A Closer Look into Behavior Collapse in Agentic RL
In the previous article, I argued that Agentic RL should be fundamentally different from traditional RLVR. The argument itself was not particularly controversial. In standard RLVR, the model generates a response, receives a reward, and the trajectory ends. Even though policy updates change the distribution of future responses, the environment itself remains fixed.
Agentic RL is different in a subtle but important way. The model is no longer generating a single response. It is making decisions that affect what information it will see in the future. Whether the model decides to search, what query it chooses, whether it reads another document chunk, or whether it decides to terminate early all influence the observations that become available later in the trajectory.
This creates a feedback loop that does not exist in single-turn RLVR. A small policy update can alter future observations, which in turn changes future actions, making the resulting trajectory look very different from the one that generated the gradient in the first place.
My intuition was that this should make Agentic RL much more vulnerable to off-policy staleness than conventional RLVR. The longer the trajectory becomes, the larger the mismatch between the rollout policy and the current policy should be.
At least that was the theory.
The reason I am writing this article is that after reproducing Search-R1 and instrumenting a large number of trajectory-level metrics, I found something that was both more interesting and more confusing than what I originally expected.
I was looking for evidence of off-policy staleness.
What I ended up finding was something that looked much more like behavioral phase transitions.
The Setup
To study the problem in a reasonably controlled environment, we reproduced Search-R1. Compared to production-grade research agents, Search-R1 is intentionally simple, but that simplicity is precisely what makes it useful. The entire training pipeline is open-sourced, the retrieval environment is reproducible, and the search database remains fixed throughout training. This removes many of the confounding factors introduced by live web search and allows us to focus on the training dynamics themselves.
Unless otherwise specified, all experiments use Qwen2.5-7B-Instruct or Qwen3-8B-NoThinking as the base model, GRPO as the RL algorithm, Exact Match as the reward, a training batch size of 128, and a rollout group size of 8.
The action space is also relatively small. For most trajectories, the model is effectively choosing between answering directly and performing a search. This simplicity turns out to be helpful because behavioral changes become easier to identify.
Initially, I was not even looking for behavior changes.
The first thing that caught my attention was a completely different metric.
A Strange Change in the Number of Turns
One observation that repeatedly appeared during training was that the average number of turns gradually decreased.
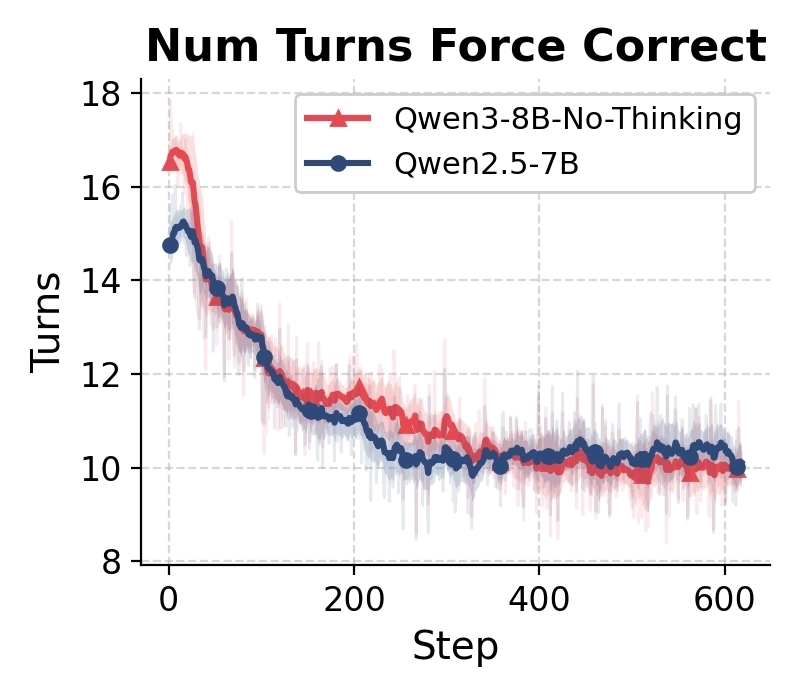
The num of turns decrease gradually as training continues.
