GPT:一句狠但真实的话
现在大部分人都已经把LLM等纳入了自己的工作流中,相信很多人在GPT-5.2的回复中都发现了类似的内容:“一句狠但真实的话”,甚至在一些社交媒体上这都成了GPT相关的一个梗,说出来很多人觉得搞笑。如果观察足够仔细,我们可以发现模型可能有自己的“口头禅”,但这到底是什么导致的呢?
先说结论:这背后可能是RL阶段的Reward Model更新导致的,RL阶段发生了Reward hacking,导致RL后的模型学习到了RM中的伪特征(spurious feature),也可以说RM学习到了一部分伪特征,而不是真正语义上的分别。例如,只要回复中带有“狠但真实的话”,RM就会倾向于打高分,而这个特质也在RL过程中被加给了模型。下面我们简述下背景,这个现象产生的原因,以及如何进行避免。
背景
2025年可以说是RL post-train爆发的一年,引爆的起点就是25年初来自于Deepseek发表的R1系列的工作,如何通过verifiable rewards ➕ GRPO算法,通过Scale RL训练过程,让模型具备了远超Base Model的智能。(这里我夹带一点私货,个人认为Thinking CoT的引入其实比RL的作用要大很多,无论是专项涨点还是泛化能力,加上CoT就已经强了太多,以至于后面verifiable RL经常是掉点的)
在R1系列中,Reward Model的角色被淡化了,取而代之的是直接用可验证结果来作为rewards,这个做法的好处是避免了模型产生Reward hacking,因为结果正确与否是客观的,实在的。但在模型的交付上,除了可验证结果的数据,还有很多Creative Writing的任务,因此Reward Model是一个绕不开的话题。但Reward Model在这一年里就好像是房间里的大象,RM相关的文献和verifiable RL算法的优化相比,数量上是少非常多的。因此我做了一个简单的调研,并结合自己的实践,把我的一些想法写出来,和大家讨论。
问题初发现
很多人做RM优化,甚至直接做DPO优化,首先在脑海中的想法就是,我是否能把一个牛逼模型的回复(例如GPT-5)直接当成好的,把我现在的模型直接当做差的,这样是否就能学好了?这是很多人包括我在内最开始的误区,答案肯定是不行的,从结果来看,这种学习无一例外都让最后的模型结果掉点了。
这是为什么呢?
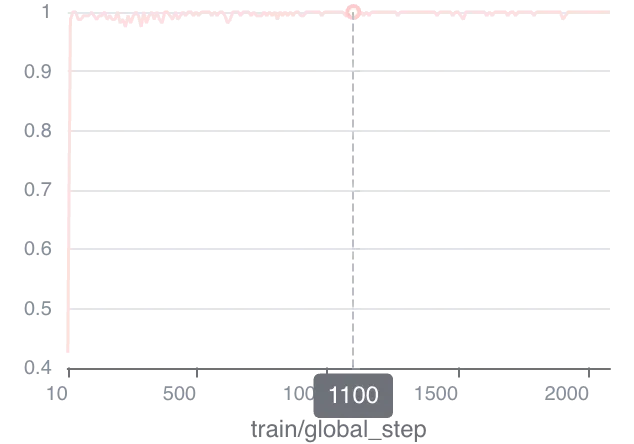
相信很多人都看过下面的训练曲线,以上做法在RM或者DPO一开始训练的几个Steps之后就迅速饱和,后续的Acc就一直在1左右,loss也基本上不下降了,即使做了数据去重也是没用的。这个肯定是训崩了。如果我们试图调整LR或者Batch_size等超参,避免过拟合等问题,你会发现这种方法也不行,所以问题肯定不是出现在训练过程中,而是数据本身出了问题。
从他人工作中找答案
一个学科蓬勃发展的好处就是可以站在巨人的肩膀上解决问题(坏处是创新变难了),通过大量进行Research,发现其实这个问题很早就有人开始解决了。
早在2024年的这篇文章(A Long Way to Go: Investigating Length Correlations in RLHF)中就提到了,PPO的RM可能只学习到了回复的长度,而不是真正语义上的好坏。作者做了几个实验
- 把Reward打出的分数和长度画出correlation,发现长度和Reward是有正相关关系的;
- 控制PPO训练中的输出长度,所有之前PPO训练带来的Gain都消失了;
- 直接在PPO训练中把RM替换成直接根据长度assign Reward,发现两个训练的效果非常接近(只提升长度也能涨点)
所以可以看到,这里RM的伪特征是长度;当然,GPT回答相比于你要优化的模型,也许伪特征不存在于长度这个维度,而是其他维度,比如tone,或者就是那句“狠但真实的话”。
在另一篇文章(Rectifying Shortcut Behaviors in Preference-based Reward Learning)里,也有人提到了类似的观点,即Reward学习过程中,长度、语气、隐式的固定模式,都是RM较容易学习到的伪特征,同样会造成训练的崩坏。
我的实践confirmation
我们在进行DPO训练时,其实观测到类似的曲线,其核心原因还是DPO和RM训练都share了相同的训练objective,因此两者训练的表现也呈现了类似的趋势。
与此同时,我们发现DPO的模型,经常会使SFT模型中的问题更加严重。例如,假设你的SFT模型有一定的Format问题,你把Format有问题的部分给到低分或者reject里面,好的格式放到chosen里面,训练完发现格式有问题的情况更多了;
PPO+RM的情况是,如果SFT中有5%的数据发现用了一定的语气,SFT后这种语气在inference时候出现的概率远高于训练集中的统计值(这种是已知的,数据不均衡会导致的问题);而这种情况在RL训练后,可能更甚,产生了模型能力下降的死亡螺旋。
他人的解法
解法其实已经呼之欲出了,既然问题的核心原因是,RM很容易学习到伪特征,我们就可以通过一些手段,根据语义内核来rank RM的训练数据,这个问题就可以解决了。
因此,总结下目前比较流行的方法
- 模型层
- 生成式Reward:通过生成式结果让模型给判断,例如LLM-as-a-Judge、Reasoning RM等;
- 训练层
- loss function优化:在loss function中加入正则项,用先验知识判断是否表层伪特征,是的话给予惩罚;
- RM Majority Voting:用多种、多个、多样Reward Model打分,去除单一模型的bias;
- 额外信息引入:在训练过程中,RM的loss后期会忽略Prompt的因素,因此加入Prompt插值到优化目标中,强行让模型考虑Prompt给response打分。
- 数据层
- 伪特征去除:在伪特征一致的情况下(长度统一、语气近似),给到不同的分数,让模型学习时放弃shortcut。
总结
RM作为RL中的重要一环,可以说RM训练效果直接导致了基于RM的RL是否能成功,其重要程度甚至比优化RL中的一些小trick要高得多;如果RL后的模型出现了效果下降且使用了RM,别犹豫,先去debug下RM的问题。
还存在的一些疑问
- 为什么DPO会导致格式崩坏,但是GRPO却能进行格式的修复?是因为GRPO的格式Reward更加直白?还是因为DPO其算法本身因为过度打压reject导致chosen同样下降的本身缺陷导致的?
- 在Unified Reinforcement and Imitation Learning for Vision-Language Models这篇文章中,作者的Imitation learning的思路是,用一个RM分类器区分Teacher和Student的回复,把这个RM分类器作为GRPO时候的Reward,训练效果得到了提升。但其RM分类器的训练也是快速饱和了;不确定这个文章里,到底是因为GRPO本身能一定程度上避免Reward hacking,还是因为作者同时引入了verifiable Reward + LLM as a judge,实际上这个RM起的作用不大呢?