李飞飞最新模型S1给我们哪些思考?
TLDR
论文:s1: Simple test-time scaling
在MATH和AIME24的Benchmark上,通过在1k数据上纯SFT with CoT trace带来了27%的提升。并且观测到了Test-time scaling现象。并且数据不能多了,如果把所有SFT with CoT Trace都用上,效果反而很差。
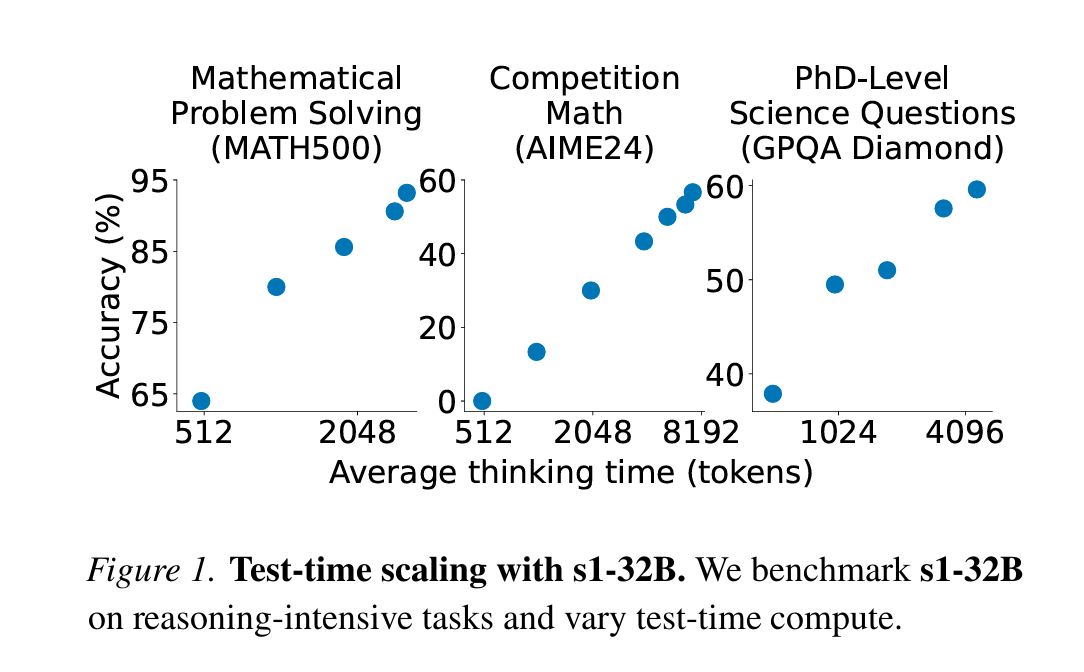
这进一步说明了RL和SFT with CoT trace在模型推理能力的提升上消融实验做的还不够,认知有待继续提升。
他们的目标是什么?
尝试通过一些手段实现Test time scaling。
他们做了什么
在Qwen2.5-32B-Instruct模型上,用1K根据规则筛选出的有CoT Trace的SFT数据进行SFT训练,并在Test time时候用了以下Decoding strategy
- 如果Thinking过长:在设定好的截断长度强行加入
Final Answer:,让模型结束思考开始回答; - 如果Thinking过短,改
Final Answer成Wait,让模型继续思考。
1K数据如何构造
- 59K初始数据构造:NuminaMATH(30k),AIME,Olympic Arena(4.2k),Omnimath(4.2k),AGIEval(2.3k),SAT。
