Early Termination Collapse in Agentic RL - A Simple Rollout Continuation Strategy Improves Search-R1 to 70% EM
Background
With the rapid rise of agent frameworks such as OpenClaw in early 2026, Agentic RL training has become an increasingly important research direction. However, compared to standard RLHF or single-turn reasoning tasks, agentic training introduces several unique optimization challenges.
In particular, we found the following issues especially important:
Long-Horizon Trajectories
Agent trajectories are substantially longer than conventional post-training sequences. A single rollout may contain multiple tool calls, external environment interactions, retrieval steps, and iterative reasoning turns.
This significantly increases:
- trajectory variance,
- delayed credit assignment difficulty,
- and optimization instability.
Multi-Turn Interaction Dynamics
Unlike fixed-format instruction tuning, agent training involves dynamically evolving conversational states.
Each rollout may contain:
- different numbers of tool calls,
- varying observation lengths,
- branching execution paths,
- and non-stationary dialogue structures.
This makes trajectory optimization substantially harder than standard next-token prediction.
Severe Off-Policy Staleness
We hypothesize that off-policy staleness becomes significantly more severe in long-horizon agent trajectories.
In standard RLHF, a small policy drift usually affects only local token distributions. However, in agentic environments, a single divergent tool call may invalidate the entire downstream trajectory.
As a result:
- rollout reuse becomes fragile,
- token-level gradients become increasingly stale,
- and optimization noise accumulates rapidly across turns.
In practice, we found this issue much more severe than in conventional RLHF settings.
To study these problems in a controlled environment, we reproduced Search-R1.
Search-R1 provides several advantages for agentic RL research:
- fully open-sourced training pipeline,
- reproducible offline retrieval environment,
- stable search database without real-time web dependency.
This allows us to analyze agent training dynamics without the instability introduced by live internet retrieval systems.