At first glance, this looked perfectly reasonable. If the model becomes better at finding useful information, fewer search calls should be needed. A stronger model should often reach the correct answer with fewer interactions. Since both training accuracy and evaluation accuracy were improving at the same time, there seemed to be little reason to investigate further.
The interesting part only emerged after inspecting rollout traces.
What initially looked like improved efficiency was actually a change in strategy.
Around step 300, the model began answering questions directly before issuing a search call. The change happened surprisingly quickly. For hundreds of optimization steps, the dominant pattern looked roughly like:
Question → Search → Answer
Then within a relatively short period of training, many trajectories started looking like:
Question → Guess → Search → Answer
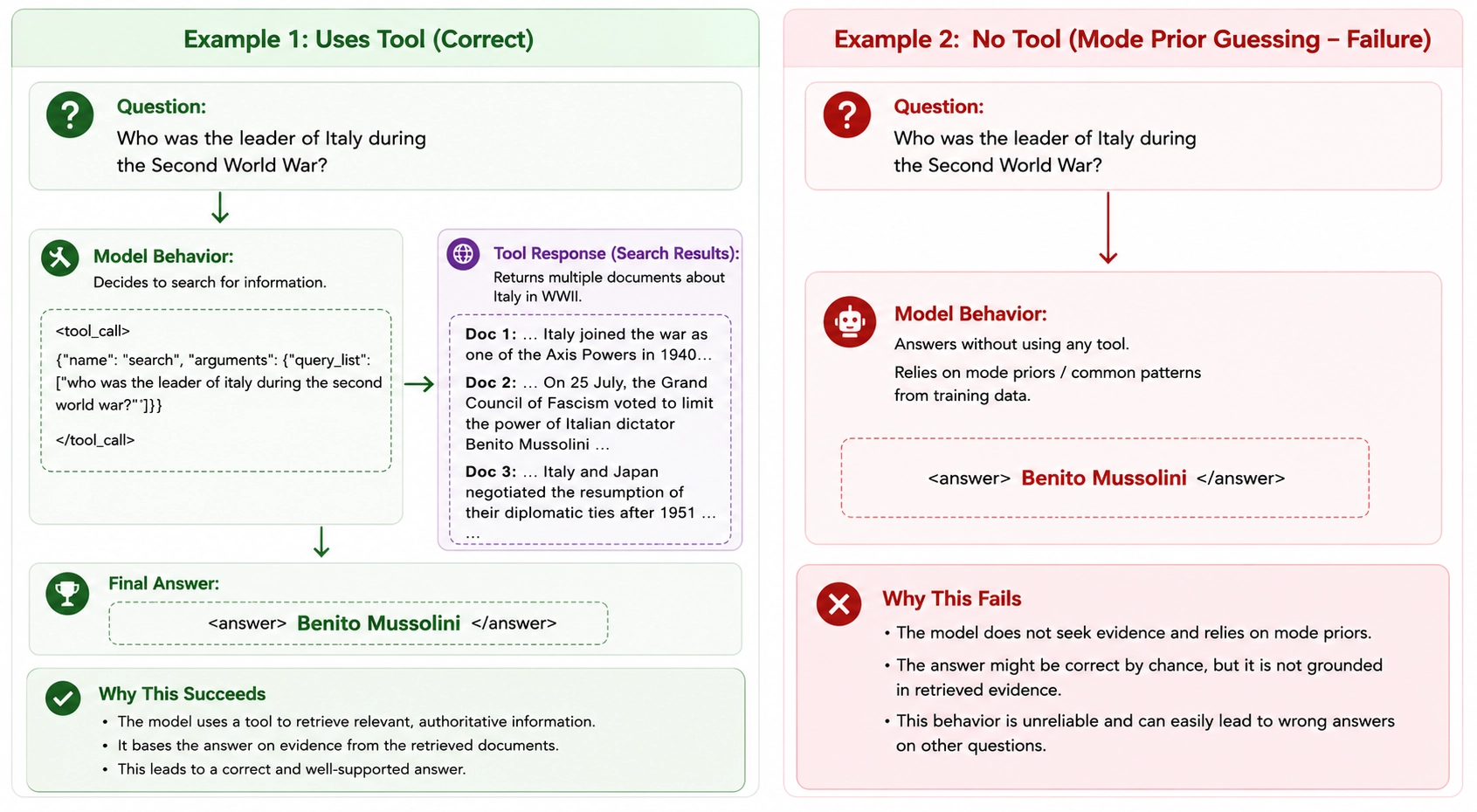
The behavior collapse observed during training. The model will try to answer with its own prior knowledge before consulting the external evidence.
