解读下Qwen3.5
序言
不知道是不是去年Deepseek开启了中国AI届的传统,大公司几乎都赶在春节前Release了一波模型,这几天比较火的就是SeedDance 2.0和Qwen3.5的模型,现在的大模型赛道确实比较卷,要知道Qwen3.5是除夕当天发布的。虽然官方的Tech Report还没有发布,但是我们可以先通过Release出来的模型权重和inference代码,看下这个官方宣称的原生多模态智能体是个什么。
模型架构
首先Qwen3.5官方Release出来的是397B-A17B的MOE模型,MOE模型是一个Inference性价比很高的架构,这比较符合现在大模型的发展趋势:在OpenClaw相关的个人助理式应用发展出来以后,inference性价比在应用侧是一个关注度很高的指标;
其次,我研究了一下release出来模型的架构,即Qwen3_5MoeForConditionalGeneration。官方提到的原生多模态,并非是多模态模型的原生,即并没有进行Vision的tokenization,而是沿用了QwenVL的架构,即依然使用Vision Transformer编码图片,经过patchmerger对ViT结果进行下采样,最终投射到LLM的embedding空间上,不过注意这里和Qwen3VL有一些异同;
- 相同:都是采用了ViT + LLM的整体架构,视频采用了时间戳+Frames的处理方式;
- 不同:Qwen3.5抛弃了Qwen3VL中的Deepstack,可能这种方式带来的提升比较有限?
有什么Highlights?
总结来说,这次Qwen3.5最重要的,就是在未来各类Agent任务场景上的适配,真正做到泛化性和实用层面的第一,而不是为了刷一些Benchmark,下面我quote一段Qwen3.5在网页上的原话。
[!IMPORTANT]
相对于 Qwen3 系列模型,Qwen3.5 的 Post-training 性能提升主要来自于我们对各类 RL 任务和环境的全面扩展。我们更加强调 RL 环境的难度与可泛化性,而非针对特定指标或狭隘类别的 query 进行优化。下图展示了在通用 Agent 能力上,模型效果随 RL Environment scaling 带来的增益。整体性能由各模型在以下基准上的平均排名计算得出:BFCL-V4、VITA-Bench、DeepPlanning、Tool-Decathlon 和 MCP-Mark。更多任务的 scaling 效果将在我们即将发布的技术报告中详述。
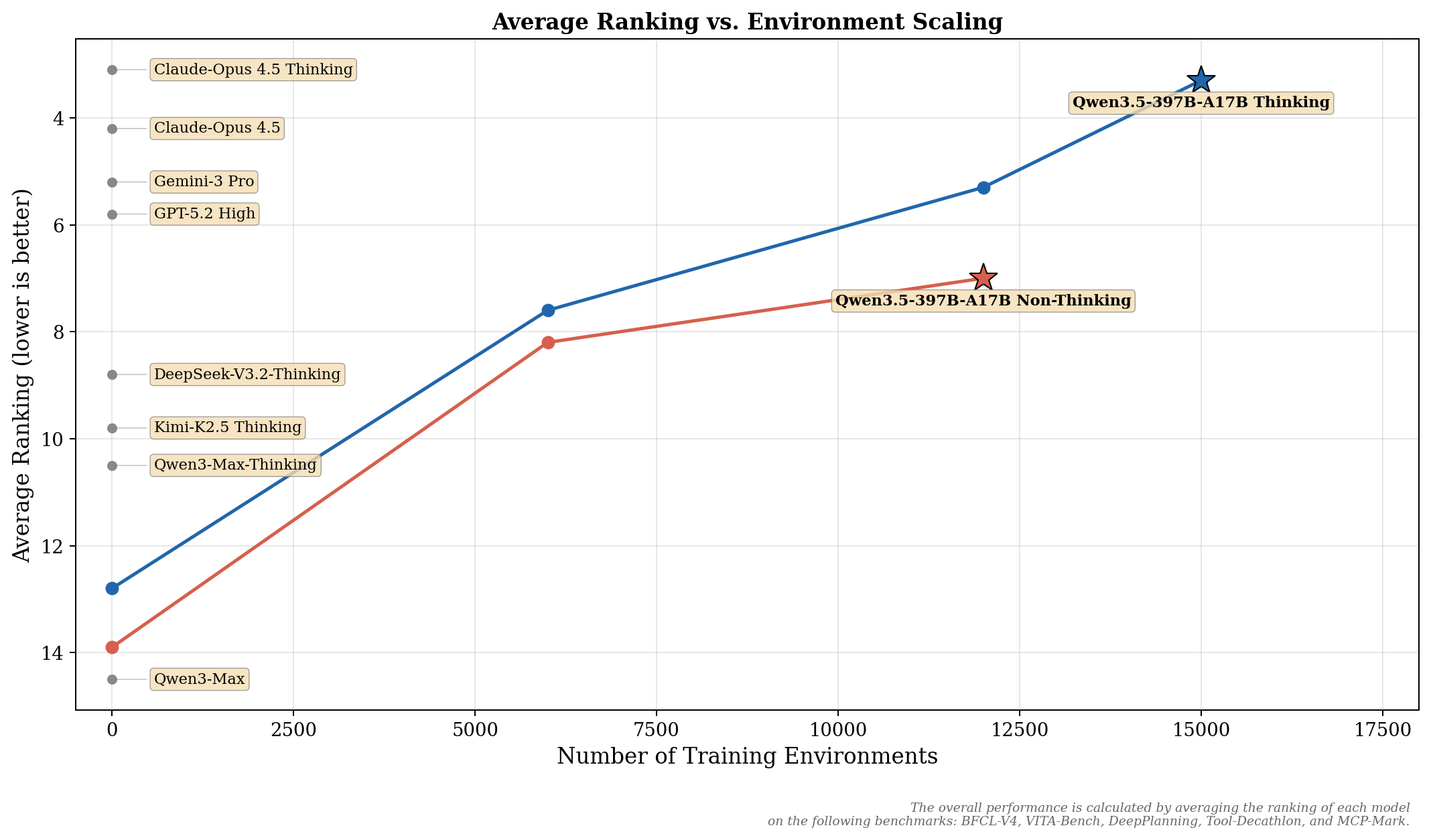
从Demo展示看Qwen的野心
Qwen重点展示了几个场景
- 仰望星空:Qwen官方使用Qwen3.5对Agent能力的支持,这个是各个大厂在26年正在大力发展的方向;
- 脚踏实地:
- 网页和coding开发;
- 第三方智能体的集成:OpenClaw的适配;
- 视觉智能体、视觉编程。
- 惊喜:自动驾驶场景的应用潜力。
以上几个都是Qwen官方放出来的Demo,可以看出其希望通过Qwen3.5这个模型来开启26年的Agent爆发元年。
总结
Qwen这波发布,赶在年前开启了Agent的元年,通过官方发布的一些Demo,看到了他们期望通过模型达成的最终结果。这里其实还有个小细节就是在基础设施这里的工作,内容虽然不多,但是从简短的一些文字中就感受到了巨大的Infra工作,全尺寸模型的训推一致性、训推解耦、Rollout路由回放、面向Agent工作流的训练框架搭建和长尾Rollout延迟处理,哪一个听上去都是巨大无比的工作量。
想到这里也十分感慨,使用现在的开源框架进行的Agentic的RL训练,虽然已经避免了很多Infra的工作,但实际上在真正开始之前,需要对训练和推理有非常深入的了解和研究,否则但凡存在个训推不一致的问题,都会造成效果上的下降或者不及预期。RL时代,真正考研Infra功底和训练资源利用率了,否则算法上的优化将无从谈起。