输出如何严格按照格式?Guided Generation
- 类别:推理
- 一句话总结:Guided generation能够根据限制条件的格式(比如regex,JSON等),在一个vocab的子集上选择要解码的tokens,从而让结果严格遵循输出格式。
Existing Gap
在业务场景或者需要用到LLM的场景下,很多结果必须生成固定的格式才能被解析,被其他应用使用。一个naive approach是,直接在instruction里面放入相应的格式指令和样例输出,但这还是有概率产生解析错误。所以如何严格让结果按照期待的格式生成?
Proposed solution
传统解码过程
首先我们理解,LLM的解码过程是next token prediction,所以可以把解码过程想象成一棵树,这个树有无数的分叉,最终我们在这个树上可以找到一个路径,这个路径就是最终解码的结果。
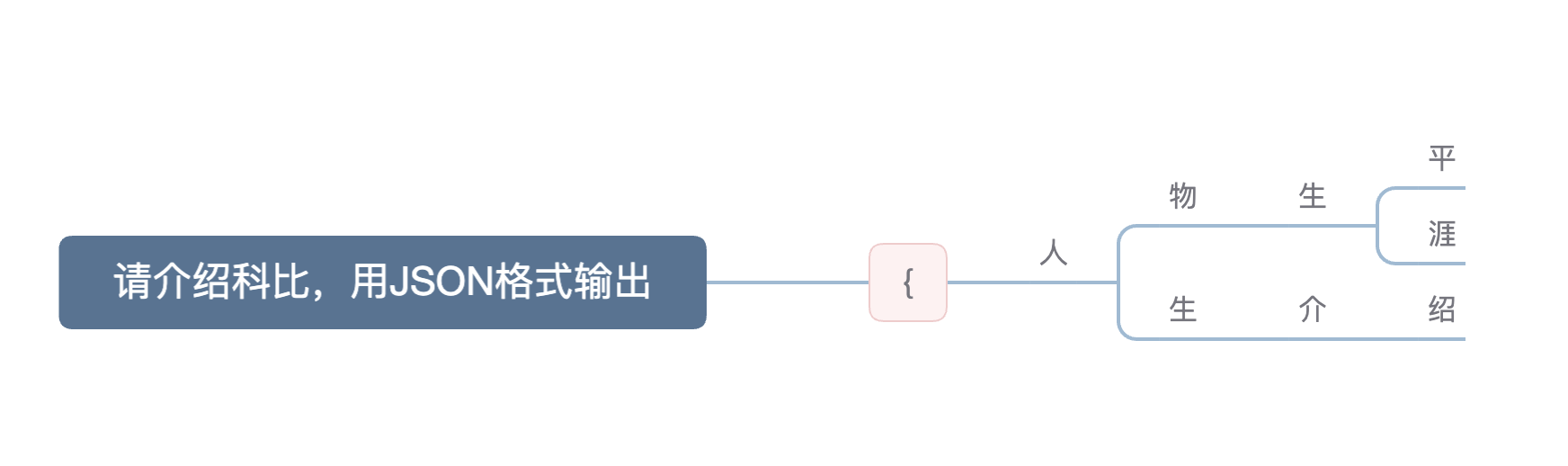
可以看到,解码过程中,第一个token必须是{,否则这就不是一个严格JSON格式。随后可能有各种可能的文本组合。
FSM Processing & Indexing
FSM(Finite state machine)就是有限状态机,每刻的状态由已经解码过的token和在限定规则下可用的vocabulary mask组成。打个比方,假设我们人生一共有4个状态,读研(state 1),读博(state 2),工作(state 3),博士后(state 4),当你处于某个状态时,这四个状态并非都可以选择的,所以假设你刚读完本科,你的state mask是[1, 1, 1, 0]。即你可选读研,直博,工作,但无法直接博士后。假设你选择了读研,此时你的state是0->1,你的下一步的state mask是[0, 1, 1, 0]。假设你选择了工作,那么你的state变成了0->3,你的下步state mask是[1, 1, 1, 0],如果你本科毕业选择了工作,而后再次读研,那么你又回到了state 1,此时你的state是0->3->1,而在state 1,你的state mask是[0, 1, 1, 0],这和你本科毕业读研后的状态是一致的,选择也是一致的,但如果state是0->3->4->3,那么此时的state mask就是[0, 0, 1, 1],这和0->3到达的state 3时候的state mask是不同的。
读到这里你可能已经理解了FSM在decoding时候的作用,即,在已经给定sequence,FSM会需要根据限制条件给出state mask,并决定下一步产出的token是什么。这个token一定是符合要求的。
Indexing要做什么就能立刻理解了。可以预见的是,如果每个token都根据限制条件计算一遍state mask,decoding的速度会有多慢。所以这里可以用一个hashmap做Indexing,简答来说就是把每个sequence的可能state mask全都提前计算好,那么decode的时候直接做一个O(1)复杂度的查找就可以。但这样做的缺点也是显而易见的,
- 不同的限制条件需要建立一遍Indexing;
- 部分限制条件的index可能会非常大,占据很高的存储空间。
- 这种解码对效果大概率是有损害的,有多少损害,下一篇文章会讲。
Application
在Huggingface的text-generation-inference包里面,已经实现了定制化Guidance Generation,可以参考这个网址:https://huggingface.co/docs/text-generation-inference/conceptual/guidance#guidance。Transformers也可以定制Generation Config的方法来定制化decoding strategy:https://huggingface.co/docs/transformers/generation_strategies。
总结
本次概念讲解了如何使用Guided Generation来实现严格格式化输出,下个概念会介绍这种方法的优劣以及如何避免这个方法带来的表现下降。