Overview
- 什么是LLM?
- LLM的Intuitive是什么?
- LLM的原理是什么,底层是如何实现的?
- 相比于其他方法,LLM为什么能够达到更好的效果?
- LLM产业运行的难点在哪里?
- 如果我现在起步,做和LLM什么相关工作比较好?机会点在哪里?
- 如果有一个LLM相关工作的Roadmap,这个Roadmap是什么?
- 如何与我现在的工作内容产生联系,让我更好起步?
因为我算是LLM领域的小白,所以我想从NLP的历史出发,看看如何一步步演变成目前的形态。
Background
NLP的Intuitive是什么?为什么这种方法可行。
Intuitive
Statistical Model
参考这篇2001年的论文A Bit of Progress in Language Modeling, 统计模型主要解决的问题是,一个单词序列出现的概率有多大。即给定一个单词序列$\omega_1, \omega_2, …, \omega_n$ ,这组单词序列出现的概率定义为$P(\omega_1…\omega_n)$,这个概率key被定义为一个组合概率:
\[P(\omega_1...\omega_n) = P(\omega_1) \times P(\omega_2 | \omega_1) \times P(\omega_3|\omega_1\omega_2) \times...\times P(\omega_n|\omega_1...\omega_{n-1})\]但是句子的长度是不固定的,对于任意长度的句子,如果都用这样的概率计算,那么这个计算量是非常大的,因此有n-gram的概念,即在某$n-1$个单词出现后,第$n$个是某个单词的概率是多大。
前两个词已经出现的情况下,第三个词出现的条件概率可以简化为在一个语料库中出现的频率。
\[P(\omega_i|\omega_{i-1}\omega_{i-2}) \approx \frac{C(\omega_i)C(\omega_{i-1})C(\omega_{i-2})}{C(\omega_{i-1})C(\omega_{i-2})}\]这些概率模型有一些问题,比如光看统计特征,对于经常出现的或者只出现一次的词会有异常,因此引入了smoothing方法,这里不再赘述。
这些方法都有一个本质的问题,就是扩展这个序列的长度就能收获更好的效果,但同时扩展这个长度会增加计算量。因此如何获取到词与词之间的关系,尤其是上下文比较长的时候,对Statistic Model来说是一个无法解决的问题。简称the curse of dimensionality。
Neural Statistic Network Model
NLP统计学模型的dimensionality的本质是什么?假如语料库中有$n$个单词,其本质就是这$n$个单词的联立概率分布。即给定$i-1$个单词,模型可以找到下一个概率最大的单词。考虑到这个概率模型过于庞大,因此在2003年的文章A Neural Probabilistic Language Model中提到可以使用神经网络将单词转化为一个特征向量,并用这个特征向量计算单词之间的概率分布。本质上是用神经网络来拟合这个联立概率方程。优点是这个特征向量是一个高密度向量,易于计算。
这个模型的输入是上下文转化后的dense feature vector,输出是和这个单词相关的下个词的概率。即,