The search tool was still being used. The model had not forgotten how to search. Instead, it appeared to be increasingly willing to trust its own prior knowledge before consulting external evidence.
The transition was large enough that it became visible in aggregate statistics. If we track the proportion of trajectories that contain zero search turns, the ratio increases sharply around the same time.
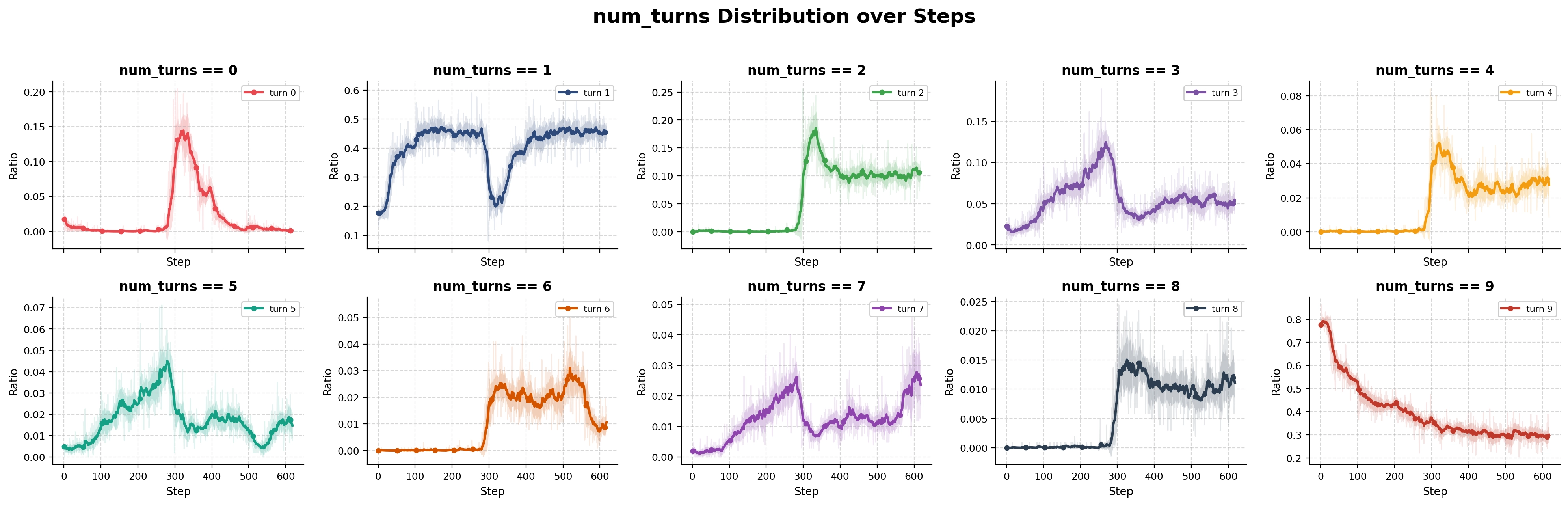
At this point, the most natural explanation seemed straightforward. Perhaps the model was becoming stronger and discovering that many questions could be answered directly without searching.
Unfortunately, the data did not support that interpretation.
Comparing checkpoints immediately before and after the transition revealed a significant drop in four-turn accuracy. The guess-first behavior was not an improvement. In fact, it performed noticeably worse than the original search-first strategy.
| acc_num_turn/step | step 278(Before entropy spike) | Behavior(Search Ratio) | step 297(After entropy spike) | Behavior(Search Ratio) |
|---|---|---|---|---|
| 0 | 0.0% | 98.43% | 14.55% | 32.32% |
| 1 | 47.07% | 0.78% | 28.22% | 48.63% |
| 2 | 47.75% | 52.14% | 37.98% | 20.01% |
| 3 | 57.03% | 1.95% | 41.69% | 41.79% |
Comparing step 278 and step 297(the closest two steps when the spike happens). The accuracy of 4 turns is 57.03% before collapse v.s. 41.69% after collapse.
