Scala Basics
Learning Materials
- scala core
- scala spark unit test
- scala underscore explained: Scala中下划线“_”的用法小结 - 简书 (jianshu.com)
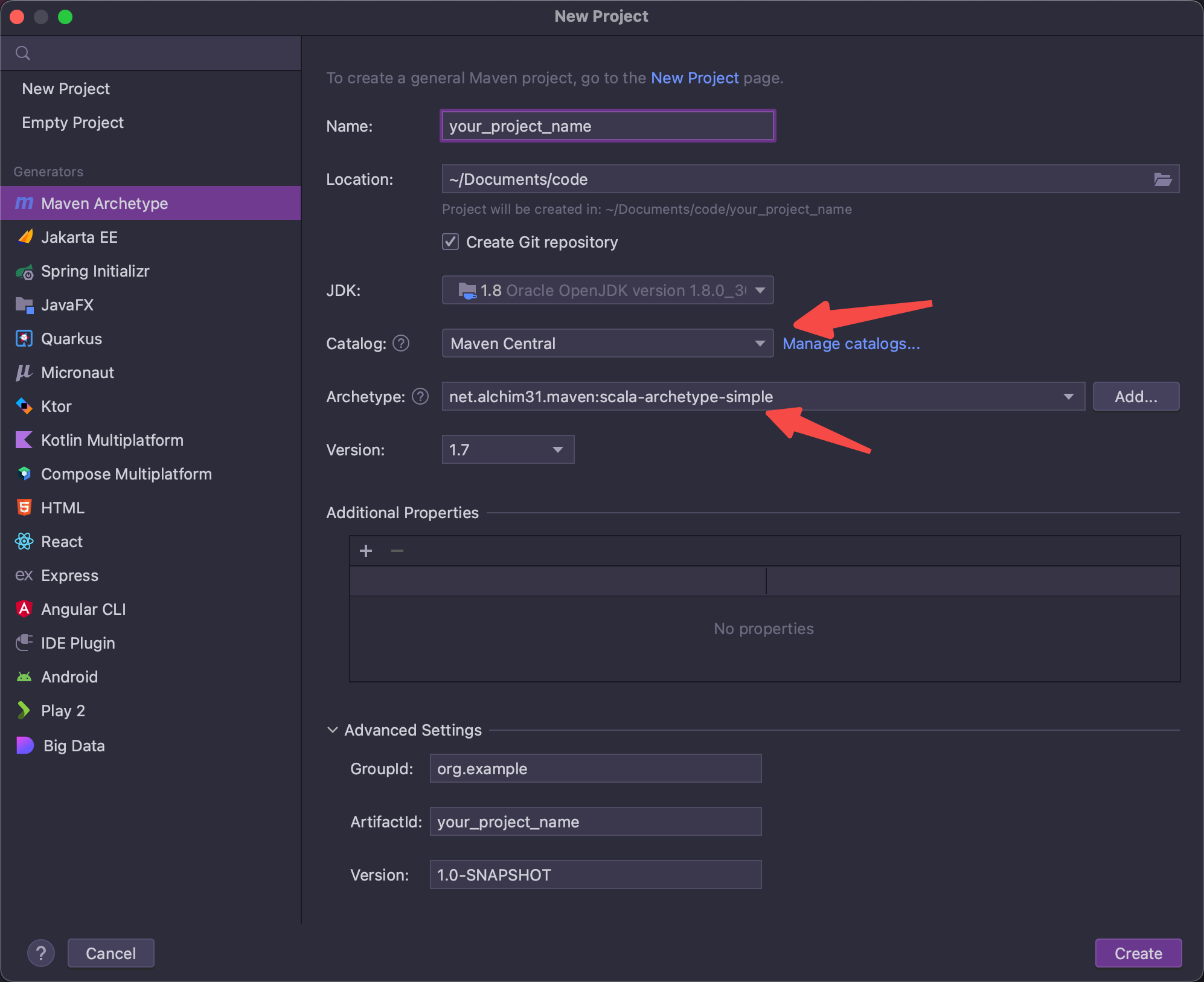
How to create a maven scala project
Using Idea
archetype
net.alchim31.maven:scala-archetype-simple
Project dependency
Reference
spark version v.s. scala version
Any version of Spark requries a specific version Scala. When you build an application to be written Scala, you want to make sure yourScala version is compatible with Spark version you have.
