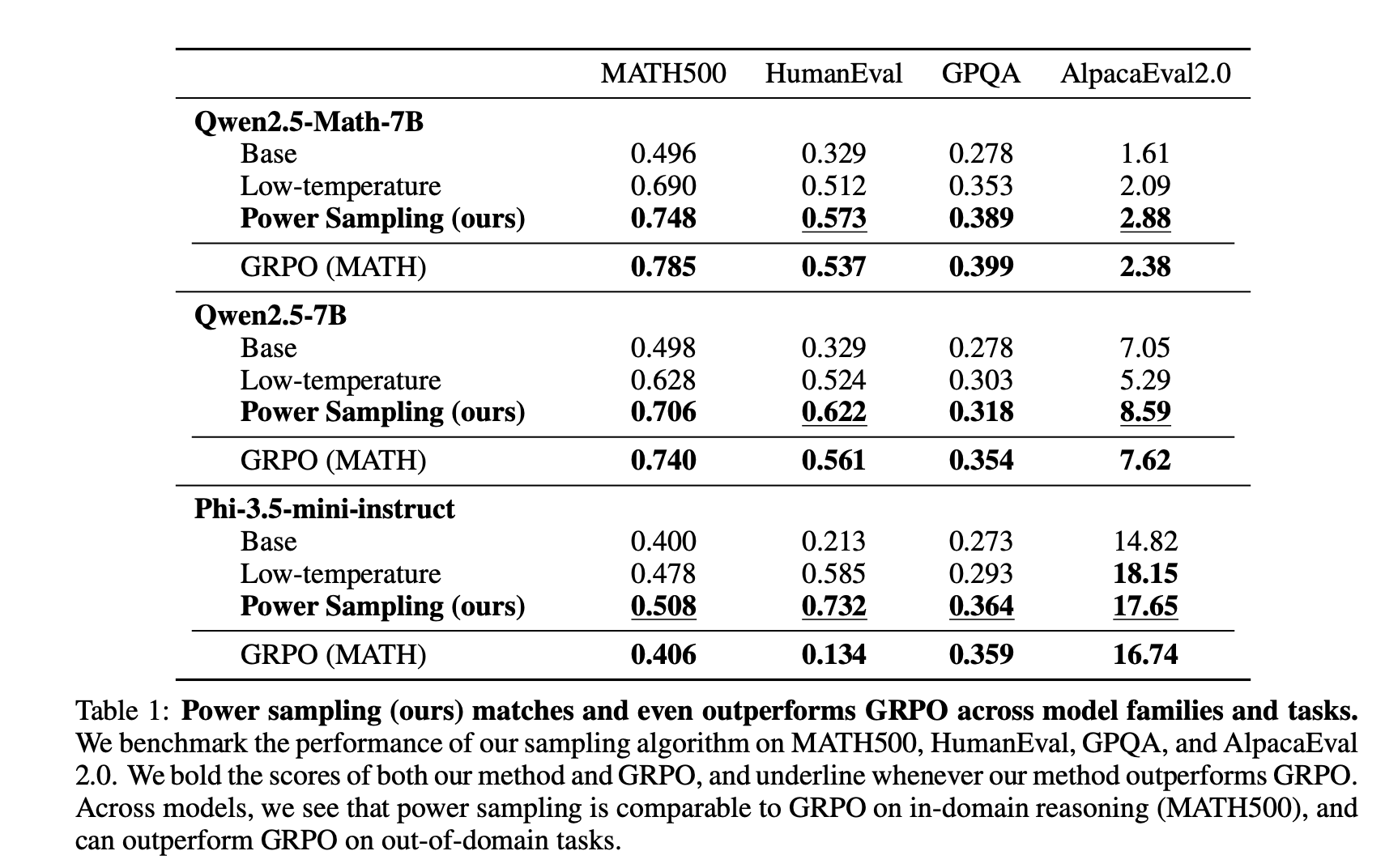
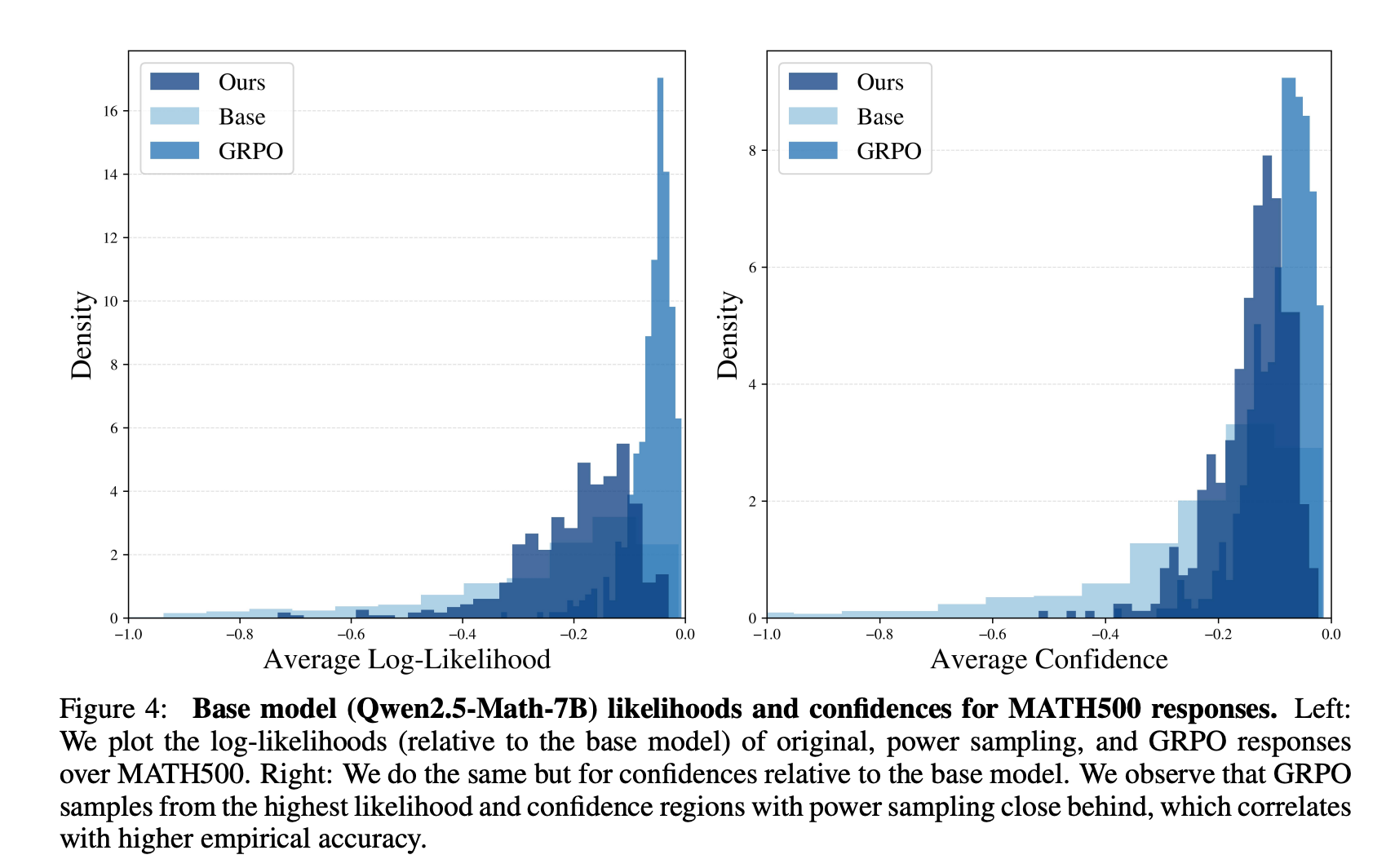
作者用自己提出的方法采样得到的结果,和直接进行GRPO算法优化过的LLM的指标是相近的:
| 和GRPO优化后的指标对比 | 在Math500数据集上评估生成Sequence的对数概率 |
|---|---|
 |
 |
同时作者也提到了,这个方法也能呈现出test-time scaling的效果,就是生成的Sequence的平均长度(679),和GRPO后的模型长度差不多(671),都比原来的Qwen2.5-Instruct要长很多(600)。
思考
这篇文章可以说是RL本质为提升Sampling Efficiency学派的另一个证明的工作。
针对这个方法本身,最大的问题还是推理的速度会大大降低,假设该方法要分10个chunk,每个chunk要推理10步,假设chunk可以并行计算,那么整体生成要比正常的推理慢10倍。训练GRPO投入的资源是有限的,但模型推理可能应用场景非常多,那么可能在运行一段时间之后,推理的成本就已经超过训练本身了。
针对这个命题本身,其实还有一些更有意思的思考。之前大家有一个推论,就是SFT Memorize,RL Generalize。但假设上述命题和RL只能提升Sampling Efficiency这两个命题同时成立,就有以下一些问题。如果RL并不能注入新知识,那么Generalize是怎么做到的?是base model本身的泛化性就很好?如果SFT质量高,是否SFT和RL效果是近似的,甚至SFT还更好?泛化性到底是LongCot引入的,还是RLVR本身带来的?平均300长度的CoT数据做SFT和平均长度600的CoT数据做SFT是否泛化性不同?