Unless otherwise specified, all experiments use:
- Base Model: Qwen2.5-7B-Instruct / Qwen3-8B-NoThinking
- RL Algorithm: GRPO
- Reward: Exact Match (EM)
- Train Batch Size: 128
- Rollout Group Size: 8
Initial Observation
Our initial goal was not to improve Search-R1 performance directly.
Instead, we introduced finer-grained rollout logging to investigate whether long-horizon agent training exhibits optimization behaviors fundamentally different from standard RLHF.
Surprisingly, we observed several interesting phenomena.
Qwen2.5-7B Consistently Outperformed Qwen3-8B-NoThinking
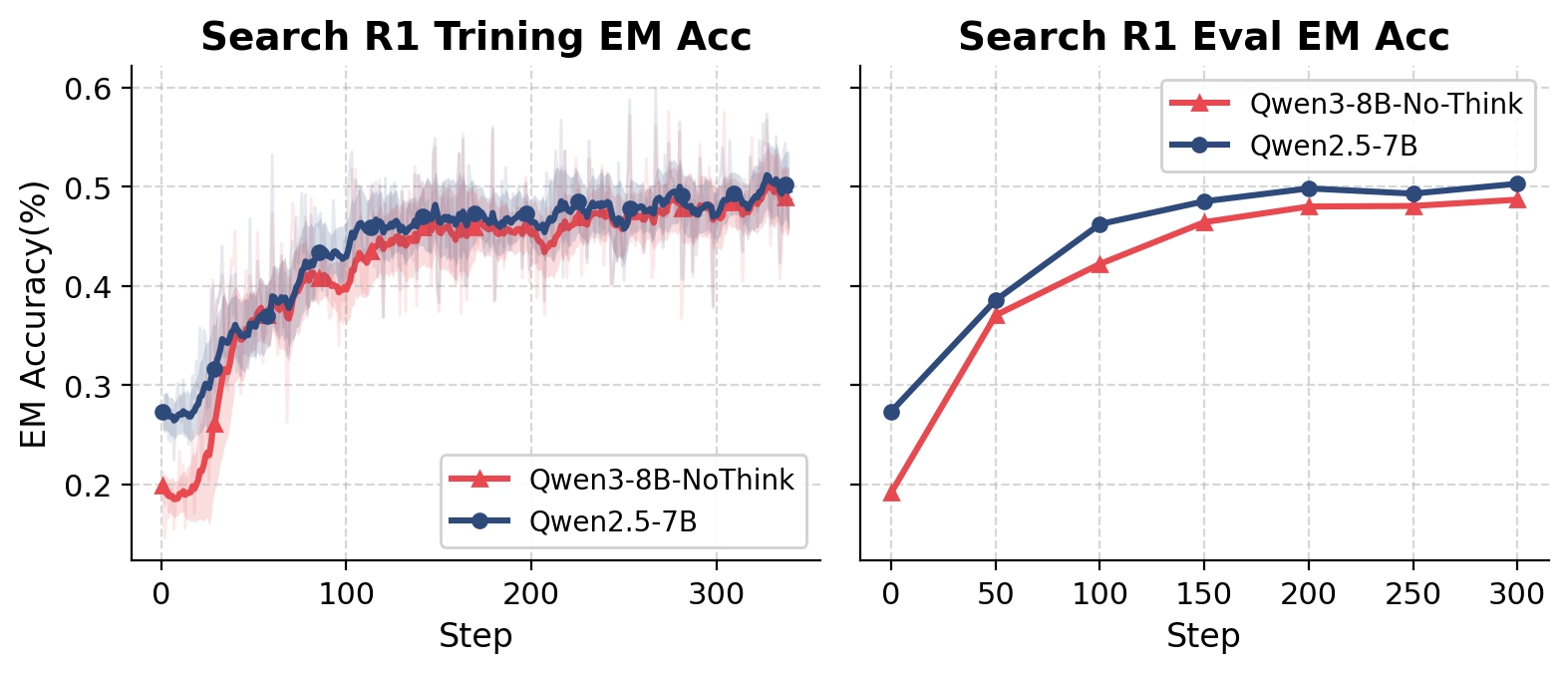
Search R1 train and eval EM Acc curve. Qwen2.5-7B’s EM Acc is generally higher than that of Qwen3-8B.
Although Qwen3-8B-NoThinking should theoretically possess stronger base capabilities, its EM performance remained consistently below Qwen2.5-7B throughout training.
This result was initially unexpected.
To better understand the discrepancy, we further analyzed rollout statistics.
Early Termination Collapse
The key difference was not reasoning quality itself.
Instead, the major discrepancy emerged from search behavior.
Although the Search-R1 prompt explicitly states:
“You can search as many times as you want.”
Qwen3-8B-NoThinking consistently avoided iterative search behavior.
Instead, it rapidly converged toward a policy of:
- performing minimal retrieval,
- answering immediately,
- and terminating the trajectory early.
In contrast, Qwen2.5-7B naturally performed substantially deeper search trajectories with multiple iterative tool calls.
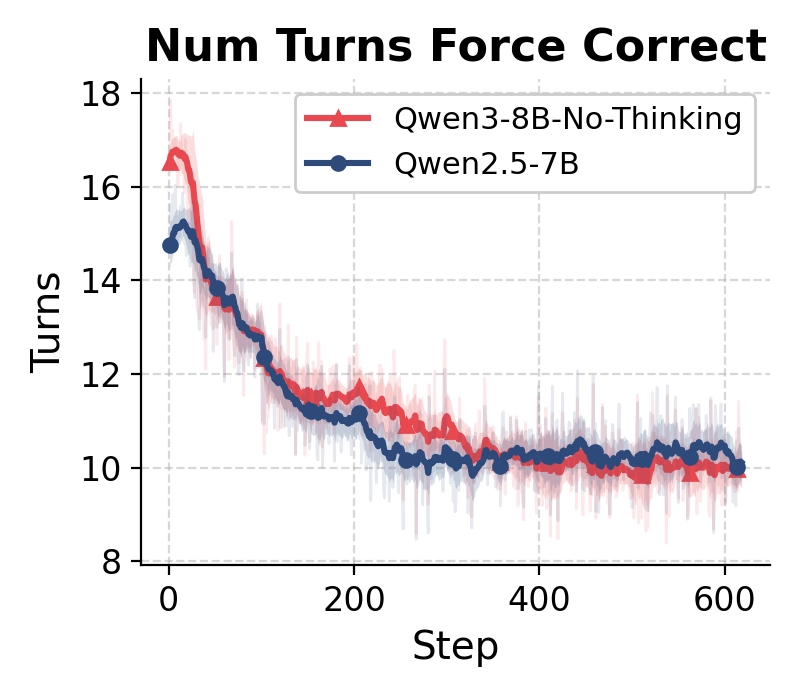
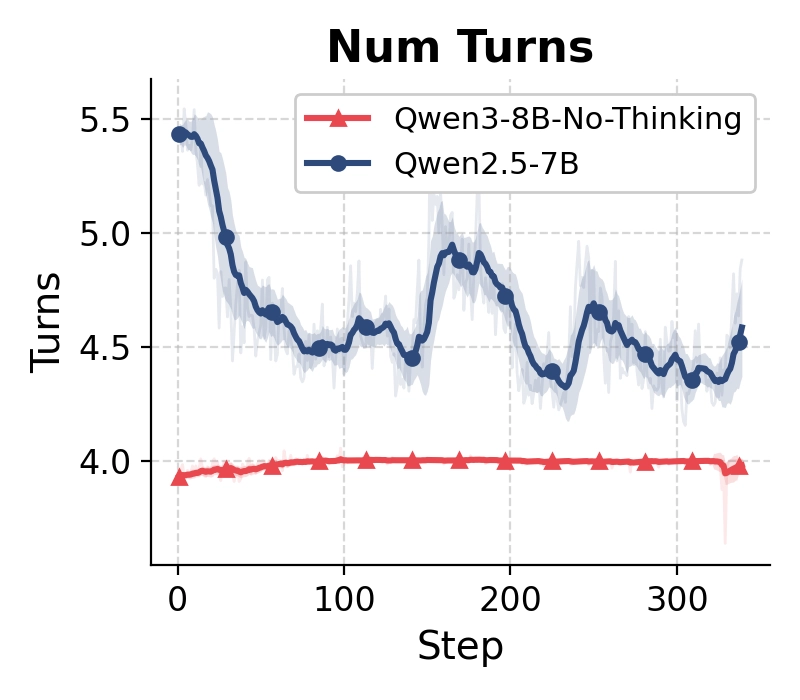 Qwen2.5-7B tends to follow the instruction and search multiple times. However, Qwen3-8B-No-Thinking fails to do so.
Qwen2.5-7B tends to follow the instruction and search multiple times. However, Qwen3-8B-No-Thinking fails to do so.
We refer to this phenomenon as:
Early Termination Collapse (ETC)
Formally, ETC describes a policy failure mode where:
- the model prematurely terminates interaction trajectories,
- despite insufficient external evidence,