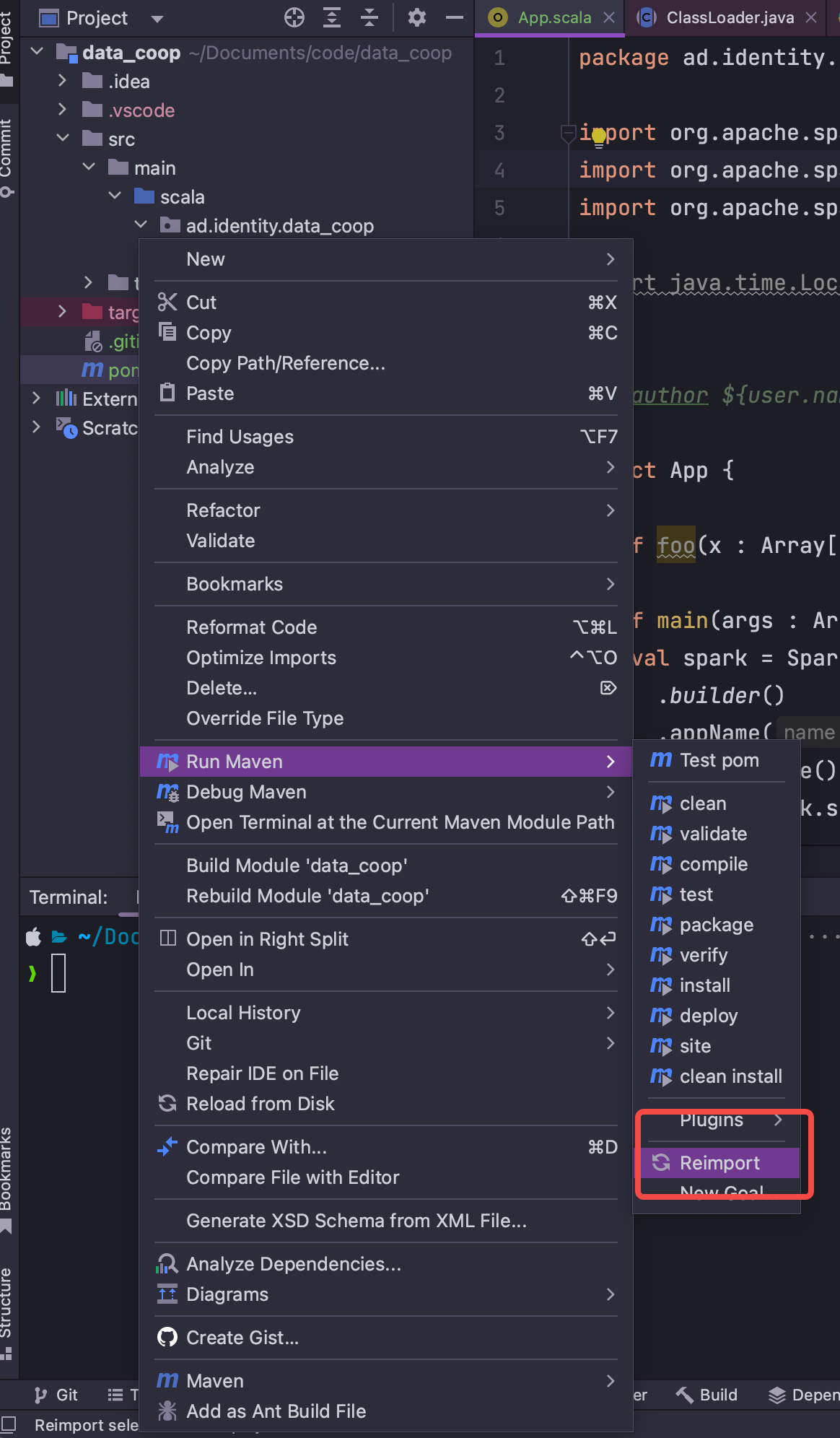
If you change the dependencies once and the IDE does not agree with what you just did. Right click on pom.xml and reimport the whole project. It should be working just fine.
Usages
- Merge two array list and deduplicate
def mergeSiloList(a: Array[(String, String, String)], b: Array[(String, String, String)]): Array[(String, String, String)] = {
val resultMap = scala.collection.mutable.Map[(String, String), String]()
for ((id, idType, belongsTo) <- a ++ b) {
val key = id -> belongsTo
if (!resultMap.contains(key)) {
resultMap.put(key, idType)
}
}
resultMap.toArray.map { case ((id, belongsTo), idType) => (id, idType, belongsTo) }
}
- Compare two lists
def compareTwoArray(a1: Array[(String, String, String)], a2: Array[(String, String, String)]): Array[(String, String, String)] = {
a1.filterNot(t1 => a2.exists(t2 => t1._1 == t2._1))
// another way
// attr.forall({case (id, _, _) => srcId != id})
}
- convert an array to a string
propertyList.foldLeft("")((acc, obj) => acc + s"(${obj._1}, ${obj._2}, ${obj._3})\t"))
-
Insert VertexRDD to hive
import org.apache.spark.sql.{Row, SparkSession} // Assuming sparkSession is already created // Convert the VertexRDD to a DataFrame val vertexRows = vertexRDD.map{ case (vid, vprop) => Row(vid, vprop.property1, vprop.property2, ...) } val vertexSchema = Seq("id", "property1", "property2", ...) val vertexDF = sparkSession.createDataFrame(vertexRows, vertexSchema) // Write the DataFrame to Hive vertexDF.write.mode("overwrite").saveAsTable("database.table_name")
PREVIOUS【Basics】Git Rebase