Problem to Solve
Alignment
Solutions
Actor-Critic
- 要解决的问题
在RL的过程中,即学习策略,又学习价值函数,这样保证策略迭代的过程中,Value是逐渐变高的。
- 根本思想
- 为什么可以同时学习Value function和Policy function?
- 因为使用了能将二者结合的损失函数,例如时序差分残差
-
可以在总回报中引入基线函数以减小方差,例如这种形式:
- \[\nabla_\theta J(\theta)=\mathbb{E}\left[\sum_{t=0}^{\infty} \nabla_\theta \log \pi_\theta\left(a_t \mid s_t\right)\left(Q^{\pi_\theta}\left(s_t, a_t\right)-b\left(s_t\right)\right)\right]\]
- 原因:RL过程中,不同的策略可能带来的方差差异非常大,因此会使学习过程不稳定,引入基线函数可以使方差减小,从而增加学习的稳定性。
使用PPO进行fine-tune
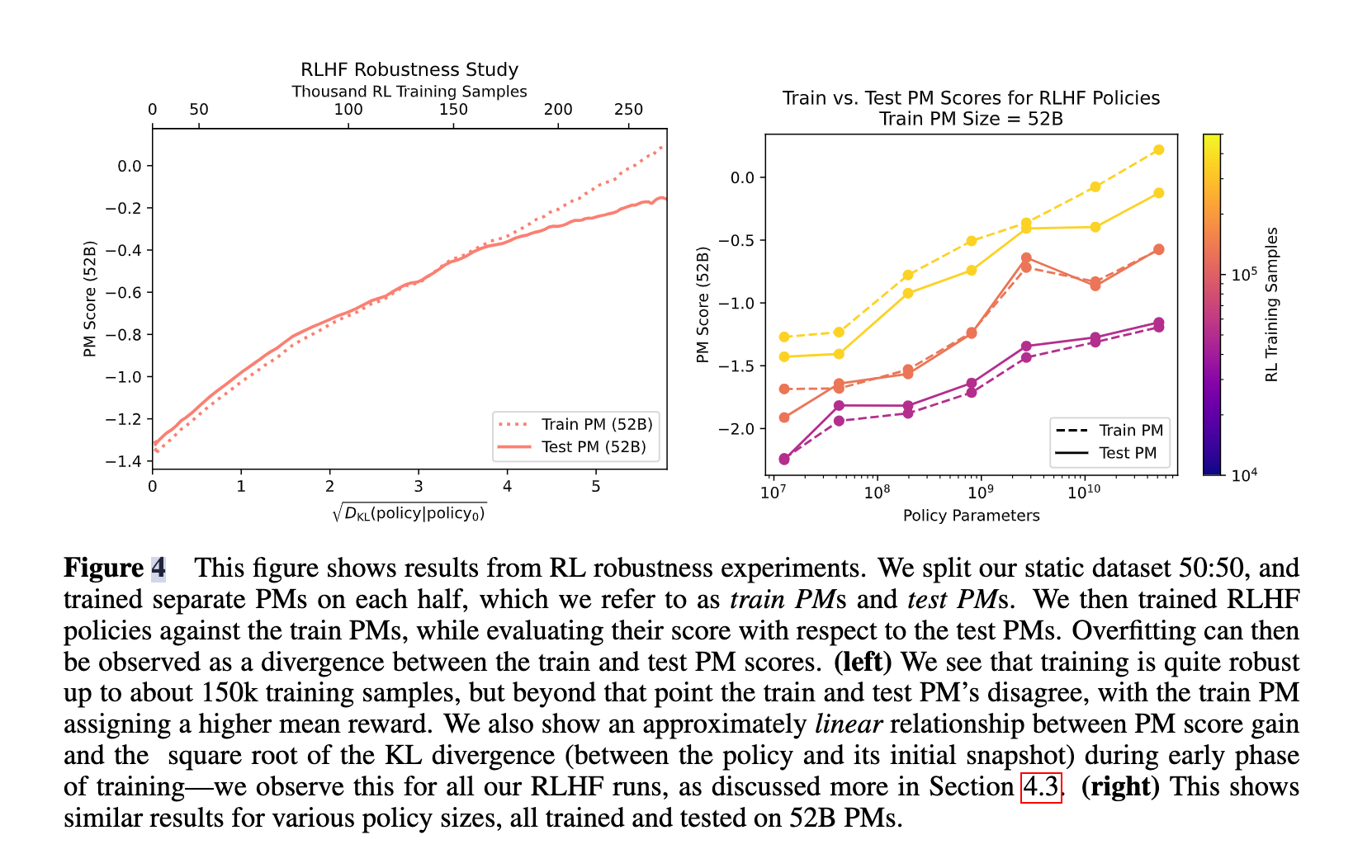
发现PPO中的KL Divergence和开根和PM Score有一个近似的线性关系。(PM就是preference Model)
PREVIOUSAI算法