原创:GRPO Robust Reward Nomalization
问题引入
在常规的GRPO训练过程中,我们使用到的往往是Verifiable的反馈,其优点是一致性高,没有偏差,信号稳定。但是在实际应用场景中,一般会出现以下两个挑战
- 结果没有Golden Answer:模型没有明确的Verifiable Reward Signal,或Signal本身存在一定偏差、波动,导致信号只在统计意义上有效,而非每条都是Ground Truth;
- 只能采用Reward Model:第一个挑战会带来的问题就是我们在实际使用中,往往需要自行训练一个Reward Model,作为Verifiable Reward Signal的替代;实际上,从25年开始,大家都在尝试融合Reward Model和Verifiable Reward Signal,来统一后训练。
- VLM Reward Concentration:如果我们使用Bredley-Terry方法训练一个Scalar RM,则在我们的实际观察中,在视频理解场景,Vision的Context较长情况下,回复占用的篇幅往往远低于Prompt的篇幅,这会导致一组GRPO的Rollouts,Reward Model所打出来的分数,聚集(concentrate)在一个比较小的区间。
所以,我们实际观测到挑战如下所述,
Video Scalar RM GRPO核心挑战:Reward Shaping
- Reward concentration & Outlier:GRPO开源多在Rule-based Reward上训练,分数天然Normalize在0-1区间,没有Outlier,但是Scalar RM存在Score concentrate和Outlier问题;
- Advantage Spike:同策略视频组内std过小,导致Advantage计算波动巨大。
| Reward concentration & Outlier | Advantage Spike |
|---|---|
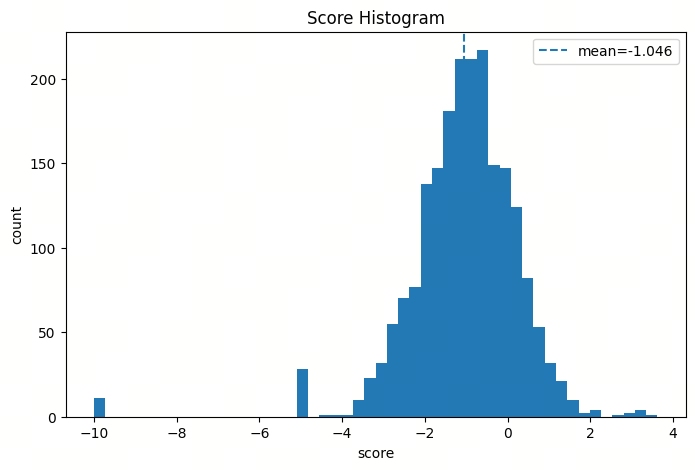 当前RM因为不设置上下界,且无Normalization,所以存在Score的Outlier,并且分布比较集中 |
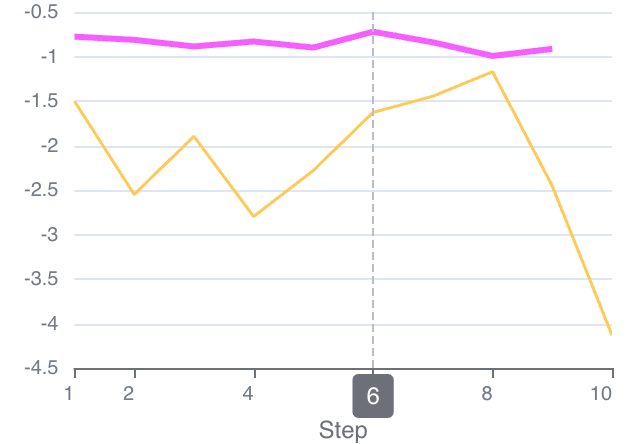 黄色线:w/o Robust Reward Norm,优势计算波动大,更新不稳定 红色线:w/ Robust Reward Norm, 优势计算稳定 |
核心优化:Robust Reward Nomalization
属于GRPO-like算法中,Reward Shaping方向优化
-9085715.)
实验及结论
- Reward Shaping: Clamping outlier和RM Score nomalization两个操作,训练提升较大
- Training Reward -1.04 -> -0.77
- Eval Reward:-0.61 -> -0.21
- 为什么当前操作work?
- Robust Score Normalization避免了Refresh视频的差别过小,而导致的Advantage尖锐噪声的问题,从而稳定了训练;
- Clamping outlier防止了部分Outlier的Advantage过大,从而过分boost或者打压低分sample,导致训练崩溃。
- 本质:组内优势优化,和DAPO的dynamic sampling,curriculum learning的思路一致,都是让每一个prompt Group产生有效的gradient update
PREVIOUSAI算法