From a user perspective, this is not particularly surprising. If the model incorrectly answers a question before deciding to search, the interaction is generally worse than simply retrieving evidence first.
What puzzled me was not the accuracy drop itself. What puzzled me was what happened next. The training run did not collapse. The evaluation curve did not collapse. After some fluctuation, accuracy recovered and continued improving. Even more interestingly, the search-first behavior gradually returned. The model appeared to discover a worse strategy, spend some time exploring it, and then move away from it.
This was very different from the failure mode I originally expected when thinking about multi-turn off-policy staleness.
Entropy Was the First Symptom
After noticing the rollout transition, I started looking for signals that could explain what happened.
One hypothesis from the previous article was that tool-generated observations introduce significantly higher uncertainty than standard conversational turns. Since external search results are not generated by the model itself, the distribution of future continuations should be much less predictable. To test this idea, I logged the entropy of the first few generated tokens after every turn. The resulting plots immediately showed something unusual.
Around the same time that the rollout behavior changed, the entropy of early tokens spiked dramatically. More interestingly, the pattern was not uniform across turns. When the entropy was broken down by turn index, some turns exhibited abrupt increases while others remained relatively stable.
Initially, I thought this might be evidence supporting the original hypothesis about tool-induced uncertainty. However, after aligning the entropy curves with rollout traces, a different explanation emerged.