- because shorter trajectories become implicitly favored during RL optimization.
Why Does Early Termination Collapse Happen?
We hypothesize that ETC emerges from the interaction between:
- aligned model training priors,
- sparse terminal rewards,
- trajectory variance growth,
- and implicit horizon minimization during policy optimization.
In GRPO-style optimization, longer trajectories are inherently more difficult to optimize because they introduce:
- larger variance,
- delayed reward propagation,
- higher rollout instability,
- and more opportunities for off-policy divergence.
As a result, the policy gradually discovers a low-cost local optimum:
answer early instead of searching deeply.
Importantly, search depth itself is not explicitly supervised.
Instead, it emerges implicitly from the optimization dynamics between:
- policy prior,
- reward sparsity,
- rollout termination behavior,
- and trajectory variance.
This explains why stronger base models do not necessarily produce deeper search behavior under agentic RL training.
Rollout Analysis
When visualizing actual rollout trajectories, the difference becomes highly apparent.
Qwen3-8B-NoThinking
Typical behavior:
- perform one retrieval,
- immediately attempt an answer,
- terminate trajectory.
The model rarely performs iterative evidence gathering.
Qwen2.5-7B
In contrast, Qwen2.5-7B frequently exhibits:
- multi-step retrieval,
- iterative refinement,
- repeated search attempts,
- and substantially deeper interaction horizons.
This deeper search behavior correlates strongly with higher final EM accuracy.
Method: Reflection-Guided Rollout Continuation
Based on the above observation, we explored a simple question:
Can we prevent the model from prematurely terminating trajectories?
Instead of allowing the rollout to terminate immediately after answer generation, we introduce a lightweight continuation mechanism.
Specifically:
- the environment checks answer correctness,
- incorrect answers trigger additional search turns,
- rollout terminates only when:
- the answer becomes correct,
- or maximum turn budget is reached.
In our experiments, the maximum number of turns is set to 10.
