item2vec
Usage: item2vec learns item similarity.
Motivation
Item2item relations are important because different than the traditional user2item relations, it shows a more explicit user intent of purchasing. Therefore it has a higher click-through rate.
Solution
Skip Gram
Skip-gram is used to predict context words given a target word.
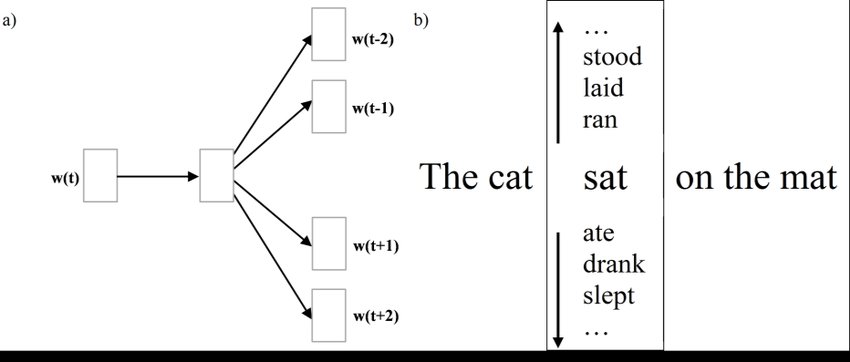
For e.g. word "sat" will be given and we’ll try to predict words cat, mat at position -1 and 3.
First introduce skip-gram objective. It aims at maximizing the following objective
\[\begin{equation} \max_{|W|} \; \frac{1}{K} \sum^k_{i=1}\sum_{-c \le j \le c, j \ne 0} \log \;p(w_{i+j} | w_i) \end{equation}\]| $p(w_{i+j} | w_i)$ is softmax function. |
This means given a word $w_i$, what is the most likely words regarding the given word. Negative means the words before current word and positive means words after this word. This learns context information.
Negative sampling
Goal
Try to find whether it is in the corpus, and find the best distribution parameter that maximize the probability that the data retrieved is from corpus.
The following document is very clear about what is intuition behind negative sampling and why should we use it.
Typically using gradient descent is a method to optimize equation (1), however, calculating gradient on softmax function is costly because corpus is often more that 5-6w words.
Instead, they use the following equation:
\[\begin{equation} p(w_j | w_i) = \sigma(u^T_jv_j) \prod^N_{k=1}\sigma(-u^T_iv_k) \end{equation}\]where $\sigma(x)$ is sigmoid function.
A negative word $w_i$ is sampled from the unigram distribution.