Before the behavioral transition, many of those turns corresponded to tool outputs followed by relatively deterministic responses. After the transition, those same positions increasingly contained answers generated directly from model priors. The model was no longer conditioned on retrieved evidence and therefore had to rely on its own uncertain beliefs.
In retrospect, the entropy spike was not the cause of the behavior change. It was a consequence of it. The model started behaving differently, and the entropy reflected that change.
This distinction sounds subtle, but it turned out to matter. If entropy is merely reacting to behavior changes rather than predicting them, then it is not particularly useful for understanding why the transition occurred in the first place.
That brought me back to the original question. If this behavior change is real, what actually drives it?
Looking for Evidence of Policy Drift
At this point, I returned to the hypothesis that motivated the entire investigation. If multi-turn trajectories are becoming increasingly stale during training, then some measure of policy drift should become visible around the same time as the behavioral transition. The most obvious candidate was importance sampling.
PPO-style algorithms rely heavily on importance sampling corrections, and one might expect large behavioral changes to coincide with large importance weights. We therefore logged clip fraction and several related statistics throughout training. The results were somewhat surprising.
Clip fraction did increase before the behavioral transition, suggesting that token-level importance sampling corrections were becoming more active. However, the increase was not nearly as dramatic as the change observed in rollout behavior. The strongest signal came from a different metric.
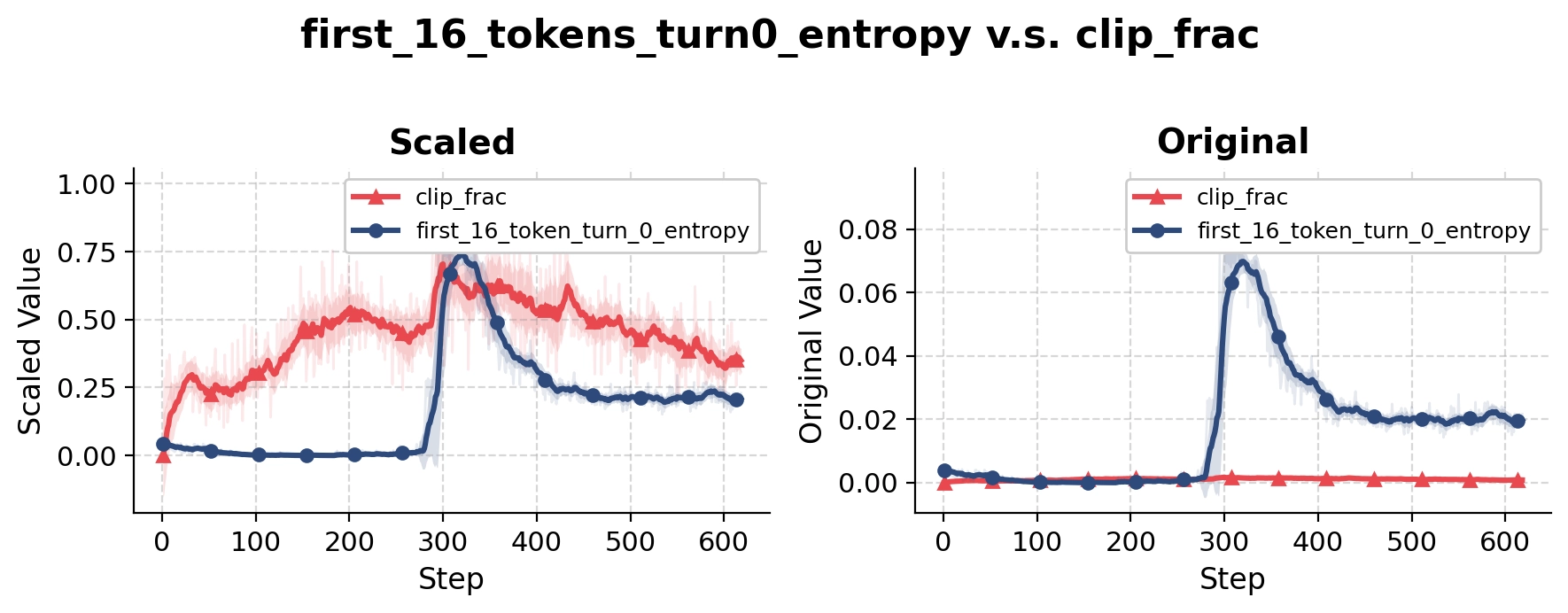
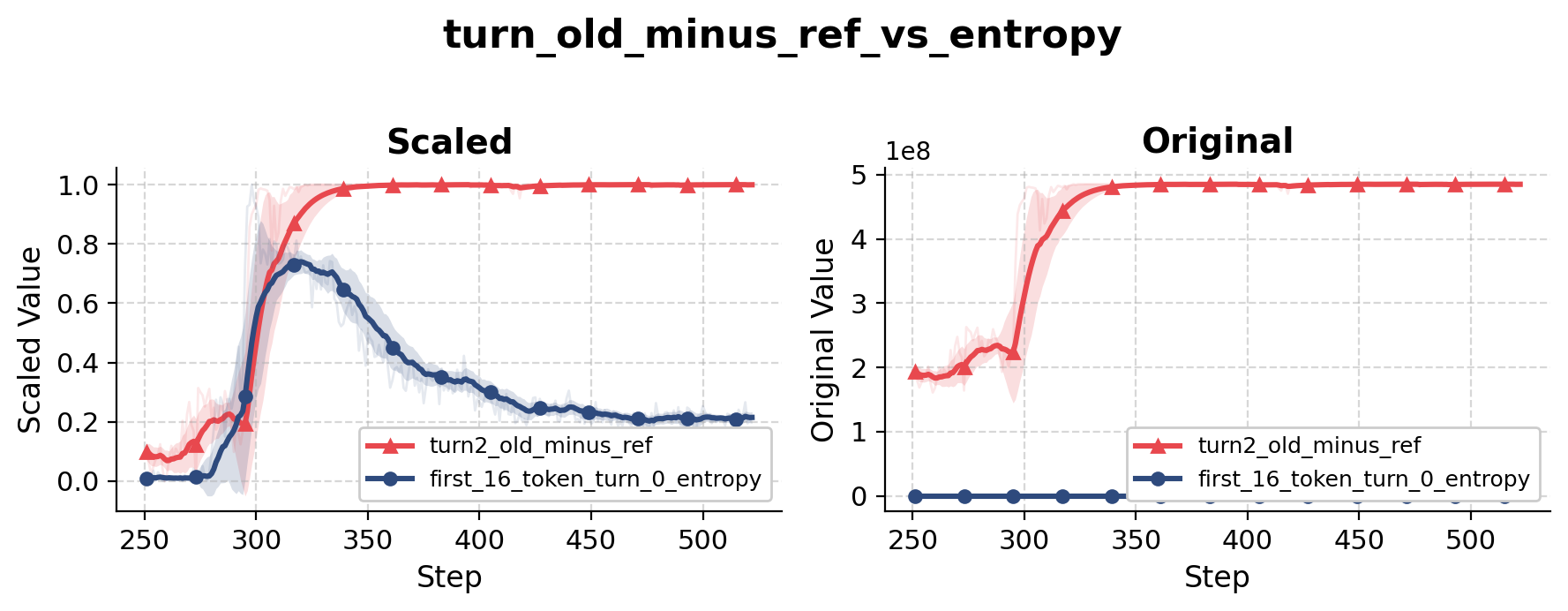
Instead of looking at individual tokens, we computed a turn-level measure of divergence from the reference model. Conceptually, the metric answers a simple question: how far has the current policy moved from the original SFT policy when generating an entire turn?