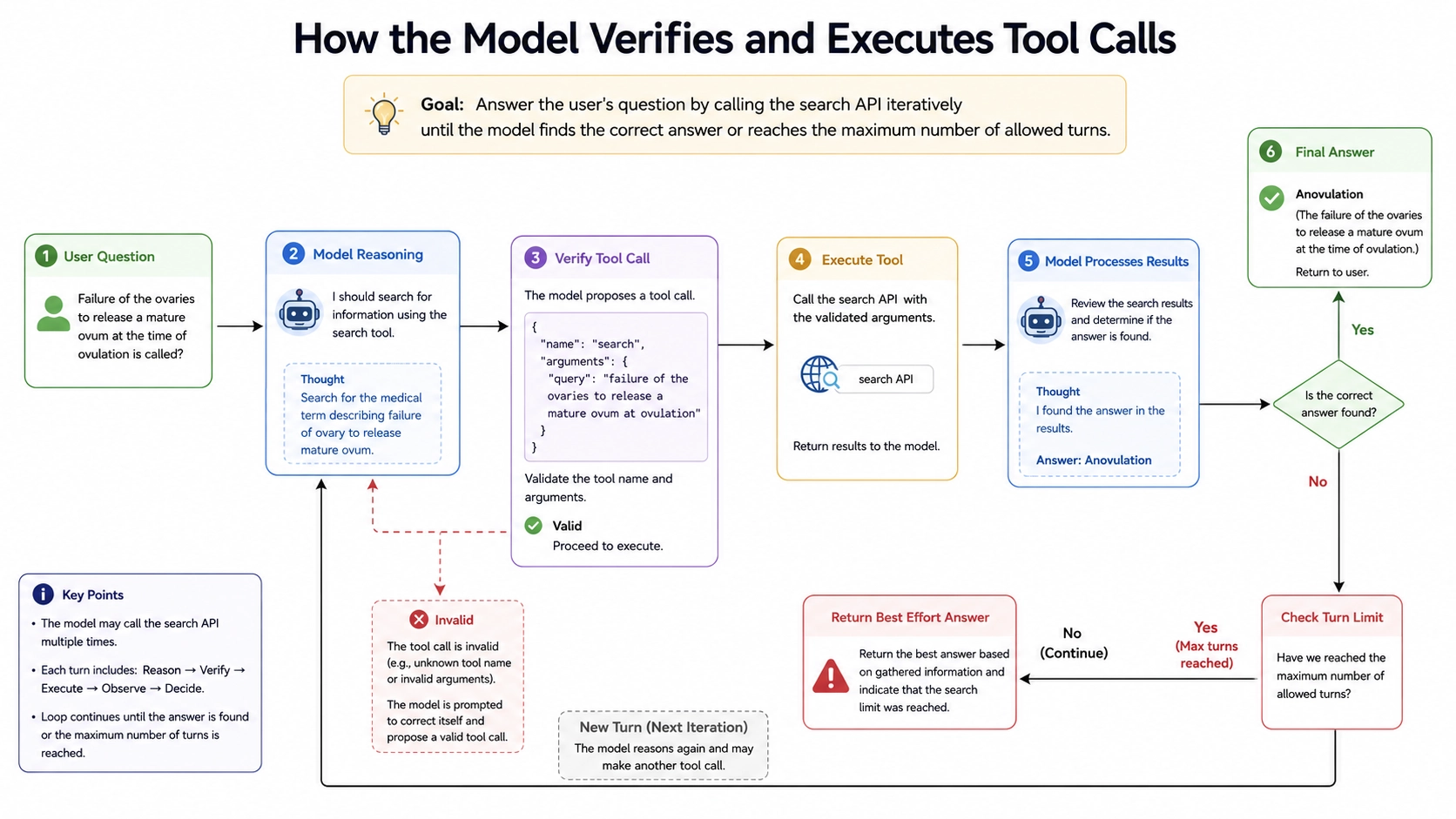
Importantly, this approach does not require:
- reward model redesign,
- context compression,
- additional supervised datasets,
- or architectural modifications.
Instead, it directly reshapes the rollout distribution toward deeper evidence collection behaviors.
We refer to this mechanism as: Reflection-Guided Rollout Continuation (RGC)
Results
The effect is surprisingly large.
By introducing only lightweight continuation reminders at appropriate stages, the model rapidly learns:
- deeper search behavior,
- iterative verification,
- and more persistent evidence collection.
