大家用AI一定要做好Fact Check
问题引入
最近听了姚顺宇的访谈播客,现在已经有非常多的总结,我就不赘述了,但关于其中他提到的,做模型的人要多思考,多check,方法本身是否能在不同参数量,不同模型架构,更好的数据上依然生效,是一个需要反复验证和研究的过程,这一点我深感其然。
有些工作看着很基础,也不一定是当下研究的热点,但实际上在应用过程中却异常重要。就拿我最近使用某AI软件的过程来说吧,我本来以为在如今的模型参数量和规模的情况下,模型应该会很少出现幻觉的问题了,但实际上这个问题比我想象的要严重很多。以我最近的工作为例,我最近在看到了不同的GRPO-like算法都存在不同程度的长度偏置,于是我让某AI帮我总结了一下关于这方面的研究。
于是,我得到了下面的回复,在我想要继续查看,这篇OpenAI的内部研究报告的时候,我搜遍了全网,没有通过名字找到这篇文章,于是我又把arXiv的编号搜索了一番,最终得到了一篇既不是来自于OpenAI,也和长度偏置没有任何关系的文章。所以幻觉本身还是一个比较严重,需要被正确看待并解决的问题。

工作介绍
于是我看到了千问团队最近的这篇文章,MARCH: Multi-Agent Reinforced Self-Check for LLM Hallucination,专门解决涉及到搜索召回过程中存在的幻觉问题。幻觉是一个老生常谈的问题,也是模型在实际应用里面要被解决的基础问题,对模型和平台的可信度影响非常大,一旦出现一次幻觉问题,可能用户就会完全脱离这个平台。因为用户问AI,代表其本身对问题的理解程度可能不高,很容易信任AI的回复,因此就会出现You don’t know what you don’t know这个现象,会产生生理性恐惧。那么上面这篇论文提出了什么机制来解决这个问题呢?可以参考下面这个图
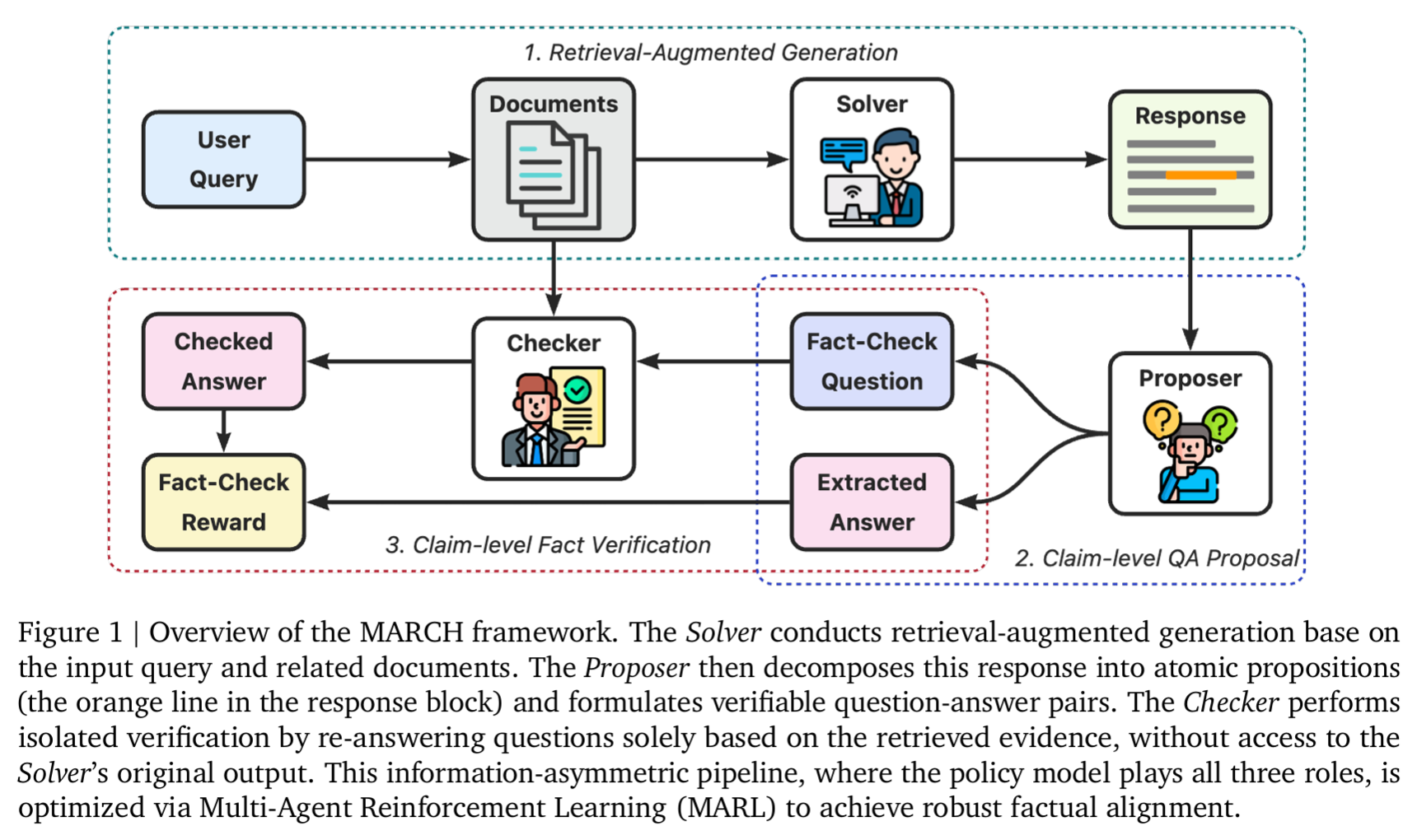
简单来说,就是在一个需要检查真实信息的环境中,设定了三个角色,也是三个Agent,每个Agent不能既当裁判员,又当运动员,而是分属于Solver(RAG Model),Proposer(事实检查Question pairs)和Checker(基于每个问题进行回复)。
所以我们基本关心两个问题
- 这三个角色怎么设计Reward?