What stood out was not that the divergence increased. Any successful RL run should gradually move away from the reference policy. What stood out was how closely the divergence tracked changes in behavior.
Every major transition in rollout structure was accompanied by a noticeable increase in trajectory-level divergence from the reference model. Long before the behavioral change became obvious in rollout traces, the KL signal had already started drifting upward.
This observation gradually changed how I thought about the problem. I originally expected off-policy staleness to manifest as instability in optimization. Instead, what I observed was instability in behavior.
The optimization process itself remained surprisingly robust. The reward curve continued improving. Training did not diverge. Yet the strategy employed by the agent changed dramatically. The more rollout traces I inspected, the less the phenomenon looked like a classical optimization failure. It increasingly resembled a transition between distinct behavioral modes.
A Simpler Environment Might Be Hiding the Full Picture
One possible objection is that Search-R1 is too simple. The model only has a small number of meaningful actions available. If a behavioral transition occurs, recovery is relatively easy because the policy only needs to choose among a handful of alternatives.
To test whether the same phenomenon appears in richer environments, we modified the setup by introducing two additional tools. The first tool allows the model to request additional document chunks after an initial search. The second tool performs answer verification using an external verifier.
The resulting decision process becomes substantially more complex.
The model can now search, inspect additional evidence, verify intermediate conclusions, continue exploring, or terminate. Unlike the original setup, the agent is no longer deciding merely whether to search. It is deciding how to search. More importantly, the additional tools introduce qualitatively different behaviors. This turns out to be useful because behavioral transitions become easier to observe.
The Same Pattern Appears Again
One of the most striking observations in the expanded environment involves the verification tool.
At the beginning of training, the tool is rarely used. Most trajectories rely on search results alone and proceed directly to answering. Then, within a relatively short span of optimization steps, the behavior changes. Verification usage rapidly increases and eventually becomes almost deterministic. Trajectories that previously followed a simple pattern begin incorporating verification into nearly every interaction.
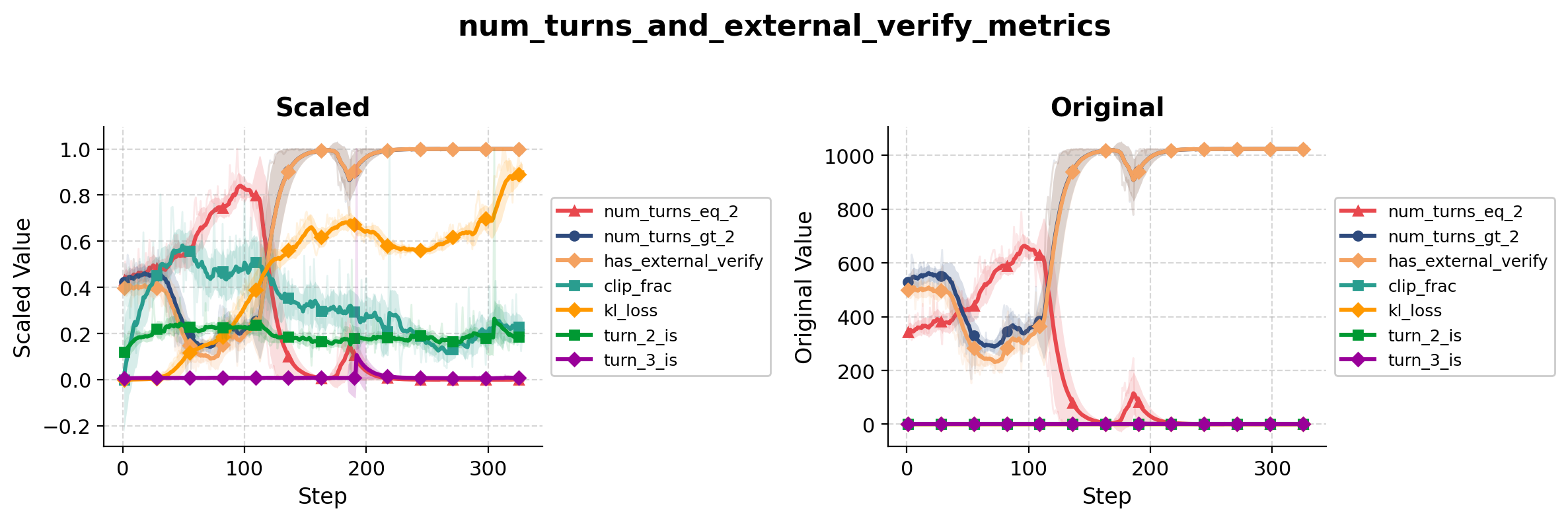
What makes this particularly interesting is that the transition looks remarkably similar to the earlier search-collapse phenomenon. In both cases, a stable behavior persists for a long period of time before suddenly giving way to a different strategy. In both cases, the transition occurs much faster than one would expect from a sequence of small policy updates. The difference is that this time the transition is beneficial.