\[f(\omega_t,..., \omega_{t-n+1}) = \hat{P}(\omega_t | \omega_{t-1}...\omega_{t-n+1})\]因此在训练时,设置损失函数是输出函数的log likelihood,即最大化以下这个方程时的$\theta$.
\[L = \frac{1}{T}\sum_{t}\log f(\omega_t,\omega_{t-1},...,\omega_{t-n+1};\theta) + R(\theta)\]神经网络结构如下图所示:
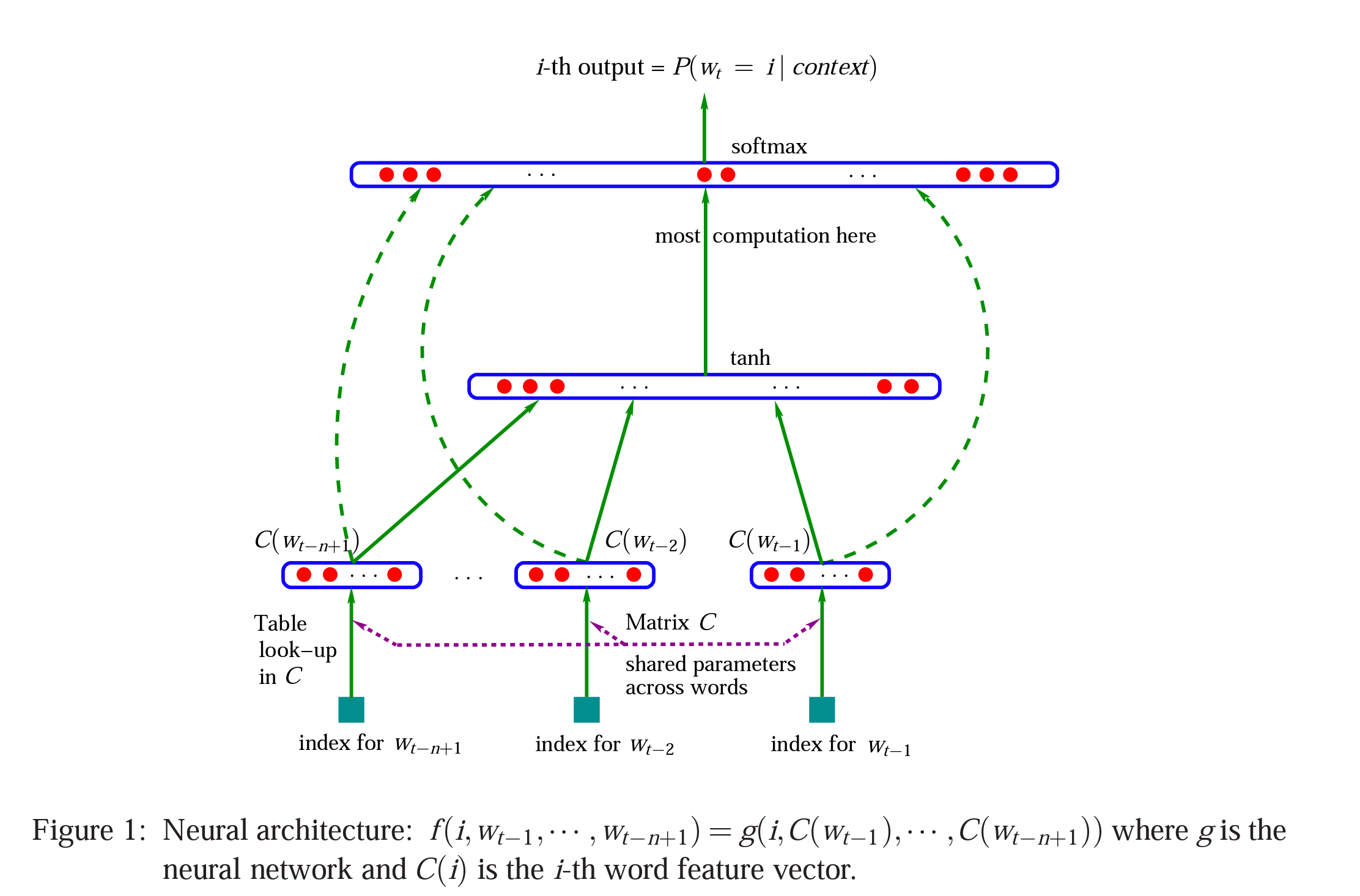
这个神经网络通常被称为Feedforward Neural Net Language Model(LLNM)。该模型通常的工作流程是
- Training
- 初始化:在语料库中,一共有V个不同的单词,初始化V个长度为m的向量,生成一个$|V| \times m$大小的矩阵;
- 训练:每t个单词为一组,组成一个$t \times m$大小的矩阵作为Input Layer。经过hidden layers后经过最后的softmax得到一个概率vector,其中的第i个元素为下一个单词的概率。loss function是上文提到的L。
- Inference
- 推理阶段,对于一段给定的sequence,需要计算这段sequence和语料库中所有词的概率,找出概率最大的词,即为这段sequence的下一个词。
- Output layer:大小是V,即整个语料库的下一个单词的概率分布。
Word2Vec
以上还都是统计学模型,即产出本身还是一个联立概率分布,并没有针对Word vector之间的计算做优化。而word2vec模型本身可以直接通过向量计算得到Context或者下一个词,这是一个非常大的突破。word2vec有两种模型,分别是
- CBOW(Continuous Bag-of-Words)
- Skip-gram
这两者的对比可以参考下面的表格。
| Feature | CBOW | Skip-gram |
|---|---|---|
| Input | Context words | Target word |
| Output | Target word | Context words |
| Training objective | Predict the target word | Predict the context words |
| Strengths | Faster to train, better accuracy for frequent words | Better accuracy for rare words, works well with small datasets |
| Weaknesses | Suffers from data sparsity, less flexible | Slower to train, less accurate for frequent words |
| Applications | Text classification, sentiment analysis, question answering | Machine translation, natural language generation |
Word2Vec和NNLM有什么不同呢?作者采用了两步进行训练
- 使用简单模型学习Word vectors;
- 基于上一步的简单模型,训练一个N-gram的NNLM模型。
CBOW & Skip-gram
NNLM和CBOW以及Skip-gram的区别是什么?