- 具体在RL update的时候怎么训练?
Reward设计
-
Zero-tolerance Reward:在Proposer给定的claim里面,有一条对不上,整条trajectory都要被惩罚。
-
只有0和-1这两个Reward,对的是0,错了是-1;
RL Update
本体使用了PPO算法,MARCH 把两类 trajectory 都放进 PPO batch:
1. Solver trajectory y
2. Checker audit trajectory λ
每条原始样本 (x, D) 会产生:
y_i = Solver response
λ_i = Checker audit response
R_i = ZTR reward
然后它把 y_i 和 λ_i 都加入 unified trajectory batch TB,并且两者共享同一个 terminal reward R_i。Algorithm 1 里就是这么写的:先生成 y,再 Proposer 拆 QA,再 Checker 生成 λ,再算 ZTR,最后把 y_i 和 λ_i 都加入 unified batch trajectory set。
实验结果
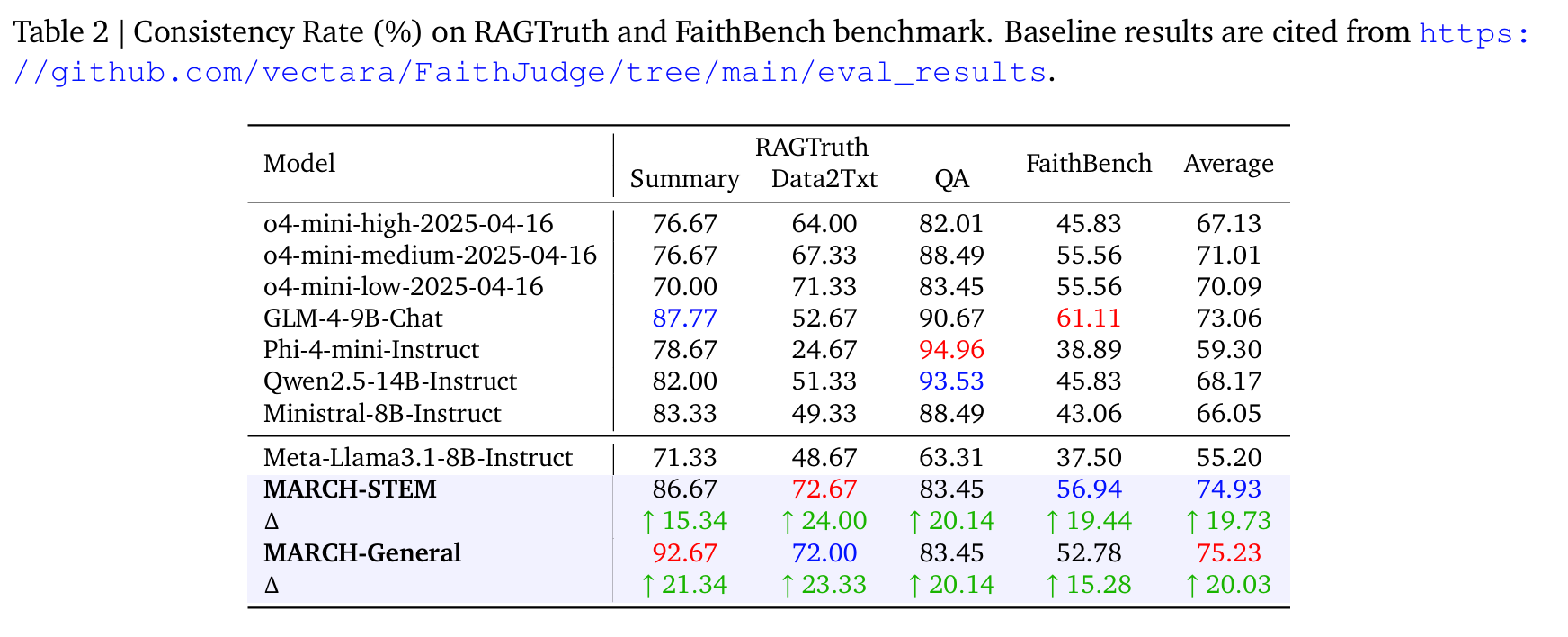
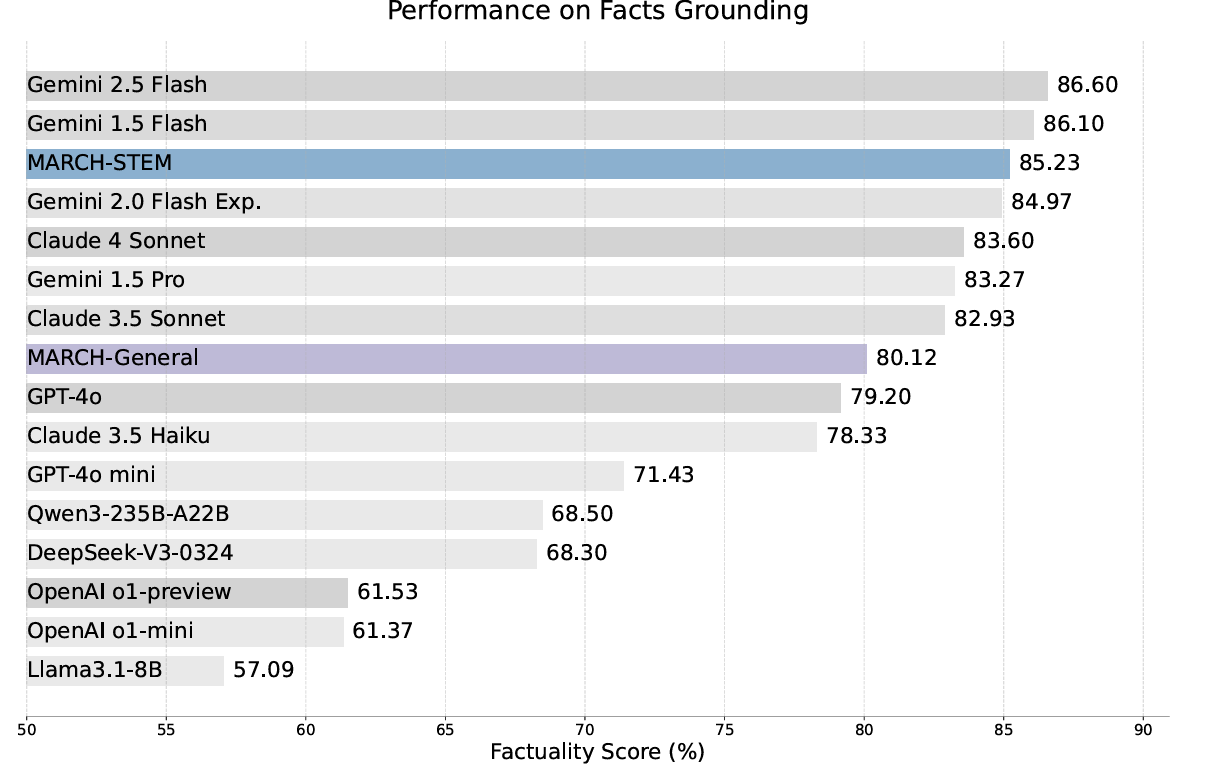
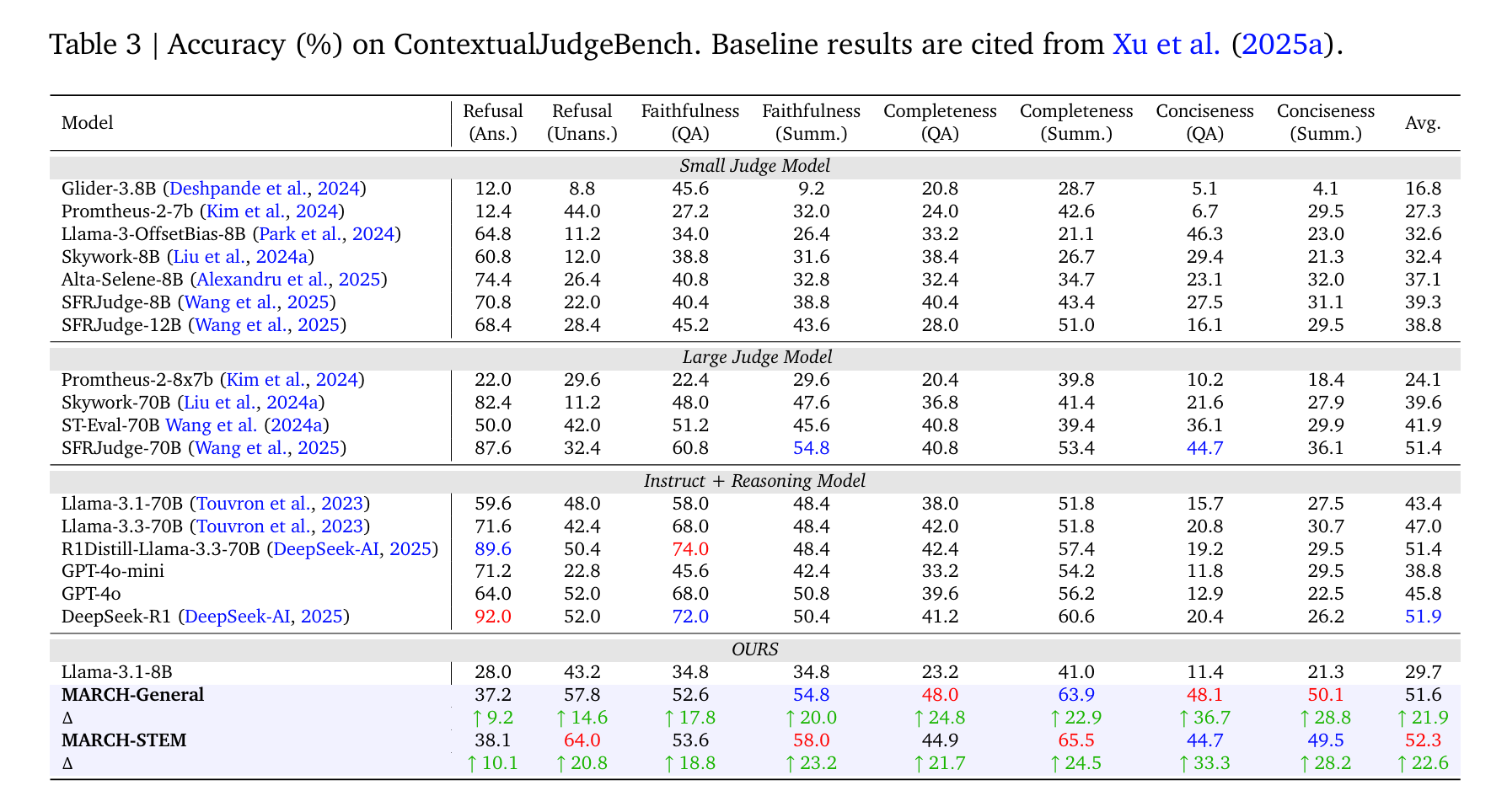
可以看到,实验整体的效果还是不错的
 |
 |
 |
除了今天提到的这篇,千问C端应用团队四篇论文今年有四篇论文都入选ICML、ACL,覆盖推理加速、幻觉治理、架构优化与结构化推理四个方向。其中一篇ECHO框架的中了ICML 2026的SpotLight,还是很有含金量的,毕竟是前2.2%了,今天投稿量还翻倍了
整体看下来,不愧是做C端应用的,论文里的框架都很实际,大家感兴趣可以去看看。
总结
基础的工作往往需要更持续的投入和更多方法的总结,尤其是现在Agent方案逐渐被大家接受,模型怎么能在这个过程中避免Tool Use,使用Tool Use的结果,整个过程完整任务,没有幻觉,也会持续被大家讨论。千问这篇文章工作算是用Agent方案进行的一个新的尝试,还是很不错的。