Training accuracy increases after the verification tool becomes widely adopted. Unlike the previous collapse, which temporarily hurt performance, the new behavior improves it. This creates an interesting tension.
From the perspective of rollout dynamics, the two transitions look almost identical. In both cases, the policy rapidly shifts from one mode of behavior to another. From the perspective of reward, however, one transition is good and the other is bad. This suggests that what we are observing is not simply collapse.
The broader phenomenon is that Agentic RL appears capable of rapidly reorganizing its tool-use strategy during training.
Whether that transition is desirable depends entirely on where the new behavior leads.
What Metrics Actually Capture These Changes?
Once multiple behavioral transitions became visible, a natural question emerged. Can existing RL metrics reliably detect them?
The answer appears to be mixed.
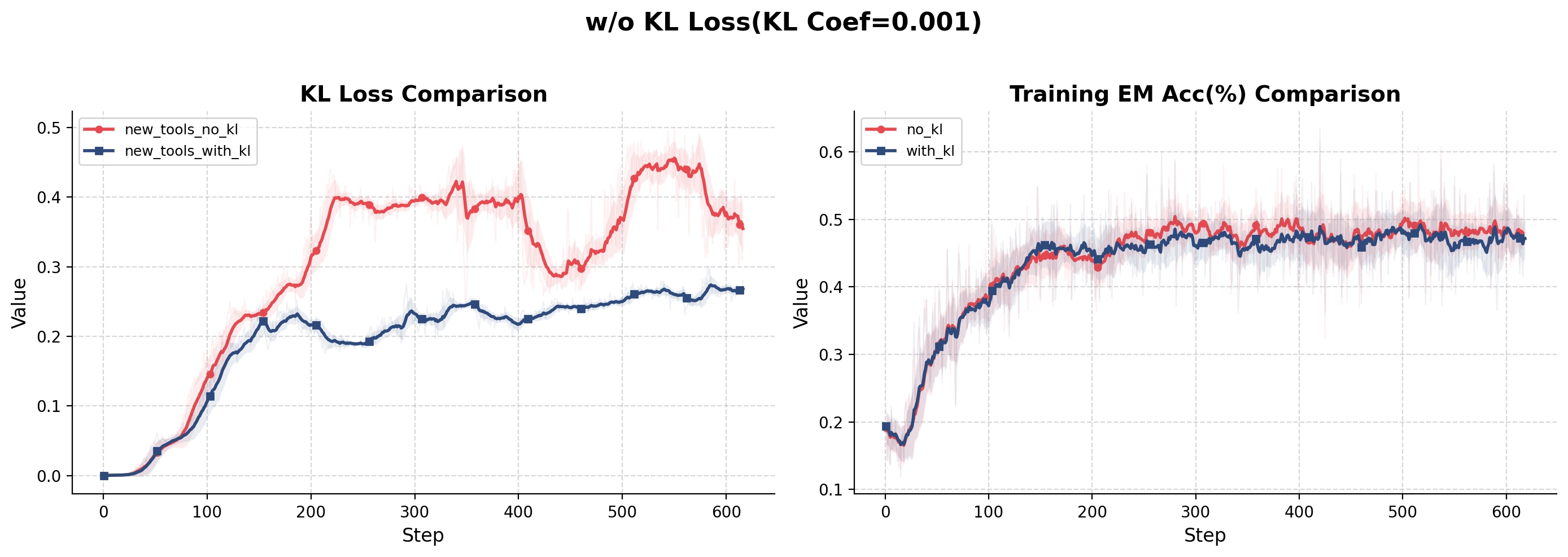
KL divergence, particularly divergence measured against the reference model, consistently tracks major behavioral transitions. Whenever the policy begins moving toward a new strategy, KL tends to increase beforehand. Importance sampling statistics are much less informative.