Most importantly, the model begins to reflect on whether its current knowledge is actually sufficient before terminating the trajectory.
With only 300 training steps, the model reaches: 70%+ EM Accuracy
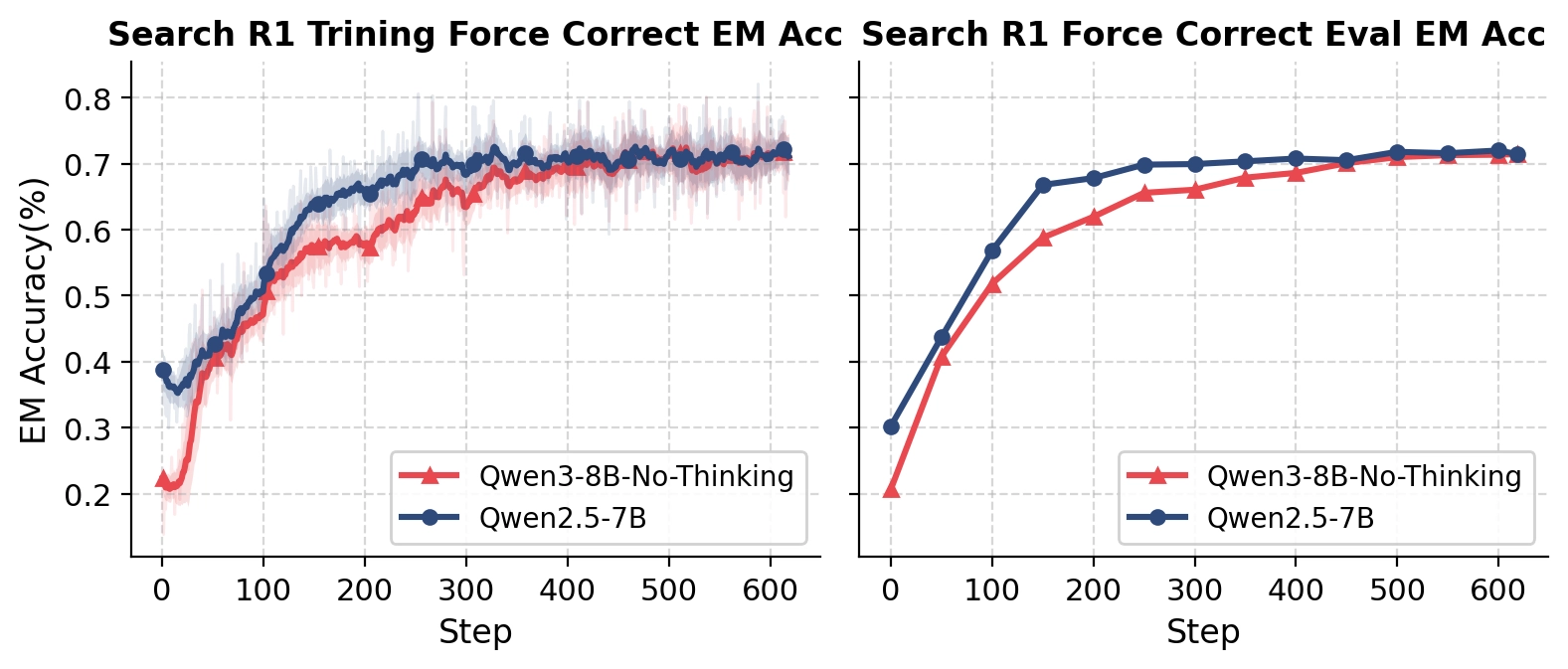
without using:
- context compression,
- advanced memory systems,
- retrieval distillation,
- or specialized agent architectures.
Discussion
Our experiments suggest that:
Premature answering is one of the core failure modes in agentic RL.
More importantly, search depth itself appears to be an emergent optimization behavior rather than an explicitly supervised capability.
This has several implications:
Stronger Base Models May Still Collapse
Even stronger instruction models may converge toward shallow interaction policies under sparse-reward RL optimization.
Long-Horizon RL Requires Explicit Trajectory Stabilization
Without mechanisms that encourage sustained exploration, policy optimization naturally favors shorter trajectories.
Agentic RL Introduces Unique Optimization Dynamics
In multi-turn environments, a single tool-call divergence may invalidate all downstream token updates.