- NNLM
- Input Layer,对N个单词进行编码。
- Projection Layer,使用投影矩阵,将N个单词投射成$N \times D$大小的矩阵;
- Hidden Layer,将$N \times D$大小的矩阵进行计算,如果该层的神经元数量是H,那么需要进行$N \times D \times H$次计算;
- Output Layer,最后需要进行$H \times V$次计算形成联立概率分布。
- CBOW
- Input Layer,对N个单词进行编码;
- Projection Layer,经过Projection Matrix以后,所有单词会被映射到一个相同的位置,因此这个projection Matrix会被所有Word vector共享;
- Output Layer,Huffman编码softmax,计算量可以变成log-linear的。
- Skip-Gram
- Input Layer,某个单词的编码;
- Projection Layer,将这个单词Project到D个神经元上;
- Output Layer,将上一个单词映射到输出上;
- 上述过程需要重复C次,C可以看成N。
可以看到CBOW移除了Hidden Layer,并且共享了Projection Matrix,且到Output使用了softmax。因此可以大幅减少运算量到$Q = N \times D + D \times \log_{2}(V)$。而Skip-gram因为需要计算每个单词,因此计算复杂度为$Q = C \times (D + D \times \log_{2}(V))$。
Sequence 2 Sequence
如果说以上还都是基于统计学模型进行的基于词和Sequence之间分布关系,那么这个s2s的模型就是针对如果从一段话衍生出另一端的话的模型了。
直观来看,这样的模型难点在于输入和输出都是不定长的,这也给模型的处理带来了很大的难度。
所以该模型引入了Encoder和Decoder的概念。即,对于一个LSTM模型而言,这种算法会在计算时有一个固定大小的Hidden state,这个Hidden state的大小是固定的,能够把任意长度的input,encode成固定长度的embedding。Decoder也是一个LSTM模型,直接将Encoder的Hidden state作为其自身的Hidden state,通过一个Softmax Layer生成结果。
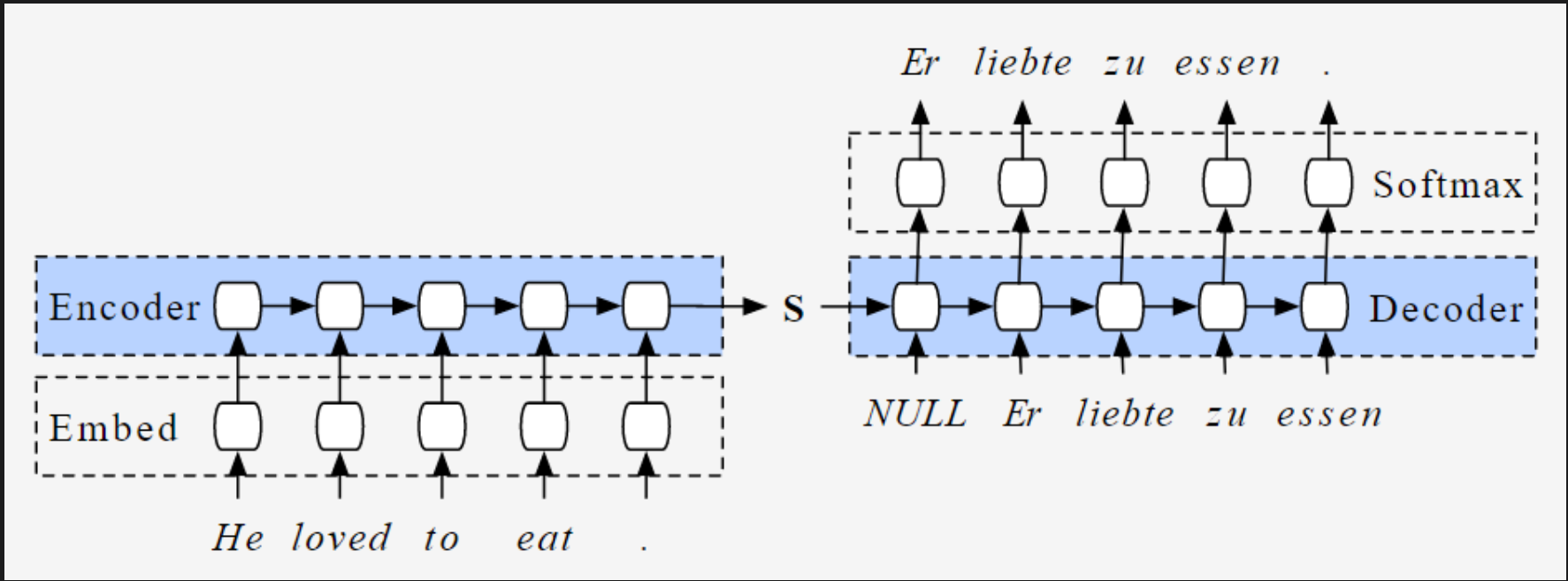
这个方法本身可以看到有一个缺点,
- 无法并行化计算;因为Recurrent需要用到上一步的结果。
也有几个优点
- 能够捕捉全局特征;因为Hidden state可以保存全局结果;
Attention Model
如果说引入了Recurrent Network会导致无法并行计算,能否结构这种循环,并同时捕捉到全局特征?
