Speculative decoding: 加速大模型生成速度
- 类别:推理
- 一句话总结:Speculative decoding(推测解码)是利用小模型生成的草稿(Draft)并验证该草稿正确性(verify)实现的推理加速。
Existing Gap
目前超大模型的生成速度非常慢,有没有什么办法能加速?
Proposed method
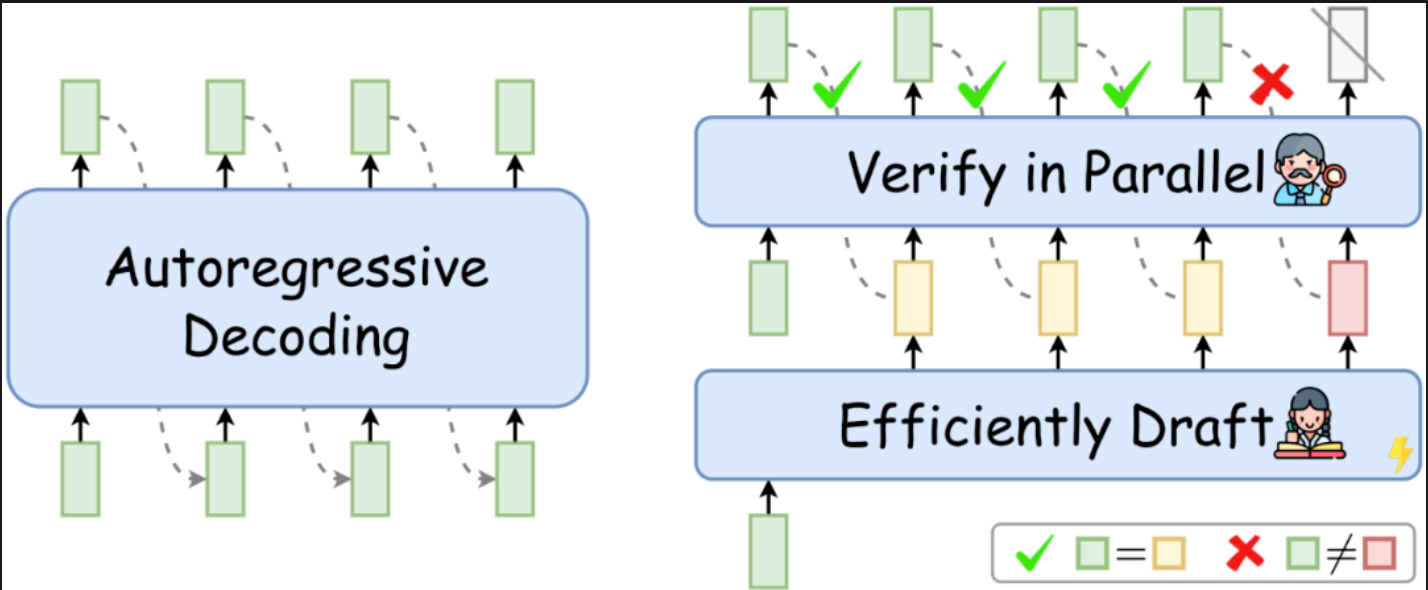
打个比方,现在有个学霸,在做n道计算题,这第n道计算题只在前n-1道题都做完且做对的情况下,才会给到该学霸。现在有个学渣,也要做n道题,正确率很低,但做的速度非常快。现在想让这个学霸做的快点怎么办?这里给的方法是让学霸偷个懒,假设学霸做了一道题,学渣做完了4道,学霸会检查第4道题的正确性,如果第4道题做对了,学霸就不管没做的3道题了,直接抄学渣的。然后开始做下一题,就这样循环往复。最差的情况就是学渣全做错了,学霸还和以前速度一样,否则就一定比现在挨个做快。
这就是Speculative decoding的核心原理,包含两步,Draft和Verify。这里的Draft就是一个小模型生成的结果,而Verify就是大模型会检查小模型生成的结果,前序序列正确的情况下,则直接采用,否则需要按正常顺序解码。例如在下图中,Draft是黄色块,大模型会根据前几个块生成下个token,如果相同则该Draft一定正确。
Limitations
- 大小模型最好是同源模型,在相同数据上训练过,则这种方法可以work,比较适合大公司;
- 对于需要在decoding时候做sample的不能用,只适用于Greedy decoding等deterministic的decoding方式。
PREVIOUSAI算法