Problem Trying to Solve
提升大模型对多模态(语音,图像,视频,文本)的理解和推理能力,从而实现多模态理解和生成的能力。
解决方法
LLaVA
- 要解决的关键问题
- 构建一个有reasoning ability的,可以follow instruction的多模态模型;
- Instruction following的MultiModal数据的缺失;
- 如何使用现有大模型把这几个功能融合在一起。
- 算法的根本思想
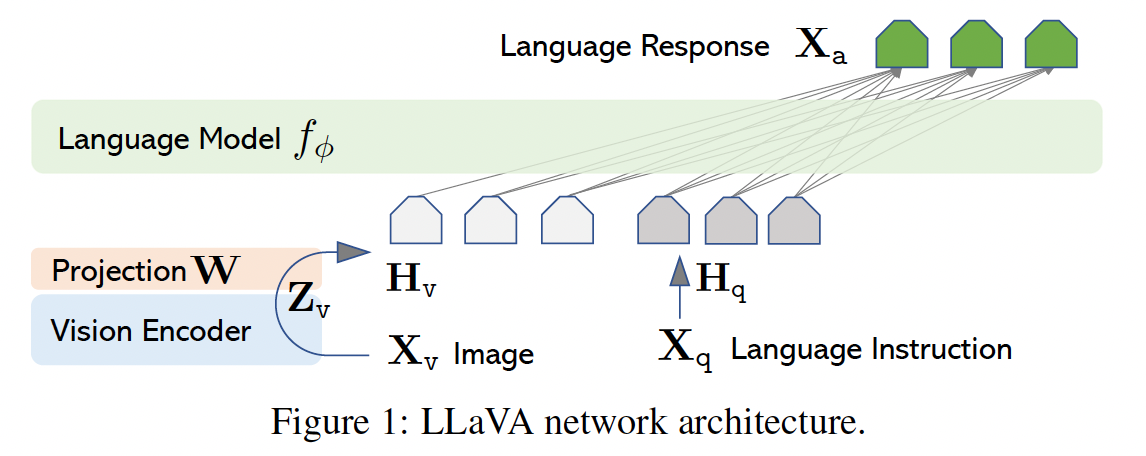
- ==通过GPT-4 Prompting构建训练集(包括与图片相关的对话、细节描述和复杂推理)==,使用了预训练的Vision Encoder(CLIP)把Image Token通过一个Projection matrix转化为一个文本长度的Embedding,并和文本的Embedding一起送入LLM得到prompt对应的结果(对话、描述和推理)。
- Model Architect
- 算法流程
- Pre-train alignment
- LLM和Vision Encoder的weights都是frozen的,只学习Vision Encoder到LLM Token的projection matrix
- Fine-tune到各种下游任务