- 构造数据的reasoning Trace:调用google Gemini Flash Thinking API。
- 过滤到1k数据
- Quality过滤:Format错误。
- Difficulty过滤:Gemini回答正确且Thinking length > 5600
- Diversity过滤:遍历所有domain,按照Thinking length倒排,并按照2的负倒数做weighted sampling(所以更倾向于Thinking比较长的)
结果如何
s1-32B已经远比原本的Instruct版本好了,虽然还是没有追上R1蒸馏出来的模型(which用了800k SFT数据)
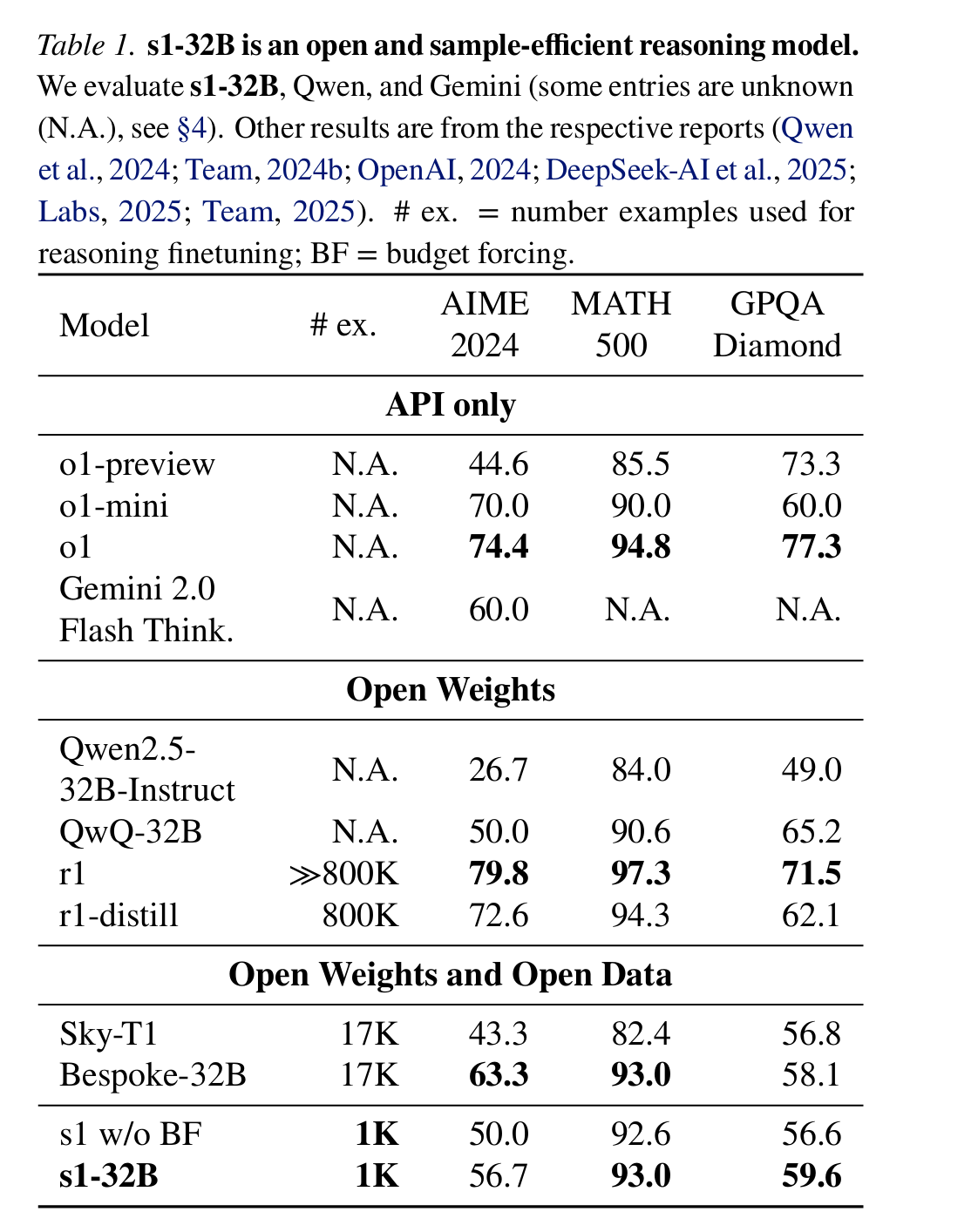
讨论
- SFT和RL分别的作用:在原始R1的paper里,Deepseek并没有提及SFT和RL分别给R1目前的能力带来的提升幅度,也没有讲最开始冷启动SFT后模型的各项指标参数,这个文章在该方向给出了一些insights,有一定参考价值。
- 还有另一篇重量级notion,讲了为什么可能R1根本没有Aha Moment,只是Base训练的好而已。这也是为什么只有在某些基座上能训练出来(比如Qwen),但是其他基座不行的原因,甚至和Size的关系都不大。
- 关注我,下一篇分析There May Not be Aha Moment in R1