Despite substantial changes in tool usage, both token-level and turn-level importance sampling remain relatively stable in many cases. This is particularly surprising because one might expect large strategy shifts to be accompanied by correspondingly large importance weights.
What these experiments seem to suggest is that trajectory-level behavioral changes can occur without triggering dramatic changes in token-level correction mechanisms. A policy can remain locally similar while becoming globally different.
The sequence of actions chosen by the agent changes, even though individual token probabilities do not necessarily move far enough to activate strong clipping behavior. This may partially explain why reward curves often fail to reveal what is happening underneath. The agent is changing how it solves the task, not necessarily whether it solves the task.
What Changed My Mind
I started this investigation looking for evidence that multi-turn off-policy staleness is a fundamental obstacle for Agentic RL. I still think staleness matters, especially as trajectories become longer and tool interactions become more complex, but it is no longer the phenomenon I find most interesting in these runs.
What repeatedly surfaced across these experiments is that agent policies can move between qualitatively different modes of behavior during training. Sometimes the transition hurts performance, as in the guess-first behavior. Sometimes it improves performance, as in the adoption of the verification tool. Sometimes the policy eventually returns to its previous behavior after briefly exploring an inferior strategy.
The difficult part is that these transitions do not look equally important from the perspective of reward. A behavior shift may be harmful, helpful, or mostly neutral, while the reward curve remains too coarse to explain what actually changed. The agent is not only becoming better or worse at solving the task; it is changing how it chooses to solve the task.
This is why I now find behavior-level monitoring more important than I initially expected. Reward curves tell us whether the agent is succeeding. Rollout structure tells us how it is succeeding, and sometimes also whether it is succeeding for the wrong reason. In Agentic RL, those two stories are not always the same.
Limitations and Follow-ups
There are two limitations that I would like to explore next.
The first is whether the same phenomenon becomes stronger or weaker in thinking-mode models. The experiments in this article are still relatively short-horizon compared with modern reasoning agents. As response length increases, and as a larger fraction of tokens are spent on intermediate thinking rather than directly contributing to the final answer, the relationship between token-level optimization and trajectory-level behavior may become different. It is possible that longer reasoning traces smooth out some of the abrupt transitions observed here. It is also possible that they make the problem worse, because there are more opportunities for the policy to drift into locally rewarded but globally undesirable behaviors.
The second follow-up is how to automatically identify and mitigate bad explorations without suppressing useful ones. The verification-tool transition is a good example of exploration that should be encouraged, while the guess-first behavior is an example of exploration that looks more like metric hacking. For deep research tasks, one simple solution is to directly penalize obviously undesirable behavior. For example, if a task is identified as requiring external evidence, we can set the reward to incorrect and terminate the rollout when the agent attempts to answer in the first round without making any search call.
However, this kind of rule-based punishment is brittle. It depends heavily on human-defined heuristics and may not generalize across tasks, tools, or domains. A more flexible alternative is to use a model-based monitor that evaluates whether the trajectory is following a reasonable research process. Instead of hard-coding rules such as “always search first,” we can ask a separate model to judge whether the agent’s behavior is justified given the task. This would allow the training process to penalize bad shortcuts while still preserving useful exploration when the model genuinely has enough information to answer.
The broader question is whether we can build training systems that distinguish productive behavioral transitions from harmful ones as they happen. If Agentic RL is better understood as a sequence of behavioral phase transitions rather than a smooth optimization process, then stabilizing training may require more than token-level clipping or standard reward shaping. We may need trajectory-level monitors that understand not only whether the final answer is correct, but also whether the agent arrived there through a robust and desirable process.