- visual Encoder的weights frozen,LLM和Projection Matrix的weights更新以适应成为Chatbot等。还有一些为了刷榜做的adaption。
- Pre-train alignment
- Experiments
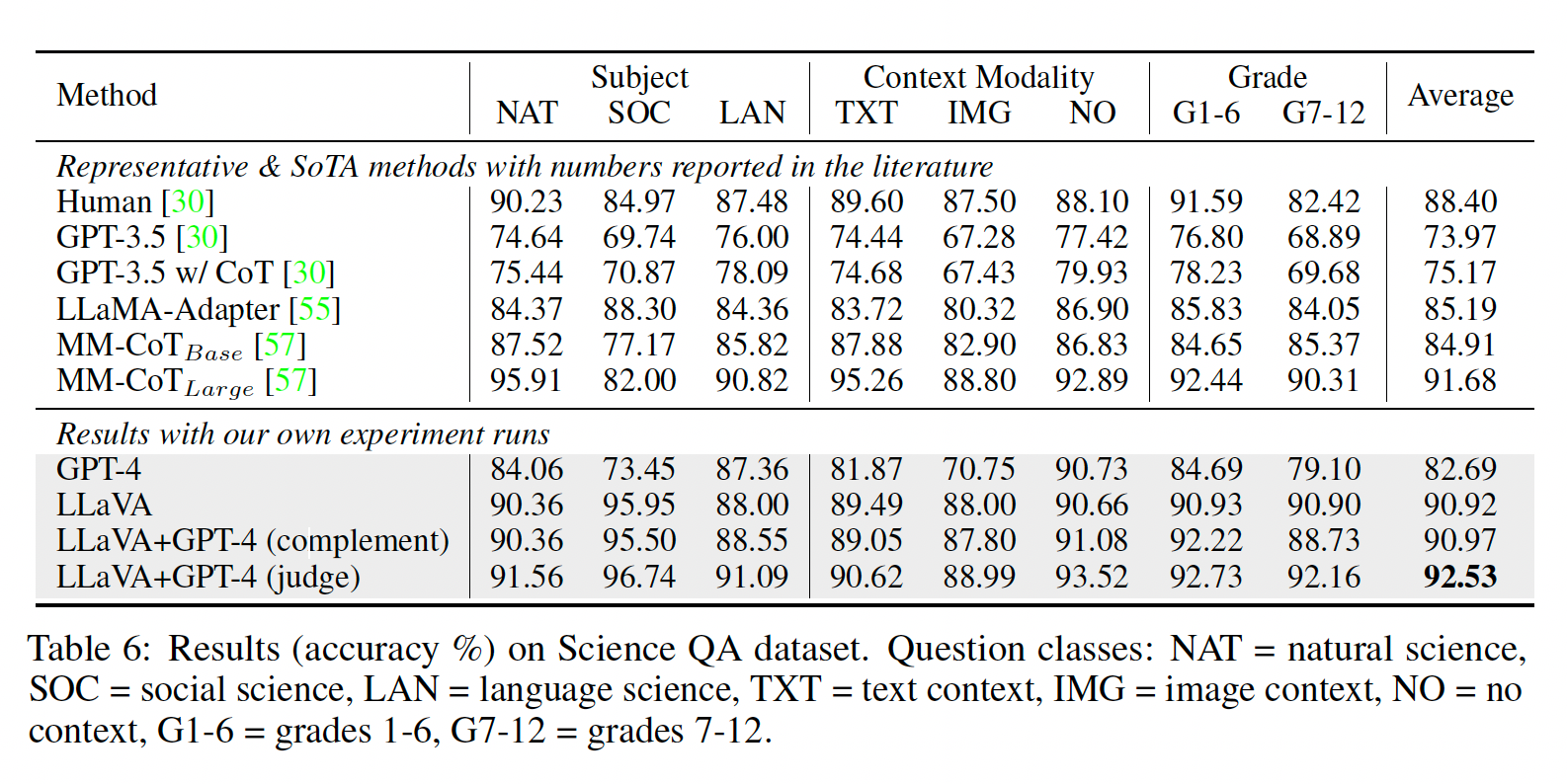
- Ablations
- 用了不同版本的CLIP,最好的和最新的有0.96的差距,作者分析原因是现在的CLIP last layer更多关注图片的Global information,所以和他的前代相比,在描述图片细节的时候会有一些差距
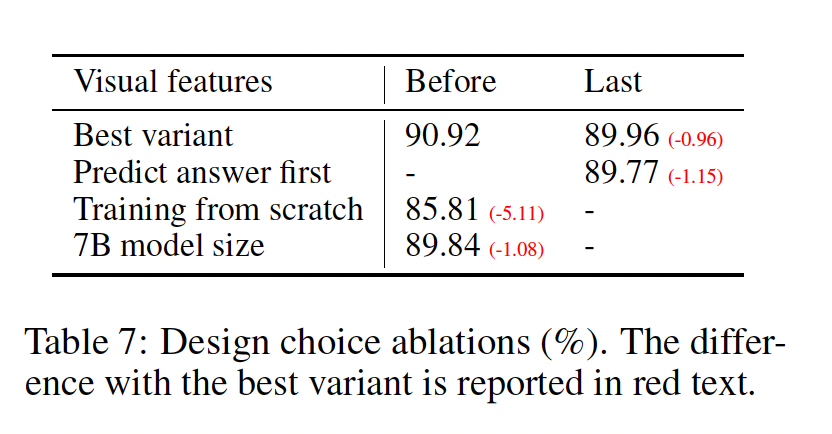
- Take aways
- LLaVA使用的prompts
- LLaVA如何在Prompts里面用images做few-shot: https://github.com/haotian-liu/LLaVA/blob/6944051041cd1ab3b68fd5c7920153d6cc1824a8/llava/mm_utils.py#L43
- 在Prompts里面放base64编码的image
- 取出image并Tokenize送给大模型
- LLaVA使用的prompts


PREVIOUSAI算法