Attention本质上就是在这个思考上提出的方法。可以看下面的图,首先Encoder是把6个相同的两层结构堆叠在一起,这个两层结构一层是Multi-head Attention Layer,一层是把结果和Input想加后再标准化。这样做就避免了必须在RNN中串行计算的缺点。Decoder的结构类似。
Attention的本质是什么,就是在NN网络里面加上一些结构,让模型更关注Input和Output中更重要的模块,方法是给不同的Token分配不同的权重。那为什么下面这个网络结构可以做到这点呢?
这里的Q,K,V实际上对应的Information Retrieval系统中的Query,Key和Value。即,给定一个Query,找到系统中最相近的Keys,再把Keys对应的Value作为返回,只是在语言模型的场景下,Value也是Embedding矩阵。原理是在矩阵乘法后给这些Keys做一个权重分配,找到Keys中权重最大的部分,随后再与结果矩阵点乘,得到结果,结果可以视作和Query(Input)最相关的一个Sequence,并返回。
这种只有前向传播,没有回环结构的神经网络,很好的规避了LSTM模型无法并行化训练的缺陷,并做出了非常好的效果。
GTP-2
Motivation
- 目前的NLP任务都非常专注在一个小的领域和数据集,导致了无法transfer到其他任务上;
- 多目标学习在扩展数据集和目标上非常困难,导致了上述问题其实是一种妥协(想不专注也不行);
Approach
- 预训练:使用WebText数据集去来最大化下一个单词的可能性;
- Evaluation:使用zero-shot在不同的NLP任务上进行fine-tune,并评估其表现。
GPT-3
Initiative
GPT模型认为,正是因为很多NLP任务的数据集被限定在完成某些特定的任务,才使得这些模型的泛化效果这么差。如果数据集可以扩充到很大,那么这个模型的能力也会非常强大。
但这样会碰到一个问题:数据集的标注太少了。与所有的文本数量相比,有标注的文本只占其中很少一部分。因此,GPT-2模型使用了非监督预训练和有监督训练相结合的方式,前者使用海量文本学习文本之间的模式,例如语法、格式和前后文,后者在前者的基础上针对不同的任务进行微调(fine-tune)。
Architecture
模型和训练:
- 训练了一个1750亿参数的自回归语言模型GPT-3
- 模型规模比之前最大的模型GPT-2(15亿参数)提高了100倍以上
- 使用了类似于GPT-2的transformer架构,但采用了稀疏注意力模式
- 在过滤后的Common Crawl数据以及像WebText2和BooksCorpus这样的精选数据集上进行训练
- 训练了8个规模从125M到13B的较小模型进行比较
评估:
- 在零样本、一次样本和少量样本情况下,在二十多个NLP数据集上评估了模型
- 零样本:只有任务描述,没有样例
- 一次样本:任务描述 + 1个样例
- 少量样本:任务描述 + 最多100个样例
- 将GPT-3与SOTA微调模型和较小的GPT-3模型进行了比较
结果:
- GPT-3在许多数据集上取得了很好的结果,接近或超过了SOTA
- 在闭卷问答、翻译和任务适应方面表现特别强
- 在一些基于比较的任务(如NLI)方面表现较弱
- 随着模型规模的增加,零样本、一次样本和少量样本之间的差距越来越大
分析:
- 测量了测试集受训练数据污染的影响
- 大多数数据集影响很小,但标记了一些有问题的情况
- 进行了与性别、种族和宗教相关的偏见分析
- 生成的样本难以区分是否为人类所写
局限性:
- 与人类相比,样本效率仍然很低
- 偏见仍然存在,公平性难以完全描述
- 大型模型的部署存在障碍
- 类似于蒸馏的方向可以帮助解决这些问题
更广泛的影响:
- 讨论了潜在的误用可能性和需要有误用抵抗能力的系统
- 描述和解决了测试集污染的问题
- 进行了模型偏差的初步分析
- 注意到了能源使用、公平性和潜在的负面社会影响问题
Summary
- 为什么说大语言模型实际上是概率模型?
- 因为从始至终,大预言模型优化的都是在给定一个sequence的情况下,最大化所有单词中下一个单词的概率,即使是最新的方法也是如此。因此,可以把大模型看做从海量语料库中找规律,而不是这个模型真的理解他在做什么。
- 这也解释了为什么大语言模型会有幻觉,因为毕竟是统计规律,而只要想办法把这个统计特征hack了,就能改变这个模型的结果。
- 为什么prompt有效?
- 因为大语言模型学习了单词之间的规律,还需要被下达某种指令,才能真正让它输出我们想要的结果。