Deepseek没写的技术细节-RL可能是烟雾弹
不同任务的Reward设计
编程的数学的Reward比较好设计,有编译器和最终结果。但R1不仅是数学和编程,R1的开放式问题回答得都非常好(思路清晰,结构完善),作为对比,Openai的O3的==非数学和编程问题==回答的和4o基本上没区别。开放式回答仅靠Format Reward就能达到如此好的效果吗?考虑到R1的冷启动阶段经过了SFT,理论上Format不会有任何问题,所以Format Reward的结果可能全是1,这里肯定还有别的Reward。比如,开放式回答让模型生成尽量全面结果的Accuracy Reward。
RL作用的粒度
如果只作用于结果,而不作用于reasoning,是没有理由画出来第8页的推理时间随训练时间逐渐增长的曲线的。
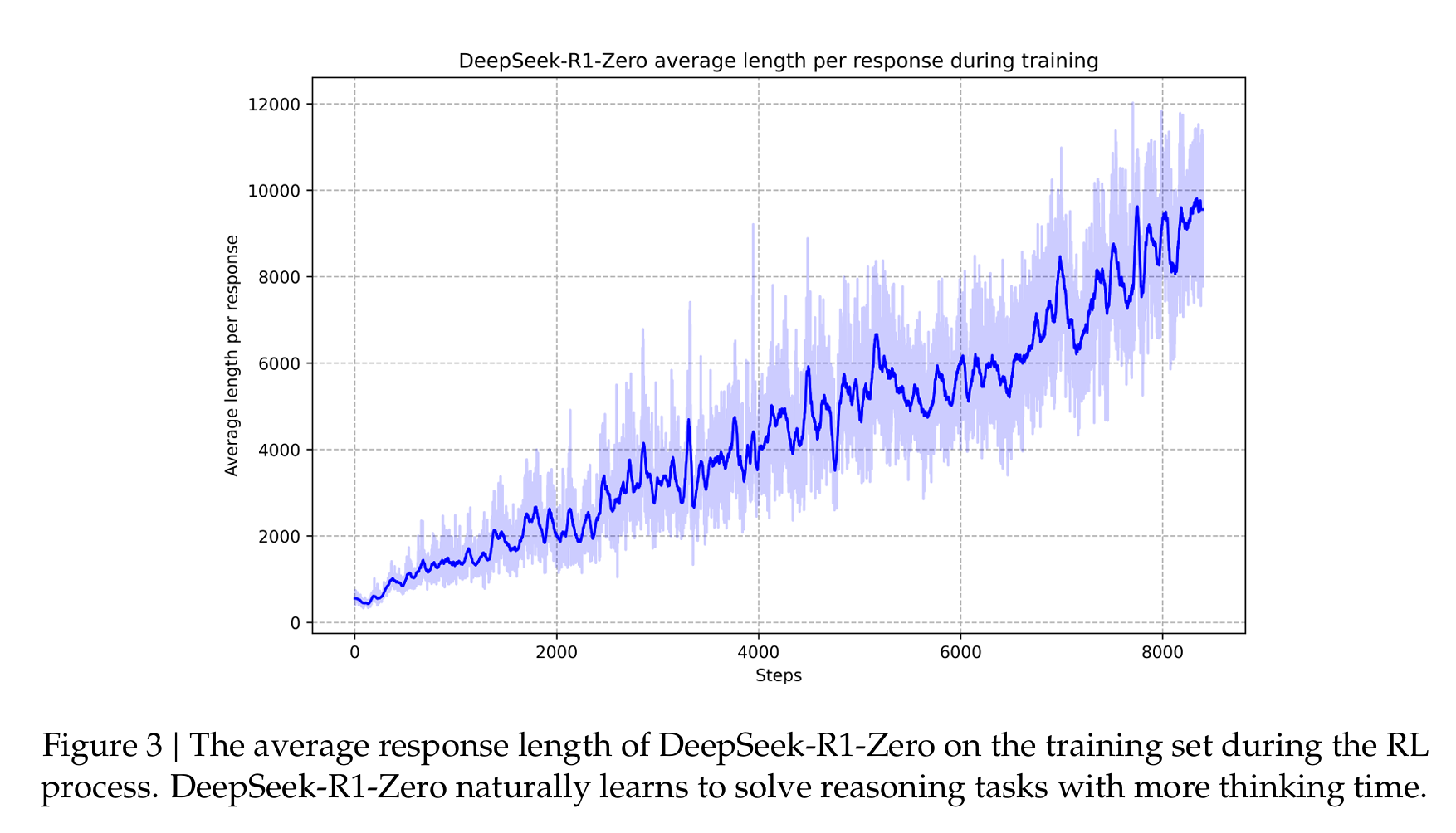
所以,训练时候reward一定鼓励了模型增加自己的reasoning的长度,但不一定是通过设计Reward Model实现的,也可能是用数据实现的。比如,GRPO中这个group的outputs到底是什么,是纯policy model生成的几个,还是做了一些策略,比如把多步reasoning和单步reasoning都放到一个group里面,只是思考时间长的正确率高,所以训练会favor更长reasoning。
SFT的数据设计
这个非常关键,有几个观察可以佐证。
- 人工检查:我看了下回答,开放式回答的format一致性是非常高的,都是分步,分点回答的,说明SFT的Format是经过了设计的。
- Distillation结果,直接使用R1蒸馏出来的数据,对其他开源模型进行SFT,其他开源模型的结果都变好了,进一步验证了,SFT对R1实际表现很重要;
- Qwen-32B-zero的结果,在Qwen-32B小模型上直接用RL方法,而不经过任何SFT,效果跟R1-zero差不多,但R1蒸馏数据SFT之后的Qwen-32B效果显著提升。说明SFT的作用,可能比RL更管用。考虑到技术报告只给了这一个和SFT,RL的ablation实验,而没有给出R1-zero和R1更详细的对比,这里面有猫腻的可能性非常大。
一些其他思考
- 奥卡姆剃刀!用第一性原理分析下,我倾向于相信,模型是用简单的方法做出来的,因为越复杂的Reward会导致模型朝着过拟合的方向发展,尤其是作者做了其他RL方法实验,MCTS和Process Reward都不work,更是说明了这点。但R1和R1-zero的Reward一定是不同的,因为,R1-zero没经过任何SFT冷启动,Format大概率是不对的,所以Format Reward的设计是合理的。但R1是有SFT冷启动的,Format出错概率很小。因此,可能R1的Reward是Align
<think>之外,还要求Align SFT结果的Format(比如分步作答,全面思考)。或者,R1的Reward干脆就没有Format Reward,能力都是SFT带来的。但我倾向于相信是有的,因为现有模型都没有Deepseek能力强,不可能凭空跑出来一批SFT数据。同时,R1的RL和SFT可能是同一批数据,这样能保证两者训练完是能对齐的。 - 社会工程学角度和贝叶斯概率:Deepseek说破大天就200多人做这件事,不可能比2000人团队做出来更多的实验,可能少一个人就能少10个消融实验,所以不太可能是特别复杂的方法。更可能是简单方法,但是做对了很多中间结果,汇总成了最终结果。
还有一些其他思考,等后面慢慢汇总下,再整理发出来。
PREVIOUS【Blog】2024大模型年终总结