This makes off-policy staleness substantially more severe than in conventional RLHF.
Conclusion
We reproduced Search-R1 in a fully controlled offline environment and observed a distinct agentic RL failure mode:
Early Termination Collapse.
Under GRPO optimization, models tend to prematurely terminate trajectories instead of performing iterative evidence gathering.
To mitigate this issue, we introduced a lightweight continuation strategy:
Reflection-Guided Rollout Continuation.
Despite its simplicity, this method improves Search-R1 to over 70% EM within only 300 training steps, without requiring additional architectural complexity.
More importantly, our experiments suggest that many behaviors in agentic systems — including search depth itself — emerge directly from RL optimization dynamics.
We believe understanding these dynamics will become increasingly important for future long-horizon agent training systems.
Final Remarks
It is important to note that this work does not yet address the full set of optimization challenges unique to long-horizon agentic RL.
In this article, we primarily focus on identifying and mitigating one specific failure mode:
Early Termination Collapse (ETC)
While ETC significantly affects Search-R1 performance, we do not believe it fully explains the instability observed in long-horizon agent training.
In our subsequent experiments, we observed additional phenomena that appear to be unique to long-horizon agent trajectories, including various forms of:
Behavior Collapse
These behaviors are substantially more complex than premature answering alone, and seem to emerge from the interaction between:
- extended trajectory horizons,
- multi-turn policy drift,
- off-policy branching instability,
- and long-range credit assignment failures.
We are currently conducting deeper investigations into these dynamics and will present our findings in a follow-up article.
Appendix
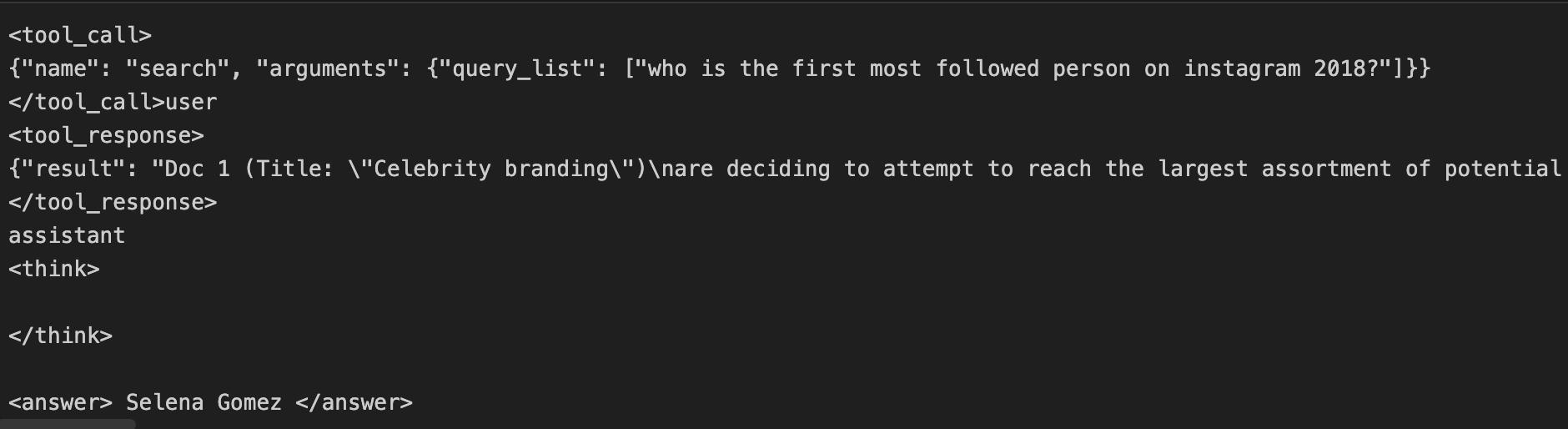 Qwen3 response: one tool call only and respond
Qwen3 response: one tool call only and respond
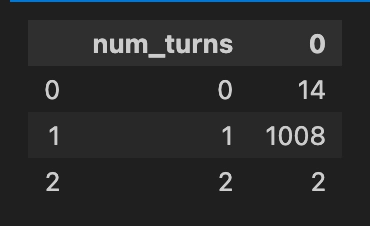 Qwen3-8B-No-Thinking dominantly search once and answer
Qwen3-8B-No-Thinking dominantly search once and answer